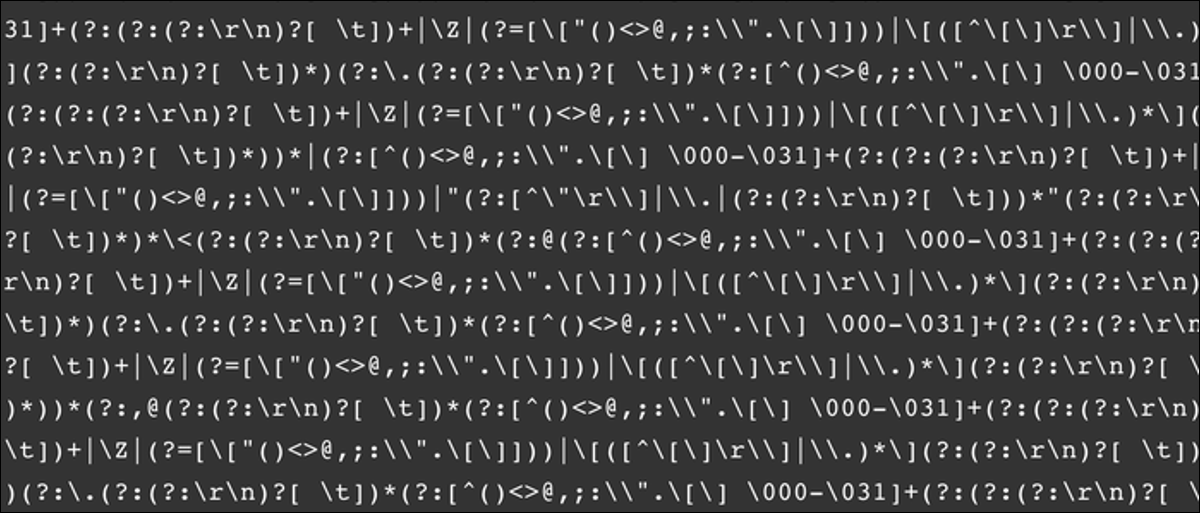
Regex, abreviatura de expresión regular, se utiliza a menudo en lenguajes de programación para hacer coincidir patrones en cadenas, buscar y reemplazar, validación de entrada y reformatear texto. Aprender a utilizar correctamente Regex puede hacer que trabajar con texto sea mucho más fácil.
Sintaxis de expresiones regulares, explicada
Regex tiene la fama de tener una sintaxis horrible, pero es mucho más fácil de escribir que de leer. A modo de ejemplo, aquí hay una expresión regular general para un validador de correo electrónico compatible con RFC 5322:
(?:[a-z0-9!#$%&'*+/=?^_`~-]+(?:.[a-z0-9!#$%&'*+/=?^_`~-]+)*|"(?:[x01-
x08x0bx0cx0e-x1fx21x23-x5bx5d-x7f]|[x01-x09x0bx0cx0e-x7f])*")
@(?:(?:[a-z0-9](?:[a-z0-9-]*[a-z0-9])?.)+[a-z0-9](?:[a-z0-9-]*[a-z0-9])?|[(?
:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?).){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-
9][0-9]?|[a-z0-9-]*[a-z0-9]:(?:[x01-x08x0bx0cx0e-x1fx21-x5ax53-x7f]|
[x01-x09x0bx0cx0e-x7f])+)])
Si parece que alguien se golpeó la cara contra el teclado, no estás solo. Pero bajo el capó, todo este lío en realidad está programando un máquina de estados finitos. Esta máquina se ejecuta para cada personaje, avanzando y combinando según las reglas que ha establecido. Muchas herramientas en línea renderizarán diagramas de ferrocarril, mostrando cómo funciona su máquina Regex. Aquí está la misma expresión regular en forma visual:
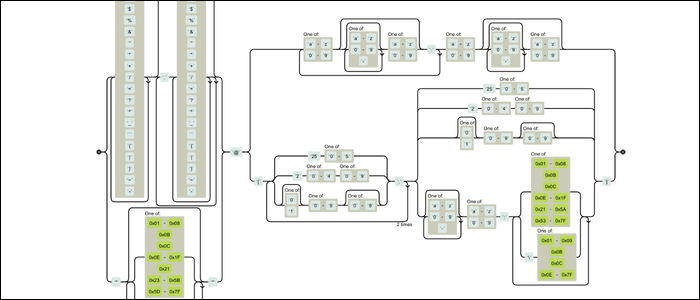
Sigue siendo muy confuso, pero es mucho más comprensible. Es una máquina con partes móviles que disponen reglas que definen cómo encaja todo. Puedes ver cómo alguien ensambló esto; no es solo una gran cantidad de texto.
