
¿Quiere cambiar el nombre de un conjunto completo de archivos a una secuencia numérica (1.pdf, 2.pdf, 3.pdf,…) en Linux? Esto se puede hacer con algunas secuencias de comandos ligeras y este post le mostrará cómo hacer exactamente eso.
Nombres de archivos numéricos
Por lo general, cuando escaneamos un archivo PDF con algún hardware (teléfono móvil, escáner de PDF dedicado), el nombre del archivo se leerá algo como 2020_11_28_13_43_00.pdf. Muchos otros sistemas semiautomáticos producen nombres de archivo similares basados en fecha y hora.
A veces, el archivo además puede contener el nombre de la aplicación que se está usando, o alguna otra información como, a modo de ejemplo, el DPI (puntos por pulgada) aplicable o el tamaño del papel escaneado.
Al recabar archivos PDF de diferentes fuentes, las convenciones de nomenclatura de archivos pueden diferir significativamente y puede ser bueno estandarizar en un nombre de archivo numérico (o numérico en parte).
Esto además se aplica a otros dominios y conjuntos de archivos. A modo de ejemplo, sus recetas o colección de fotos, muestras de datos generadas en sistemas de monitoreo automatizados, archivos de registro listos para archivar, un conjunto de archivos SQL para el ingeniero de bases de datos y, en general, cualquier dato recopilado de diferentes fuentes con diferentes esquemas de nombres.
Renombrar archivos a granel a nombres de archivo numéricos
En Linux, es fácil cambiar rápidamente el nombre de un conjunto completo de archivos con nombres de archivo totalmente diferentes, a una secuencia numérica. “Fácil” significa “fácil de ejecutar” aquí: el problema de cambiar el nombre de los archivos a números numéricos es complejo de codificar en sí mismo: la secuencia de comandos en línea a continuación tomó de 3 a 4 horas para investigar, crear y probar. Muchos otros comandos probados, todos tenían limitaciones que quería evitar.
Tenga en cuenta que no se otorgan ni proporcionan garantías, y este código se proporciona «tal cual». Haga su propia investigación antes de ejecutarlo. Una vez dicho esto, lo probé con éxito contra archivos con bastantes caracteres especiales, y además contra más de 50k archivos sin que se perdiera ningún archivo. Además revisé un archivo llamado 'a'$'n''a.pdf' que contiene una nueva línea.
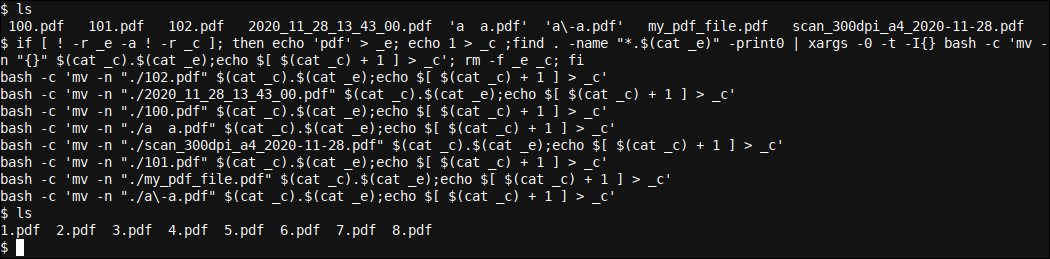
if [ ! -r _e -a ! -r _c ]; then echo 'pdf' > _e; echo 1 > _c ;find . -name "*.$(cat _e)" -print0 | xargs -0 -I{} bash -c 'mv -n "{}" $(cat _c).$(cat _e);echo $[ $(cat _c) + 1 ] > _c'; rm -f _e _c; fi
Primero veamos cómo funciona esto y posteriormente analicemos el comando. Hemos creado un directorio con ocho archivos, todos con nombres muy diferentes, excepto que su extensión coincide y es .pdf. A continuación, ejecutamos el comando anterior:

El resultado fue que los 8 archivos han sido renombrados a 1.pdf, 2.pdf, 3.pdf, etc., aún cuando sus nombres estaban bastante desplazados antes.
El comando asume que no tiene ninguna 1.pdf para x.pdf archivos con nombre aún. Si lo hace, puede mover esos archivos a un directorio separado, establezca el echo 1 a un número más alto para comenzar a renombrar los archivos restantes en un desplazamiento dado, y posteriormente fusionar los dos directorios juntos nuevamente.
