
El Linux grep El comando es una utilidad de coincidencia de cadenas y patrones que muestra las líneas coincidentes de varios archivos. Además funciona con salida canalizada de otros comandos. Te mostramos cómo.
La historia detrás de grep
los grep El comando es famoso en Linux y Unix círculos por tres razones. En primer lugar, es tremendamente útil. En segundo lugar, el la gran cantidad de opciones puede ser abrumadora. En tercer lugar, se escribió de la noche a la mañana para satisfacer una necesidad particular. Los dos primeros están muy bien; el tercero está ligeramente apagado.
Ken Thompson había extraído el expresión regular capacidades de búsqueda del ed editor (pronunciado ee-dee) y creó un pequeño programa, para su propio uso, para buscar en archivos de texto. Su jefe de departamento en Laboratorios Bell, Doug Mcilroy, se acercó a Thompson y describió el problema a uno de sus colegas, Lee McMahon, estaba enfrentando.
McMahon estaba tratando de identificar a los autores de la Papeles Federalistas a través del análisis textual. Necesitaba una herramienta que pudiera buscar frases y cadenas en archivos de texto. Thompson dedicó aproximadamente una hora esa noche a hacer de su herramienta una utilidad general que pudieran utilizar otros y la renombró como grep. Tomó el nombre del ed cadena de comando g/re/p , que se traduce como «búsqueda global de expresiones regulares».
Puedes ver a Thompson hablando para Brian Kernighan sobre el nacimiento de grep.
Búsquedas simples con grep
Para buscar una cadena dentro de un archivo, pase el término de búsqueda y el nombre del archivo en la línea de comando:

Se muestran las líneas coincidentes. Para este caso, es una sola línea. El texto coincidente está resaltado. Esto se debe a que en la mayoría de las distribuciones grep tiene un alias para:
alias grep='grep --colour=auto'
Veamos los resultados en los que hay varias líneas que coinciden. Buscaremos la palabra «Promedio» en un archivo de registro de la aplicación. Debido a que no podemos recordar si la palabra está en minúsculas en el archivo de registro, usaremos el -i (ignorar mayúsculas y minúsculas) opción:
grep -i Average geek-1.log

Se muestran todas las líneas coincidentes, con el texto coincidente resaltado en cada una.
Podemos mostrar las líneas que no coinciden usando la opción -v (coincidencia invertida).
grep -v Mem geek-1.log

No hay resaltado debido a que estas son las líneas que no coinciden.
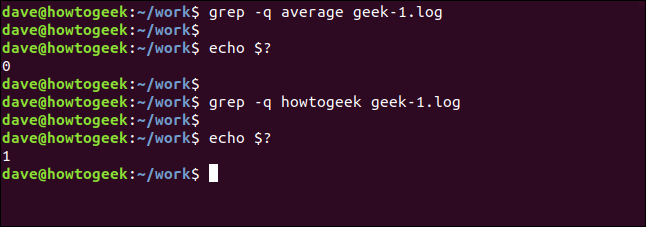
Podemos causar grep estar totalmente en silencio. El resultado se pasa al shell como un valor de retorno de grep. Un resultado de cero significa la cadena era encontrado, y un resultado de uno significa que no estaba fundar. Podemos verificar el código de retorno usando el $? parámetros especiales:
grep -q average geek-1.log
echo $?
grep -q systempeaker geek-1.log
echo $?
Búsquedas recursivas con grep
Para buscar en directorios y subdirectorios anidados, use la opción -r (recursiva). Tenga en cuenta que no proporciona un nombre de archivo en la línea de comando, debe proporcionar una ruta. Aquí estamos buscando en el directorio actual «.» y cualquier subdirectorio:
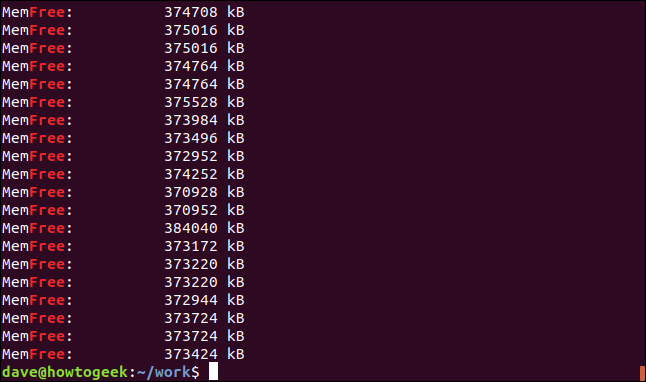
grep -r -i memfree .

