
Spaltenformate, als Apache Parkett, bieten große Einsparungen bei der Komprimierung und sind viel einfacher zu scannen, andere Formate wie CSV . verarbeiten und analysieren. In diesem Beitrag, Wir zeigen Ihnen, wie Sie Ihre CSV-Daten mit AWS Glue in Parkett konvertieren.
Was ist ein Spaltenformat??
CSV-Dateien, Protokolldateien und alle anderen durch Zeichen getrennten Dateien speichern Daten effizient in Spalten. Jede Datenzeile hat eine bestimmte Anzahl von Spalten, alles durch das Trennzeichen getrennt, wie Kommas oder Leerzeichen. Aber unter der Haube, diese Formate sind immer noch nur String-Linien. Es gibt keine einfache Möglichkeit, eine einzelne Spalte einer CSV-Datei zu scannen.
Dies kann bei Diensten wie AWS Athena ein Hindernis sein, die SQL-Abfragen für in CSV und anderen Dateien mit Trennzeichen gespeicherte Daten ausführen kann. Auch wenn Sie nur eine einzelne Spalte abfragen, Athena muss das scannen voll Dateiinhalt. Die einzige Gebühr von Athena sind die GB der verarbeiteten Daten, Daher ist es nicht die beste Idee, die Rechnung durch die Verarbeitung unnötiger Daten zu erhöhen.
Die Antwort ist ein echtes Spaltenformat. Spaltenformate speichern Daten in Spalten, wie eine traditionelle relationale Datenbank. Die Spalten werden zusammen gespeichert und die Daten sind viel homogener, das macht sie leichter zu komprimieren. Sohn nicht gerade menschenlesbar, aber sie werden von der Anwendung verstanden, die sie problemlos verarbeitet. Genau genommen, weil weniger Daten zu scannen sind, sie sind viel einfacher zu verarbeiten.
Denn Athena muss nur eine Spalte scannen, um eine Auswahl pro Spalte zu treffen, reduziert drastisch die Kosten, speziell für größere Datensätze. Wenn Sie haben 10 Spalten in jeder Datei und scannen Sie nur eine, das bedeutet Kosteneinsparungen von 90% einfach durch den Wechsel zu Parkett.
Konvertieren Sie automatisch mit AWS Glue
AWS Glue ist ein Amazon-Tool, das Datensätze zwischen Formaten konvertiert. Wird hauptsächlich als Teil einer Pipeline verwendet, um Daten zu verarbeiten, die in getrennten und anderen Formaten gespeichert sind, und injiziert sie in Datenbanken zur Verwendung in Athena. Obwohl es so konfiguriert werden kann, dass es automatisch ist, Sie können es auch manuell ausführen und, mit einigen Anpassungen, kann verwendet werden, um CSV-Dateien in das Parquet-Format zu konvertieren.
Wechseln Sie zur AWS Glue-Konsole und wählen Sie “Start”. In der Seitenleiste, klicke auf “Tracker hinzufügen” und erstellen Sie einen neuen Tracker. Der Crawler ist so konfiguriert, dass er nach Daten sucht von S3-Eimerund importieren Sie die Daten in eine Datenbank, um sie für die Konvertierung zu verwenden.
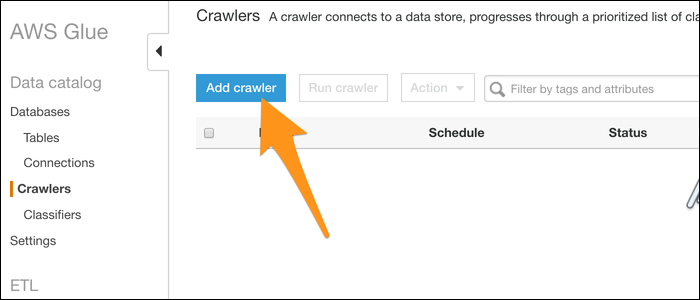
Benennen Sie Ihren Crawler und importieren Sie Daten aus einem Data Warehouse. Wählen Sie S3 (obwohl DynamoDB eine weitere Alternative ist) und geben Sie den Pfad zu einem Ordner ein, der Ihre Dateien enthält. Wenn Sie nur eine Datei haben, die Sie konvertieren möchten, lege es in einen eigenen Ordner.
