
El Linux curl Der Befehl kann viel mehr als nur Dateien herunterladen. Finden Sie heraus, was curl er kann, und wann sollten Sie es stattdessen verwenden? wget.
Locken vs. wget: Was ist der Unterschied?
Die Menschen haben oft Schwierigkeiten, die relativen Stärken der wget und curl Befehle. Befehle haben einige funktionale Überschneidungen. Jeder kann Dateien von entfernten Standorten abrufen, aber hier hört die Ähnlichkeit auf.
wget es ist ein fantastisches Tool zum Herunterladen von Inhalten und Dateien. Sie können Dateien herunterladen, Webseiten und Verzeichnisse. Es enthält intelligente Routinen, um Links auf Webseiten zu durchsuchen und Inhalte rekursiv in einem gesamten Webportal herunterzuladen. Es ist unübertroffen als Befehlszeilen-Download-Manager.
curl erfüllen ein ganz anderes Bedürfnis. Jawohl, kann Dateien wiederherstellen, Sie können jedoch nicht rekursiv ein Webportal durchsuchen, um nach Inhalten zum Abrufen zu suchen. Dass curl In Wirklichkeit ermöglicht es Ihnen die Interaktion mit Remote-Systemen, indem Sie Anfragen an diese Systeme stellen und deren Antworten abrufen und anzeigen. Diese Antworten können Dateien und Website-Inhalte sein, Sie können aber auch Daten enthalten, die über einen Webdienst oder eine API als Ergebnis der “Frage” hergestellt durch die Curl-Anwendung.
UND curl nicht auf Websites beschränkt. curl unterstützt mehr als 20 Protokolle, einschließlich HTTP, HTTPS, SCP, SFTP und FTP. Und möglicherweise, aufgrund seiner überlegenen Handhabung von Linux-Pipes, curl lässt sich leichter mit anderen Befehlen und Skripten integrieren.
Der Autor von curl hat eine Website, die Beschreibe die Unterschiede, die du siehst Unter curl und wget.
Lockeninstallation
Von den Computern, mit denen dieser Beitrag recherchiert wurde, Fedora 31 und Manjaro 18.1.0 Sie hatten curl bereits installiert. curl es musste auf Ubuntu installiert werden 18.04 LTS. Unter Ubuntu, Führen Sie diesen Befehl aus, um es zu installieren:
sudo apt-get install curl

Die Curl-Version
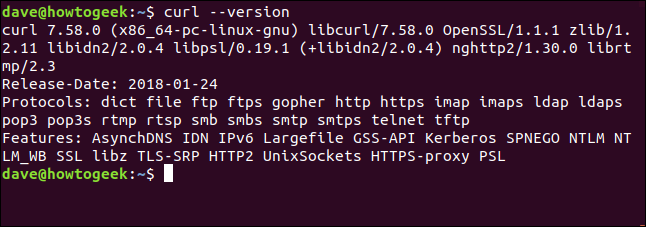
das --version Option macht curlmelde deine Version. Es listet auch alle Protokolle auf, die es unterstützt.
curl --version
Abrufen einer Webseite
Wenn wir zielen curl Auf einer Website, werde es für uns zurückbekommen.
locken https://www.bbc.com

Aber seine Standardaktion besteht darin, es im Terminalfenster als Quellcode herunterzuladen.
In acht nehmen: Wenn du nicht sagst curl möchte etwas als Datei speichern, es wird bis in alle Ewigkeit entleeren Sie es im Terminalfenster. Wenn die Datei, die Sie wiederherstellen, eine Binärdatei ist, Das Ergebnis kann unvorhersehbar sein. Die Shell versucht möglicherweise, einige der Bytewerte in der Binärdatei als Steuerzeichen oder Escape-Sequenzen zu interpretieren.
Daten in Datei speichern
Lassen Sie uns curl anweisen, die Ausgabe in eine Datei umzuleiten:
locken https://www.bbc.com > bbc.html