La salida incluye el directorio y el nombre de archivo de cada línea coincidente.
Podemos hacer grep seguir links simbólicos usando el -R (desreferencia recursiva) opción. Tenemos un link simbólico en este directorio, llamado logs-folder. Apunta a /home/dave/logs.
ls -l logs-folder

Repitamos nuestra última búsqueda con el -R (desreferencia recursiva) opción:
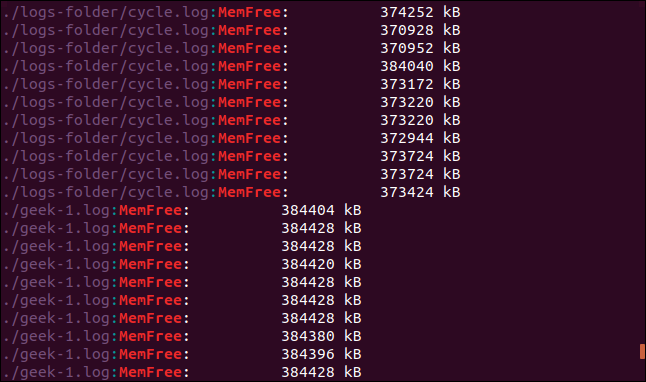
grep -R -i memfree .

Se sigue el link simbólico y se busca en el directorio al que apunta. grep además.
Buscando palabras completas
Por defecto, grep coincidirá con una línea si el objetivo de búsqueda aparece en cualquier lugar de esa línea, inclusive dentro de otra cadena. Mira este ejemplo. Vamos a buscar la palabra «gratis».
grep -i free geek-1.log

Los resultados son líneas que disponen la cadena «libre» en ellas, pero no son palabras separadas. Forman parte de la cadena «MemFree».
Para forzar grep para hacer coincidir solo «palabras» separadas, utilice el -w (palabra regexp) opción.
grep -w -i free geek-1.log
echo $?
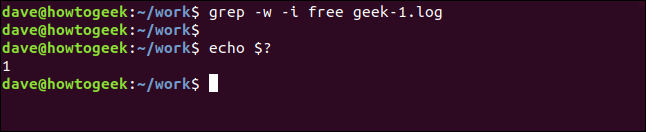
Esta vez no hay resultados debido a que el término de búsqueda «gratis» no aparece en el archivo como una palabra separada.
Uso de varios términos de búsqueda
los -E (expresión regular extendida) le posibilita buscar varias palabras. (Los -E opción reemplaza el obsoleto egrep versión de grep.)
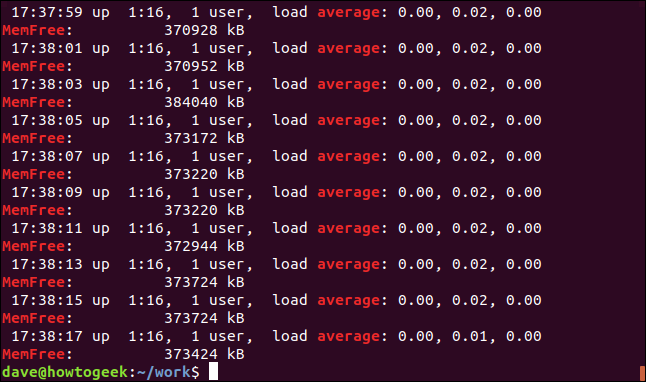
Este comando busca dos términos de búsqueda, «promedio» y «memfree».
grep -E -w -i "average|memfree" geek-1.log

Todas las líneas coincidentes se muestran para cada uno de los términos de búsqueda.
Además puede buscar varios términos que no son necesariamente palabras completas, pero además pueden ser palabras completas.
los -e La opción (patrones) le posibilita usar varios términos de búsqueda en la línea de comandos. Estamos usando la función de corchetes de expresiones regulares para crear un patrón de búsqueda. Dice grep para que coincida con cualquiera de los caracteres incluidos entre corchetes «[]. » Esto significa grep coincidirá con “kB” o “KB” mientras busca.