Primero: use un depurador de expresiones regulares
Antes de comenzar, a menos que su Regex sea concretamente corto o usted sea concretamente competente, debe utilizar un depurador en línea al escribirlo y probarlo. Facilita mucho la comprensión de la sintaxis. Nosotros sugerimos Regex101 y RegExr, que ofrecen pruebas y referencia de sintaxis incorporada.
¿Cómo funciona Regex?
Por ahora, centrémonos en algo mucho más sencillo. Este es un diagrama de Regulex para una expresión regular de correspondencia de email muy corta (y definitivamente no compatible con RFC 5322):

El motor Regex comienza a la izquierda y viaja por las líneas, haciendo coincidir los caracteres a medida que avanza. El grupo # 1 coincide con cualquier carácter excepto un salto de línea, y continuará haciendo coincidir caracteres hasta que el siguiente bloque encuentre una coincidencia. Para este caso, se detiene cuando cumple un @ símbolo, que significa que el Grupo # 1 captura el nombre de la dirección de email y todo lo que sigue coincide con el dominio.
La expresión regular que establece el Grupo # 1 en nuestro ejemplo de email es:
(.+)
Los paréntesis definen un grupo de captura, que le dice al motor Regex que incluya el contenido de la coincidencia de este grupo en una variable especial. Cuando ejecuta una expresión regular en una cadena, el resultado predeterminado es la coincidencia completa (para este caso, todo el email). Pero además devuelve cada grupo de captura, lo que hace que esta expresión regular sea útil para extraer nombres de los correos electrónicos.
El punto es el símbolo de «Cualquier carácter excepto nueva línea». Esto coincide con todo en una línea, por lo que si pasó este email Regex una dirección como:
%$#^&%*#%$#^@gmail.com
Coincidiría %$#^&%*#%$#^ como el nombre, aún cuando eso es ridículo.
El símbolo más (+) es una estructura de control que significa «coincidir con el carácter o grupo anterior una o más veces». Asegura que todo el nombre coincida, y no solo el primer carácter. Esto es lo que crea el bucle que se encuentra en el diagrama del ferrocarril.
El resto de Regex es bastante simple de descifrar:
(.+)@(.+..+)
El primer grupo se detiene cuando golpea el @ símbolo. Posteriormente comienza el siguiente grupo, que nuevamente coincide con bastantes caracteres hasta que cumple un carácter de punto.
Debido a que los caracteres como puntos, paréntesis y barras se usan como parte de la sintaxis en Regrex, siempre que desee hacer coincidir esos caracteres, debe escapar correctamente con una barra invertida. En este ejemplo, para que coincida con el período, escribimos . y el analizador lo trata como un símbolo que significa «coincidir con un punto».
Coincidencia de personajes
Si tiene caracteres sin control en su Regex, el motor Regex asumirá que esos caracteres formarán un bloque coincidente. A modo de ejemplo, Regex:
he+llo
Coincidirá con la palabra «hola» con cualquier número de e. Es necesario escapar de cualquier otro personaje para que funcione correctamente.
Regex además tiene clases de caracteres, que actúan como abreviatura de un conjunto de caracteres. Estos pueden variar según la implementación de Regex, pero estos pocos son estándar:
.– coincide con cualquier cosa excepto con nueva línea.w– coincide con cualquier carácter de «palabra», incluidos dígitos y guiones bajos.d– coincide con los números.b– coincide con caracteres de espacio en blanco (dicho de otra forma, espacio, tabulación, nueva línea).