Diesmal sehen wir die wiederhergestellten Informationen nicht, von uns direkt ins Archiv geschickt. Da keine Terminalfensterausgabe zum Anzeigen vorhanden ist, curl erzeugt eine Reihe von Fortschrittsinformationen.
Sie haben dies im obigen Beispiel nicht getan, da die Fortschrittsinformationen über den Quellcode der Webseite verstreut gewesen wären, so dass curl automatisch gelöscht.
In diesem Beispiel, curl erkennt, dass die Ausgabe in eine Datei umgeleitet wird und dass es sicher ist, die Fortschrittsinformationen zu generieren.
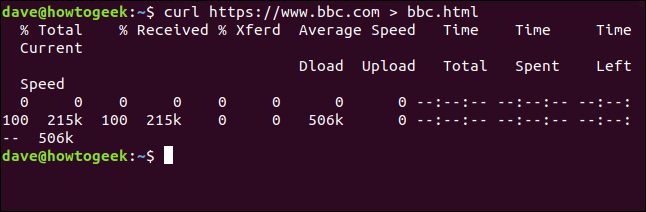
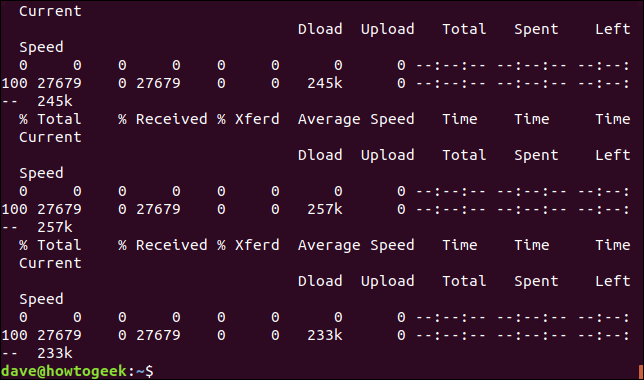
Die bereitgestellten Informationen sind:
- % Gesamt: Der zurückzufordernde Gesamtbetrag.
- % Er erhielt: Die prozentualen und tatsächlichen Werte der bisher abgerufenen Daten.
- % Xferd: Der Prozentsatz und der tatsächliche Versand, wenn Daten geladen werden.
- Download mit mittlerer Geschwindigkeit: Durchschnittliche Downloadgeschwindigkeit.
- Last mit mittlerer Geschwindigkeit: Durchschnittliche Upload-Geschwindigkeit.
- Gesamtzeit: Die geschätzte Gesamtdauer der Übertragung.
- Verwendete Zeit: Bisher verstrichene Zeit für diese Übertragung.
- Übrige Zeit: Die geschätzte verbleibende Zeit bis zum Abschluss der Übertragung.
- Momentane Geschwindigkeit: Die aktuelle Übertragungsgeschwindigkeit für diese Übertragung.
Weil wir die Ausgabe von umleiten curl in eine Datei, jetzt haben wir eine Datei namens “bbc.html”.
Durch Doppelklick auf diese Datei, Ihr Standardbrowser wird geöffnet, um die abgerufene Webseite anzuzeigen.
Bitte beachten Sie, dass die Adresse in der Adressleiste des Browsers eine lokale Datei auf diesem Computer ist, kein Remote-Webportal.
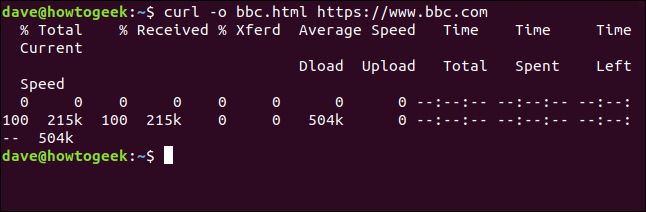
Wir müssen nicht umleiten die Ausgabe, um eine Datei zu erstellen. Wir können eine Datei erstellen mit dem -o (Ausgang) Möglichkeit, und sagen curl um die Datei zu erstellen. Hier verwenden wir die -o und geben Sie den Namen der Datei an, die wir erstellen möchten “bbc.html”.
curl -o bbc.html https://www.bbc.com
Verwenden eines Fortschrittsbalkens zum Überwachen von Downloads
Für textbasierte Download-Informationen, die durch einen einfachen Fortschrittsbalken ersetzt werden, benutze el -# (Fortschrittsanzeige) Möglichkeit.
curl -x -o bbc.html https://www.bbc.com

Neustart eines unterbrochenen Downloads
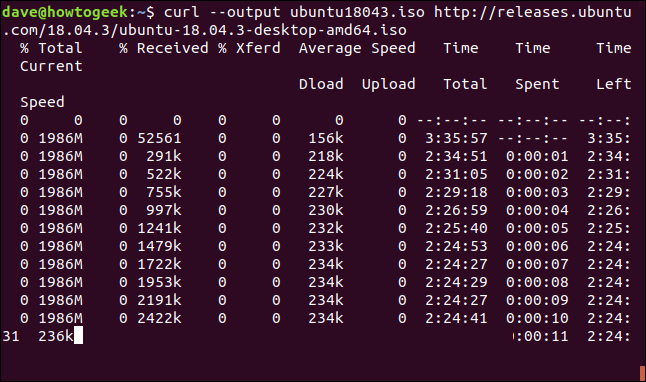
Es ist einfach, einen beendeten oder unterbrochenen Download neu zu starten. Beginnen wir mit dem Herunterladen einer beträchtlichen Datei. Wir werden den neuesten Ubuntu-Build für langfristigen Support verwenden 18.04. Wir verwenden die --output Option, um den Namen der Datei anzugeben, in der wir sie speichern möchten: “Ubuntu180403.iso”.
curl --output ubuntu18043.iso http://releases.ubuntu.com/18.04.3/ubuntu-18.04.3-desktop-amd64.iso