Ambas cadenas coinciden y, en realidad, algunas líneas contienen ambas cadenas.
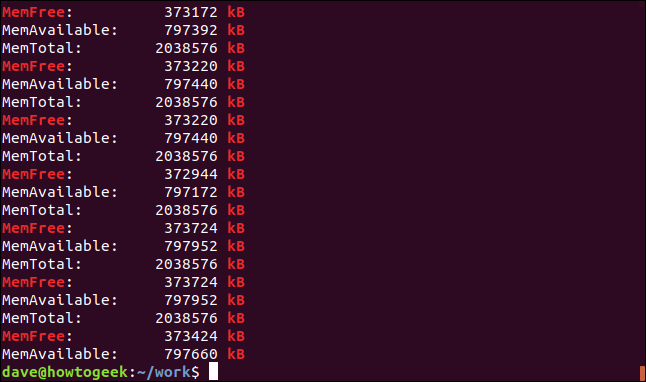
Coincidencia exacta de líneas
los -x (regexp de línea) solo coincidirá con las líneas donde el línea completa coincide con el término de búsqueda. Busquemos una marca de fecha y hora que sabemos que aparece solo una vez en el archivo de registro:
grep -x "20-Jan--06 15:24:35" geek-1.log

La única línea que coincide se encuentra y se muestra.
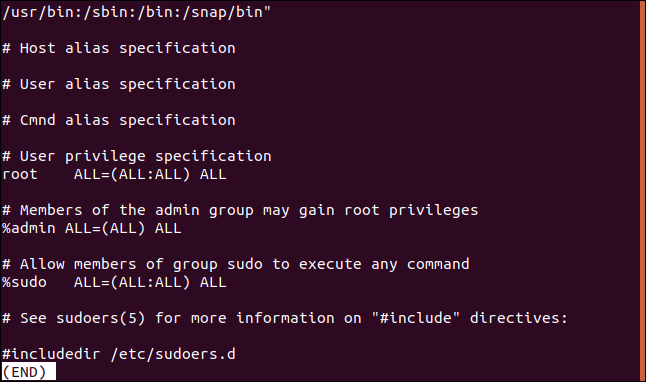
Lo contrario de eso es solo mostrar las líneas que no fósforo. Esto puede ser útil cuando busca archivos de configuración. Los comentarios son geniales, pero de vez en cuando es difícil identificar la configuración real entre todos ellos. Aquí esta la /etc/sudoers expediente:
Podemos filtrar efectivamente las líneas de comentarios de esta manera:
sudo grep -v "#" /etc/sudoers
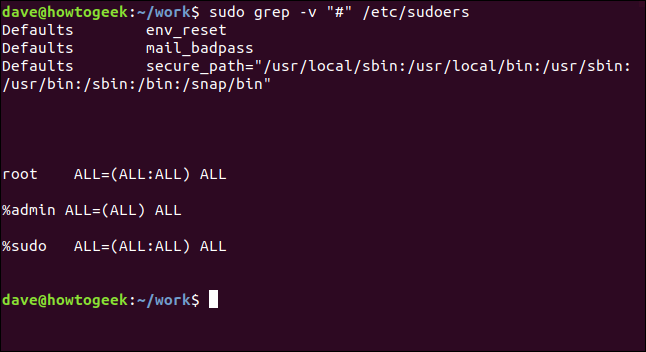
Eso es mucho más fácil de analizar.
Visualización únicamente de texto coincidente
Puede haber una ocasión en la que no desee ver toda la línea coincidente, solo el texto coincidente. los -o La opción (única coincidencia) hace exactamente eso.
grep -o MemFree geek-1.log

La pantalla se reduce a mostrar solo el texto que coincide con el término de búsqueda, en lugar de toda la línea coincidente.