Estos tres disponen contrapartes en mayúsculas que invierten su función. A modo de ejemplo, D coincide con cualquier cosa que no sea un número.
Regex además tiene juego de caracteres. A modo de ejemplo:
[abc]
Coincidirá con cualquiera a, b, o c. Esto actúa como un bloque y los corchetes son solo estructuras de control. Alternativamente, puede especificar un rango de caracteres:
[a-c]
O niegue el conjunto, que coincidirá con cualquier personaje que no esté en el conjunto:
[^a-c]
Cuantificadores
Los cuantificadores son una parte importante de Regex. Te posibilitan emparejar cadenas donde no conoces el exacto formato, pero tienes una idea bastante buena.
los + El operador del ejemplo de email es un cuantificador, específicamente el cuantificador «uno o más». Si no sabemos cuánto mide una determinada cadena, pero sabemos que está formada por caracteres alfanuméricos (y no está vacía), podemos escribir:
w+
Al mismo tiempo de +, además hay:
- los
*operador, que coincide con «cero o más». Esencialmente lo mismo que+, excepto que tiene la opción de no hallar una coincidencia. - los
?operador, que coincide con «cero o uno». Tiene el efecto de hacer que un personaje sea opcional; o está ahí o no lo está, y no coincidirá más de una vez. - Cuantificadores numéricos. Estos pueden ser un solo número como
{3}, que significa «exactamente 3 veces» o un rango como{3-6}. Puede omitir el segundo número para que sea ilimitado. A modo de ejemplo,{3,}significa «3 o más veces». Curiosamente, no puede omitir el primer número, por lo que si desea «3 veces o menos», tendrá que utilizar un rango.
Cuantificadores codiciosos y perezosos
Debajo del capó, el * y + los operadores son avaro. Coincide tanto como sea factible y devuelve lo que se necesita para comenzar el siguiente bloque. Este puede ser un obstáculo enorme.
Aquí hay un ejemplo: digamos que está tratando de hacer coincidir HTML o cualquier otra cosa con llaves de cierre. Su texto de entrada es:
<div>Hello World</div>
Y desea hacer coincidir todo lo que está dentro de los corchetes. Puede escribir algo como:
<.*>
Esta es la idea correcta, pero falla por un motivo crucial: el motor Regex coincide “div>Hello World</div>«Para la secuencia .*, y después retrocede hasta que el siguiente bloque coincida, para este caso, con un corchete de cierre (>). Es de esperar que retroceda solo para coincidir «div“, Y después repita de nuevo para que coincida con el div de cierre. Pero el backtracker corre desde el final de la cadena y se detendrá en el corchete final, que termina haciendo coincidir todo lo que está dentro de los corchetes.
La respuesta es hacer que nuestro cuantificador sea perezoso, lo que significa que coincidirá con la menor cantidad de caracteres factible. Debajo del capó, esto en realidad solo coincidirá con un carácter, y después se expandirá para llenar el espacio hasta la próxima coincidencia de bloque, lo que lo hace mucho más eficaz en operaciones grandes de Regex.
Hacer que un cuantificador sea perezoso se hace agregando un signo de interrogación de forma directa después del cuantificador. Esto es un poco confuso debido a que ? ya es un cuantificador (y en realidad es codicioso por defecto). Para nuestro ejemplo de HTML, la expresión regular se corrige con esta simple adición:
<.*?>
El operador perezoso se puede agregar a cualquier cuantificador, incluido +?, {0,3}?, e inclusive ??. Aún cuando el último no tiene ningún efecto; debido a que está haciendo coincidir cero o un carácter de todos modos, no hay espacio para expandir.
Agrupación y Lookarounds
Los grupos en Regex disponen muchos propósitos. En un nivel básico, unen varias fichas en un bloque. A modo de ejemplo, puede crear un grupo y después utilizar un cuantificador en todo el grupo:
ba(na)+
Esto agrupa la «na» repetida para que coincida con la frase banana, y banananana, etcétera. Sin el grupo, el motor Regex simplemente coincidiría con el carácter final una y otra vez.
