Ordenar un archivo de registro por una columna específica es útil para hallar información rápidamente. Los registros de forma general se almacenan como texto sin formato, por lo que puede utilizar herramientas de manipulación de texto de línea de comando para procesarlos y verlos de una manera más legible.
Extraer columnas con cut y awk
los cut y awk Las utilidades son dos formas diferentes de extraer una columna de información de archivos de texto. Ambos asumen que sus archivos de registro están delimitados por espacios en blanco, a modo de ejemplo:
column column column
Esto presenta un obstáculo si los datos dentro de las columnas contienen espacios en blanco, como fechas («miércoles 12 de junio»). Tiempo cut puede ver esto como tres columnas separadas, aún puede extraer las tres al mismo tiempo, asumiendo que la estructura de su archivo de registro es consistente.
cut es muy simple de utilizar:
cat system.log | cut -d ' ' -f 1-6
los cat comando lee el contenido de system.log y lo canaliza a cut. los -d flag especifica el delimitador, para este caso un espacio en blanco. (El valor predeterminado es pestaña, t.) Los -f bandera especifica qué campos generar. Este comando imprimirá específicamente las primeras seis columnas de system.log. Si solo quisiera imprimir la tercera columna, usaría la -f 3 bandera.
awk es más poderoso pero no tan conciso. cut es útil para extraer columnas, como si quisiera obtener una lista de direcciones IP de sus registros de Apache. awk puede reorganizar líneas completas, lo que puede ser útil para ordenar un documento completo por una columna específica. awk es un lenguaje de programación completo, pero puede utilizar un comando simple para imprimir columnas:
cat system.log | awk '{print $1, $2}'awk ejecuta su comando para cada línea del archivo. De forma predeterminada, divide el archivo por espacios en blanco y almacena cada columna en variables $1, $2, $3, etcétera. Usando el print $1 comando, puede imprimir la primera columna, pero no hay una manera fácil de imprimir un rango de columnas sin utilizar bucles.
Un beneficio de awk es que el comando puede hacer referencia a toda la línea al mismo tiempo. El contenido de la línea se almacena en variable $0, que puede usar para imprimir toda la línea. Entonces, podría, a modo de ejemplo, imprimir la tercera columna antes de imprimir el resto de la línea:
awk '{print $3 " " $0}'los " " imprime un espacio entre $3 y $0. Este comando repite la columna tres dos veces, pero puede solucionarlo configurando el $3 variable a nula:
awk '{printf $3; $3=""; print " " $0}'los printf El comando no imprime una nueva línea. De la misma forma, puede excluir columnas específicas de la salida configurándolas todas en cadenas vacías antes de imprimir $0:
awk '{$1=$2=$3=""; print $0}'Puedes hacer mucho más con awk, incluyendo coincidencia de expresiones regulares, pero la extracción de columnas lista para utilizar funciona bien para este caso de uso.
Ordenar columnas con sort y uniq
los sort El comando se puede usar para ordenar una lista de datos basada en una columna específica. La sintaxis es:
sort -k 1
donde el -k bandera denota el número de columna. Usted canaliza la entrada a este comando y escupe una lista ordenada. Por defecto, sort utiliza el orden alfabético pero admite más opciones a través de banderas, como -n para clasificación numérica, -h para la ordenación de sufijos (1M> 1K), -M para categorizar las abreviaturas de los meses, y -V para ordenar los números de versión de archivo (archivo-1.2.3> archivo-1.2.1).
los uniq El comando filtra las líneas duplicadas, dejando solo las únicas. Solo funciona para líneas adyacentes (por razones de rendimiento), por lo que deberá usarlo siempre después sort para quitar duplicados en todo el archivo. La sintaxis es simplemente:
sort -k 1 | uniq
Si solo desea enumerar los duplicados, use el -d bandera.
uniq además puede contar el número de duplicados con el -c bandera, lo que lo hace muy bueno para el seguimiento de la frecuencia. A modo de ejemplo, si desea obtener una lista de las principales direcciones IP que llegan a su servidor Apache, puede ejecutar el siguiente comando en su access.log:
cut -d ' ' -f 1 | sort | uniq -c | sort -nr | head
Esta cadena de comandos recortará la columna de la dirección IP, agrupará los duplicados, eliminará los duplicados mientras cuenta cada ocurrencia, posteriormente ordenará según la columna de recuento en orden numérico descendente, dejándolo con una lista que se ve así:
21 192.168.1.1 12 10.0.0.1 5 1.1.1.1 2 8.0.0.8
Puede aplicar estas mismas técnicas a sus archivos de registro, al mismo tiempo de otras utilidades como awk y sed, para extraer información útil. Estos comandos encadenados son largos, pero no es necesario que los escriba todo el tiempo, puesto que siempre puede almacenarlos en un script bash o alias a través de su ~/.bashrc.
Filtrado de datos con grep y awk
grep es un comando muy simple; le da una definición de búsqueda y le pasa la entrada, y escupirá cada línea que contenga ese término de búsqueda. A modo de ejemplo, si desea buscar errores 404 en el registro de acceso de Apache, puede hacer lo siguiente:
cat access.log | grep "404"
que escupiría una lista de entradas de registro que coincidan con el texto dado.
A pesar de esto, grep no puede limitar su búsqueda a una columna específica, por lo que este comando fallará si tiene el texto «404» en cualquier otro lugar del archivo. Si solo desea buscar en la columna del código de estado HTTP, deberá utilizar awk:
cat access.log | awk '{if ($9 == "404") print $0;}'Con awk, además tiene la ventaja de poder realizar búsquedas negativas. A modo de ejemplo, puede buscar todas las entradas de registro que no lo hice volver con el código de estado 200 (OK):
cat access.log | awk '{if ($9 != "200") print $0;}'al mismo tiempo de tener acceso a todas las funciones programáticas awk proporciona.
Opciones de GUI para registros web
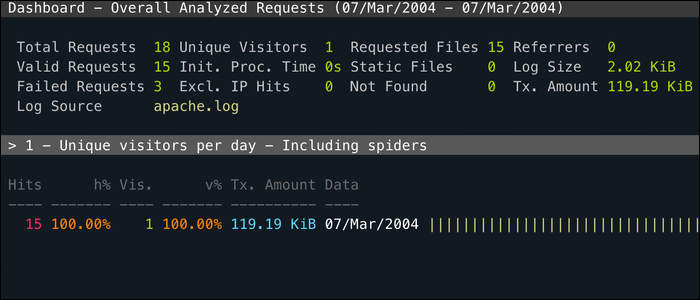
GoAccess es una utilidad CLI para monitorear el registro de acceso de su servidor web en tiempo real y clasifica por cada campo útil. Se ejecuta totalmente en su terminal, por lo que puede usarlo a través de SSH, pero además cuenta con una interfaz web mucho más intuitiva.
apachetop es otra utilidad específica para apache, que se puede utilizar para filtrar y ordenar por columnas en su registro de acceso. Se ejecuta en tiempo real de forma directa en su access.log.