Contando con grep
grep no se trata solo de texto, además puede proporcionar información numérica. Podemos hacer grep cuenta para nosotros de diferentes maneras. Si queremos saber cuántas veces aparece una definición de búsqueda en un archivo, podemos utilizar el -c (recuento) opción.
grep -c average geek-1.log

grep informa que el término de búsqueda aparece 240 veces en este archivo.
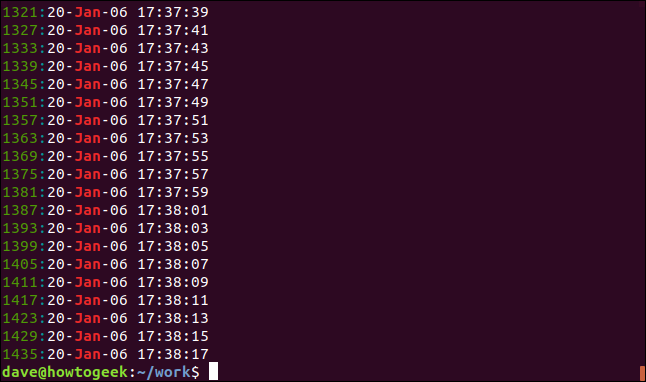
Puedes hacer grep mostrar el número de línea para cada línea coincidente usando el -n opción (número de línea).
grep -n Jan geek-1.log

El número de línea para cada línea coincidente se muestra al principio de la línea.
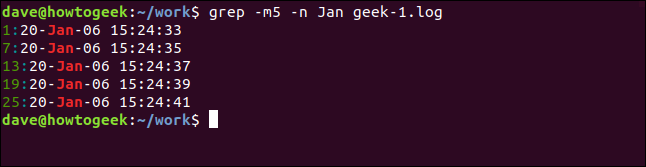
Para reducir el número de resultados que se muestran, utilice el -m (recuento máximo) opción. Vamos a limitar la salida a cinco líneas coincidentes:
grep -m5 -n Jan geek-1.log
Agregar contexto
A menudo es útil poder ver algunas líneas adicionales, posiblemente líneas que no coinciden, para cada línea coincidente. puede ayudar a distinguir cuáles de las líneas coincidentes son las que le interesan.
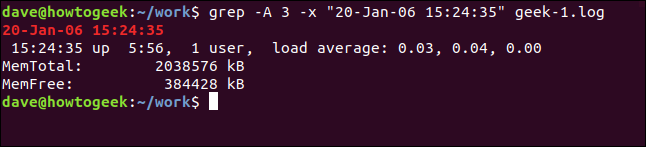
Para mostrar algunas líneas después de la línea coincidente, use la opción -A (después del contexto). Estamos solicitando tres líneas en este ejemplo:
grep -A 3 -x "20-Jan-06 15:24:35" geek-1.log
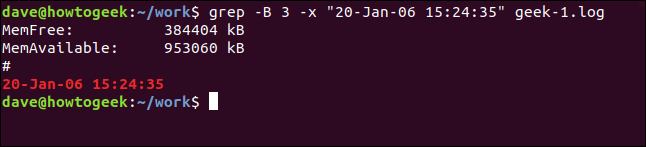
Para ver algunas líneas antes de la línea coincidente, use el -B (contexto antes) opción.
grep -B 3 -x "20-Jan-06 15:24:35" geek-1.log
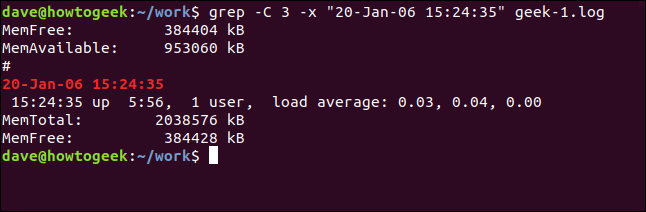
Y para incluir líneas antes y después de la línea coincidente, use el -C (contexto) opción.
grep -C 3 -x "20-Jan-06 15:24:35" geek-1.log
Mostrar archivos coincidentes
Para ver los nombres de los archivos que contienen el término de búsqueda, utilice la -l (archivos con coincidencia) opción. Para averiguar qué archivos de código fuente C contienen referencias al sl.h archivo de encabezado, use este comando:
grep -l "sl.h" *.c