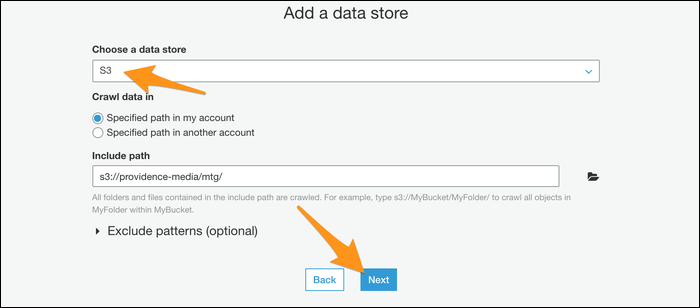
Nächste, Sie werden aufgefordert, eine IAM-Rolle für den Betrieb Ihres Crawlers zu erstellen. Rolle erstellen und dann aus der Liste auswählen. Möglicherweise müssen Sie die Aktualisierungstaste daneben drücken, damit sie angezeigt wird.
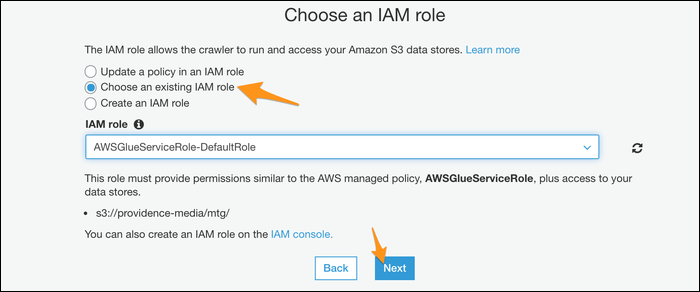
Wählen Sie eine Datenbank für die Crawler-Ausgabe; Wenn Sie Athena schon einmal verwendet haben, Sie können Ihre benutzerdefinierte Datenbank verwenden, aber wenn nicht, die Standardeinstellung sollte gut funktionieren.
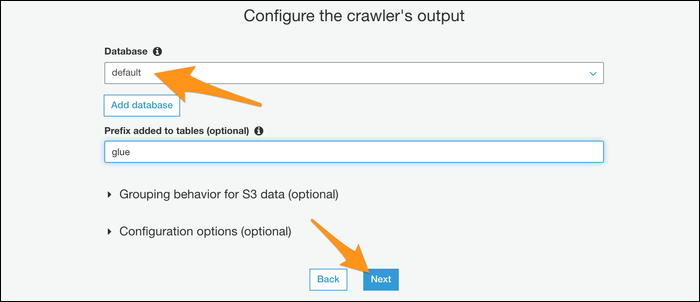
Wenn Sie den Vorgang automatisieren möchten, Sie können Ihrem Tracker einen Zeitplan für die regelmäßige Ausführung geben. Wenn dies nicht der Fall ist, Wählen Sie den manuellen Modus und führen Sie ihn selbst über die Konsole aus.
Einmal erstellt, Fahren Sie fort und führen Sie den Crawler aus, um die Daten in die von Ihnen ausgewählte Datenbank zu importieren. Wenn alles funktioniert, Sie sollten Ihre importierte Datei mit dem richtigen Schema sehen. Die Datentypen für jede Spalte werden automatisch basierend auf der Quelleingabe zugewiesen.
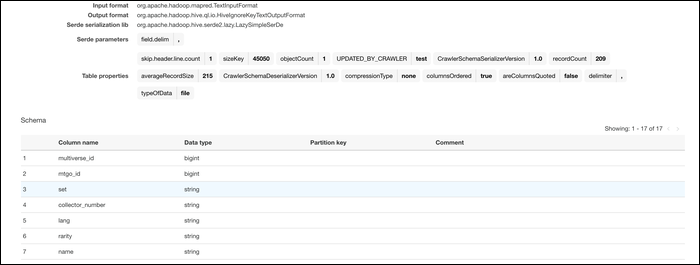
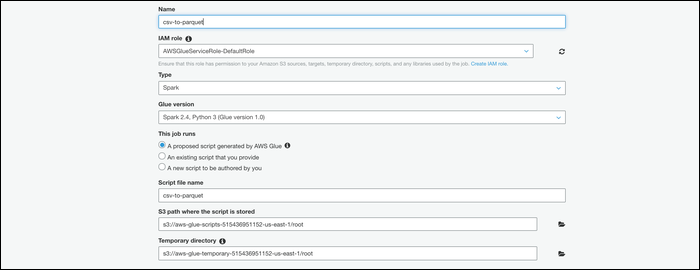
Sobald Ihre Daten im AWS-System sind, kann sie umwandeln. Von der Glue-Konsole, zur Registerkarte wechseln “Werk” und einen neuen Job schaffen. Gib ihm einen Namen, Fügen Sie Ihre IAM-Rolle hinzu und wählen Sie “Ein von AWS Glue generiertes Initiativskript” als das, was der Auftrag ausführt.