Este tipo de grupo con dos paréntesis simples se denomina grupo de captura y lo incluirá en la salida:
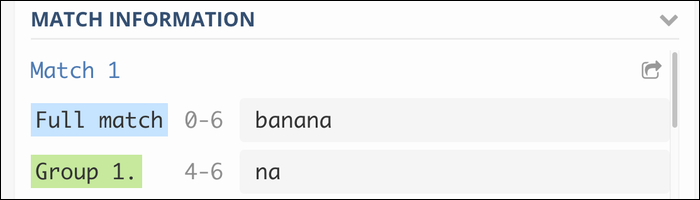
Si desea evitar esto y simplemente agrupar los tokens por motivos de ejecución, puede utilizar un grupo que no captura:
ba(?:na)
El signo de interrogación (un carácter reservado) establece un grupo no estándar y el siguiente carácter establece qué tipo de grupo es. Comenzar grupos con un signo de interrogación es ideal, debido a que caso contrario, si quisiera hacer coincidir puntos y comas en un grupo, necesitaría escapar de ellos sin una buena razón. Pero tu siempre tiene que escapar de los signos de interrogación en Regex.
Además puede nombrar sus grupos, por conveniencia, cuando trabaje con la salida:
(?'group')
Puede hacer referencia a estos en su Regex, lo que los hace funcionar de manera equivalente a las variables. Puede hacer referencia a grupos sin nombre con el token 1, pero esto solo sube a 7, después de lo cual deberá comenzar a nombrar grupos. La sintaxis para hacer referencia a grupos con nombre es:
k{group}
Esto hace referencia a los resultados del grupo nombrado, que puede ser dinámico. Esencialmente, verifica si el grupo ocurre varias veces pero no le importa la posición. A modo de ejemplo, esto se puede utilizar para hacer coincidir todo el texto entre tres palabras idénticas:
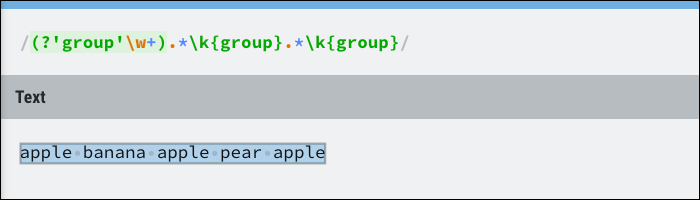
La clase de grupo es donde encontrará la mayor parte de la estructura de control de Regex, incluidas las búsquedas anticipadas. Lookaheads aseguran que una expresión debe coincidir pero no la incluye en el resultado. En cierto modo, es equivalente a una instrucción if y no coincidirá si devuelve falso.
La sintaxis para una búsqueda anticipada positiva es (?=). He aquí un ejemplo:
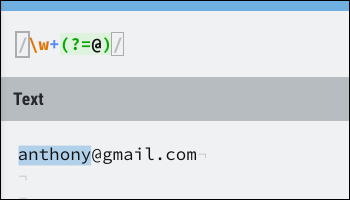
Esto coincide con la parte del nombre de una dirección de email muy limpiamente, deteniendo la ejecución en la división @. Las búsquedas anticipadas no consumen ningún carácter, por lo que si desea continuar ejecutándose después de que una búsqueda anticipada tenga éxito, aún puede hacer coincidir el carácter utilizado en la búsqueda anticipada.
Al mismo tiempo de los lookaheads positivos, además hay:
(?!)– Lookaheads negativos, que aseguran una expresión. no fósforo.(?<=)– Lookbehinds positivos, que no se admiten en todas partes debido a algunas limitaciones técnicas. Estos se colocan antes de la expresión que desea hacer coincidir y deben tener un ancho fijo (dicho de otra forma, sin cuantificadores excepto{number}. En este ejemplo, podría utilizar(?<=@)w+.w+para que coincida con la parte del dominio del email.(?<!)– Miradas atrás negativas, que son iguales a las miradas atrás positivas, pero negadas.