Se enumeran los nombres de los archivos, no las líneas coincidentes.
Y, decididamente, podemos buscar archivos que no contengan el término de búsqueda. los -L La opción (archivos sin coincidencia) hace exactamente eso.
grep -L "sl.h" *.c

Inicio y final de líneas
Podemos forzar grep para mostrar solo las coincidencias que están al principio o al final de una línea. El operador de expresión regular “^” coincide con el comienzo de una línea. Prácticamente todas las líneas dentro del archivo de registro contendrán espacios, pero buscaremos líneas que tengan un espacio como primer carácter:
grep "^ " geek-1.log

Se muestran las líneas que disponen un espacio como primer carácter, al comienzo de la línea.
Para hacer coincidir el final de la línea, use el operador de expresión regular «$». Vamos a buscar líneas que terminen con «00».
grep "00$" geek-1.log

La pantalla muestra las líneas que disponen «00» como caracteres finales.
Usando Pipes con grep
Decididamente, puede canalizar la entrada a grep , canalice la salida de grep en otro programa y tener grep acurrucado en medio de una cadena de tuberías.
Digamos que queremos ver todas las apariciones de la cadena «ExtractParameters» en nuestros archivos de código fuente C. Sabemos que habrá bastantes, por lo que canalizamos la salida a less:
grep "ExtractParameters" *.c | less

La salida se presenta en less.
Esto le posibilita hojear la lista de archivos y usar less's facilidad de búsqueda.
Si canalizamos la salida de grep dentro wc y utiliza el -l (líneas) opción, nosotros puede contar el número de líneas en los archivos de código fuente que contienen «ExtractParameters». (Podríamos lograr esto usando el grep -c (recuento) opción, pero esta es una buena manera de demostrar la tubería fuera de grep.)
grep "ExtractParameters" *.c | wc -l

Con el siguiente comando, estamos canalizando la salida de ls dentro grep y canalizando la salida de grep dentro sort . Estamos enumerando los archivos en el directorio actual, seleccionando aquellos con la cadena «Aug» en ellos, y ordenándolos por tamaño de archivo:
ls -l | grep "Aug" | sort +4n
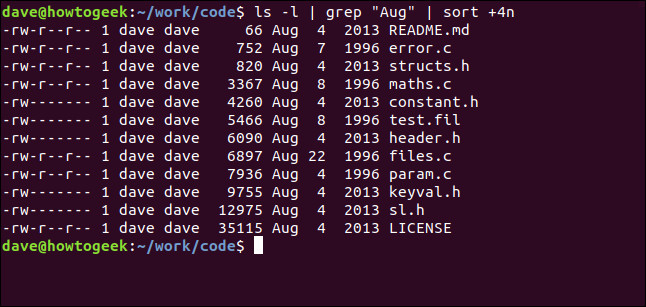
Analicemos eso:
- ls -l: Realiza una lista de formato larga de los archivos usando
ls. - grep «agosto»: Seleccione las líneas de la
lslistado que tiene «Aug» en ellos. Tenga en cuenta que esto además encontrará archivos que tengan «Aug» en sus nombres. - ordenar + 4n: Ordene la salida de grep en la cuarta columna ().
Obtenemos una lista ordenada de todos los archivos modificados en agosto (independientemente del año), en orden ascendente de tamaño de archivo.
RELACIONADO: Cómo utilizar Pipes en Linux
grep: Menos un comando, más un aliado
grep es una magnífica herramienta para tener a su disposición. Data de 1974 y aún se mantiene fuerte debido a que necesitamos lo que hace, y nada lo hace mejor.
Acoplamiento grep con algunas expresiones regulares, fu verdaderamente lo lleva al siguiente nivel.
RELACIONADO: Cómo usar expresiones regulares básicas para buscar mejor y ahorrar tiempo