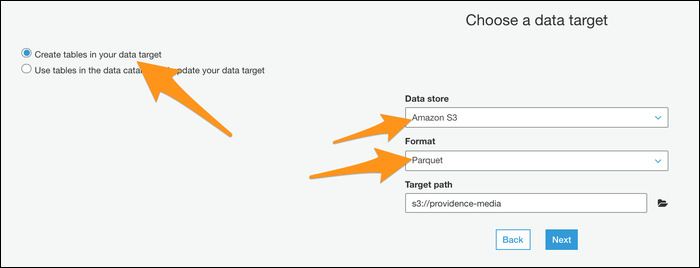
Wählen Sie Ihren Tisch auf dem nächsten Bildschirm aus, und wählen Sie dann “Schema ändern” Gehen Sie folgendermaßen vor, um anzugeben, dass dieser Auftrag eine Konvertierung ausführt.

Nächste, Sie müssen wählen “Erstellen Sie Tabellen in Ihrem Datenziel”, Geben Sie als Format Parkett an und geben Sie einen neuen Zielpfad ein. Stellen Sie sicher, dass dies ein leerer Ort ohne andere Dateien ist.
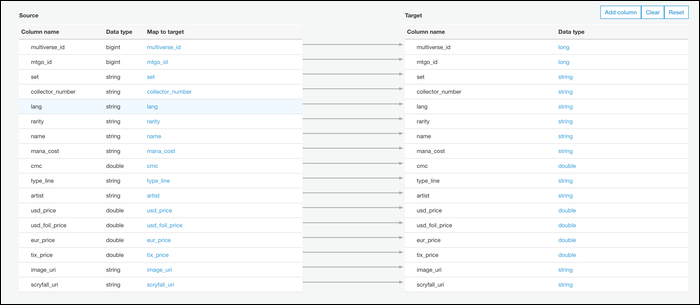
Nächste, Sie können Ihr Dateischema bearbeiten. Dies ist standardmäßig eine Eins-zu-Eins-Zuordnung von CSV-Spalten zu Parquet-Spalten, das ist wahrscheinlich das was du willst, aber du kannst es bei Bedarf ändern.
Erstellen Sie den Job und Sie werden zu einer Seite weitergeleitet, auf der Sie das von Ihnen ausgeführte Python-Skript bearbeiten können. Das Standardskript sollte gut funktionieren, Drücken Sie daher “Halten” und kehren Sie zur Registerkarte "Aufträge" zurück.
In unseren Tests, Das Skript ist immer fehlgeschlagen, es sei denn, die IAM-Rolle hatte eine bestimmte Berechtigung zum Schreiben an den Ort, an den wir die Ausgabe angegeben haben. Möglicherweise müssen Sie die Berechtigungen manuell im IAM-Verwaltungskonsole wenn du das gleiche problem hast.
Gegenteiliger Fall, klicke auf “Lauf” und Ihr Skript sollte gestartet werden. Der Vorgang kann ein oder zwei Minuten dauern, aber Sie sollten den Status im Info-Panel sehen. Wenn es vorbei ist, Sie sehen eine neue Datei, die in S3 erstellt wurde.
Dieser Job kann so konfiguriert werden, dass er außerhalb der Trigger ausgeführt wird, die vom Crawler festgelegt wurden, der die Daten importiert., so kann der gesamte Vorgang von Anfang bis Ende automatisiert werden. Wenn Sie auf diese Weise Serverprotokolle in S3 importieren, Dies kann eine einfache Methode sein, um sie in ein besser verwendbares Format zu konvertieren.