Diferencias entre motores Regex
No todas las expresiones regulares son iguales. La mayoría de los motores Regex no siguen ningún estándar específico, y algunos cambian un poco las cosas para adaptarse a su idioma. Es factible que algunas características que funcionan en un idioma no funcionen en otro.
A modo de ejemplo, las versiones de sed compilado para macOS y FreeBSD no admite el uso t para representar un carácter de tabulación. Debe copiar manualmente un carácter de tabulación y pegarlo en el terminal para utilizar una pestaña en la línea de comando sed.
La mayor parte de este tutorial es compatible con PCRE, el motor Regex predeterminado utilizado para PHP. Pero el motor Regex de JavaScript es distinto: no admite grupos de captura con nombre con comillas (quiere corchetes) y no puede hacer recursividad, entre otras cosas. Inclusive PCRE no es totalmente compatible con diferentes versiones, y tiene muchas diferencias de Perl regex.
Hay demasiadas diferencias menores para enumerarlas aquí, por lo que puede utilizar esta tabla de referencia para comparar las diferencias entre varios motores Regex. Al mismo tiempo, a los depuradores Regex les gusta Regex101 le posibilita cambiar los motores Regex, por lo tanto asegúrese de depurar usando el motor correcto.
Cómo ejecutar Regex
Hemos estado discutiendo la parte coincidente de las expresiones regulares, que constituye la mayor parte de lo que hace una expresión regular. Pero cuando verdaderamente desee ejecutar su Regex, deberá convertirlo en una expresión regular completa.
Esto de forma general toma el formato:
/match/g
Todo lo que hay dentro de las barras diagonales es nuestro partido. los g es un modificador de modo. Para este caso, le dice al motor que no deje de funcionar después de hallar la primera coincidencia. Para buscar y reemplazar Regex, a menudo tendrá que formatearlo como:
/find/replace/g
Esto reemplaza todo el archivo. Puede utilizar referencias de grupos de captura al reemplazar, lo que hace que Regex sea muy bueno para formatear texto. A modo de ejemplo, esta expresión regular coincidirá con cualquier etiqueta HTML y reemplazará los corchetes estándar con corchetes:
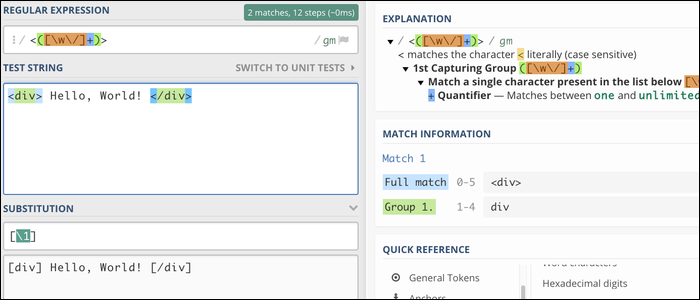
/<(.+?)>/[1]/g
Cuando esto funcione, el motor coincidirá <div> y </div>, lo que le posibilita reemplazar este texto (y solo este texto). Como puede ver, el HTML interno no se ve afectado:
Esto hace que Regex sea muy útil para buscar y reemplazar texto. La utilidad de línea de comando para hacer esto es sed, que utiliza el formato básico de:
sed '/find/replace/g' file > file
Esto se ejecuta en un archivo y se envía a STDOUT. Deberá conectarlo a sí mismo (como se muestra aquí) para reemplazar el archivo en el disco.
Regex además es compatible con muchos editores de texto y verdaderamente puede acelerar su flujo de trabajo al realizar operaciones por lotes. Empuje, Átomo, y VS BacalaoTodos disponen la función de búsqueda y reemplazo de Regex incorporada.
De todos modos, Regex además se puede utilizar a través de programación y, por lo general, está incorporado en muchos lenguajes. La implementación exacta dependerá del idioma, por lo que deberá consultar la documentación de su idioma.
A modo de ejemplo, en JavaScript, la expresión regular se puede crear literalmente o dinámicamente usando el objeto RegExp global:
var re = new RegExp('abc')
Esto se puede usar de forma directa llamando al .exec() método del objeto regex recién creado, o usando el .replace(), .match(), y .matchAll() métodos en cadenas.