Siempre tenga cuidado de no sobrescribir ningún archivo, y siempre es una buena idea realizar una copia de seguridad rápida antes de actualizar cualquier cosa.
Veamos el comando en detalle. Puede ayudar a ver lo que está sucediendo agregando el -t opción a xargs que nos posibilita ver lo que sucede detrás de escena:
Para comenzar, el comando utiliza dos pequeños archivos temporales (llamados _mi y _C) como almacenamiento temporal. Al comienzo del delineador, hace un verificación de seguridad usando un if declaración para garantizar que tanto _mi y _C los archivos no están presentes. Si hay un archivo con ese nombre, el script no continuará.
Sobre el tema del uso de pequeños archivos temporales versus variables, puedo decir que, aunque el uso de variables hubiera sido ideal (ahorra algunas E / S de disco), había dos problemas con los que me estaba encontrando.
La primera es que si EXPORTA una variable al comienzo del delineador y posteriormente utiliza esa misma variable más tarde, si otro script utiliza la misma variable (incluido este script que se ejecuta más de una vez simultáneamente en la misma máquina), entonces ese script, o éste, puede verse afectado. ¡Es mejor evitar tales interferencias cuando se trata de cambiar el nombre de muchos archivos!
El segundo fue que xargs en combinación con bash -c parece tener una limitación en el manejo de variables dentro del bash -c línea de comando. Inclusive una extensa investigación en línea no proporcionó una solución viable para esto. Por eso, terminé usando un archivo pequeño _C que mantienen el progreso.
_mi Es la extensión que buscaremos y usaremos, y _C es un contador que aumentará automáticamente con cada cambio de nombre. los echo $[ $(cat _c) + 1 ] > _c el código se encarga de esto, mostrando el archivo con cat, agregando un número y reescribiéndolo.
El comando además utiliza el mejor método factible para manejar caracteres especiales de nombre de archivo usando terminación nula en lugar de la terminación de nueva línea estándar, dicho de otra forma, la � personaje. Esto está asegurado por el -print0 opción a find, y por el -0 opción a xargs.
El comando de búsqueda buscará cualquier archivo con la extensión especificada en el _mi archivo (creado por el echo 'pdf' > _e mando. Puede variar esta extensión a cualquier otra extensión que desee, pero no le ponga un punto como prefijo. El punto ya está incluido en la última *.$(cat _e) -name especificador para find.
Una vez que encuentre, haya localizado todos los archivos y los haya enviado: � terminado a xargs, xargs cambiará el nombre de los archivos uno por uno usando el archivo de contador (_C) y el mismo archivo de extensión (_mi). Para obtener el contenido de los dos archivos, un simple cat se utiliza el comando, que se ejecuta desde dentro de una subcapa.
los mv mover usos del comando -n para evitar sobrescribir cualquier archivo ya presente. Por último limpiamos los dos archivos temporales eliminándolos.
Aunque el costo de utilizar dos archivos de estado y la bifurcación de subcapa puede ser limitado, esto agrega algo de sobrecarga al script, especialmente cuando se trata de una gran cantidad de archivos.
Hay todo tipo de otras soluciones para este mismo problema en línea, y muchas han intentado y no han logrado crear una solución que funcione plenamente. Muchas soluciones olvidaron todo tipo de casos secundarios, como utilizar ls sin especificar --color=never, lo que puede llevar a que se analicen códigos hexadecimales cuando se utilice la codificación de colores de listas de directorios.
A pesar de esto, otras soluciones omitieron el manejo de archivos con espacios, nuevas líneas y caracteres especiales como » correctamente. Para esto, la combinación find ... -print0 ... | xargs -0 ... es de forma general indicado e ideal (y tanto el hallar y xargs manuales aluden a este hecho con bastante fuerza).
Aunque no considero que mi implementación sea la respuesta perfecta o final, parece ser un avance significativo para muchas de las otras soluciones que existen, al utilizar find y � cadenas terminadas, asegurando máxima compatibilidad de nombre de archivo y análisis, al mismo tiempo de tener algunas otras sutilezas, como poder especificar un desplazamiento inicialy estar totalmente Nativo de Bash.
¡Disfrutar!