Der Download beginnt und wird bis zum Abschluss fortgesetzt.
Unterbrechen wir die Entladung gewaltsam mit Ctrl+C , Wir kehren zur Eingabeaufforderung zurück und der Download wird abgebrochen.
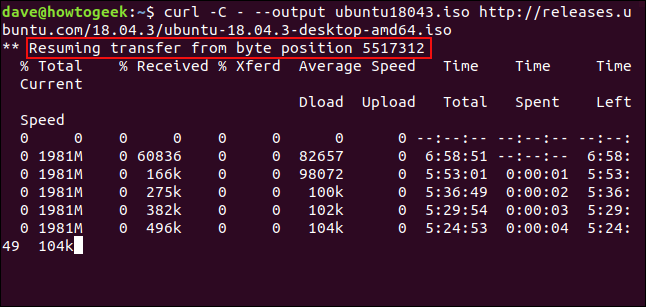
Um den Download neu zu starten, benutze el -C (weitermachen mit) Möglichkeit. Dies bewirkt curl um den Download an einer bestimmten Stelle neu zu starten oder wieder gut machen in der Zieldatei. Wenn Sie einen Bindestrich verwenden - wie Verdrängung, curl schaut sich den bereits heruntergeladenen Teil der Datei an und bestimmt den richtigen Offset für sich selbst.
curl -C - --Ausgabe ubuntu18043.iso http://releases.ubuntu.com/18.04.3/ubuntu-18.04.3-desktop-amd64.iso

Download-Neustarts. curl meldet den Offset, bei dem es neu gestartet wird.
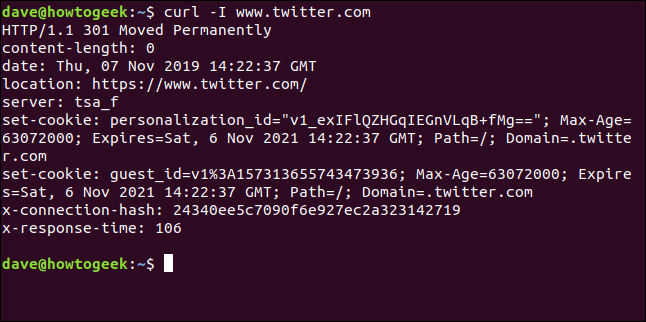
Abrufen von HTTP-Headern
Mit dem -I (Kopf), kann nur HTTP-Header abrufen. Dies ist das gleiche wie das Senden der Comando HTTP HEAD zu einem Webserver.
curl -ich www.twitter.com

Dieser Befehl ruft nur Informationen ab; lädt keine Webseiten oder Dateien herunter.
Von mehreren URLs herunterladen
Verwenden von xargs wir können mehrere herunterladen URLs sofort. Vielleicht möchten wir eine Reihe von Webseiten herunterladen, die einen einzelnen Beitrag oder ein Tutorial bilden.
Kopieren Sie diese URLs in einen Editor, und speichern Sie sie in einer Datei mit dem Namen “URLs zum Herunterladen.txt”. Wir können benutzen xargs zum Behandeln Sie den Inhalt jeder Zeile der Textdatei als Parameter, der an curl, Nacheinander.
https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#0 https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#1 https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#2 https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#3 https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#4 https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#5
Dies ist der Befehl, den wir verwenden müssen, um xargs Übergeben Sie diese URLs an curl eins gleichzeitig:
xargs -n 1 curl -O < URLs zum Herunterladen.txt
Beachten Sie, dass dieser Befehl die -O (Remote-Datei) Ausgabebefehl, die ein “Ö” Großbuchstabe. Diese Option verursacht curl um die wiederhergestellte Datei unter demselben Namen wie die Datei auf dem Remote-Server zu speichern.
das -n 1 Option sagt xargs um jede Zeile der Textdatei als einen einzelnen Parameter zu behandeln.
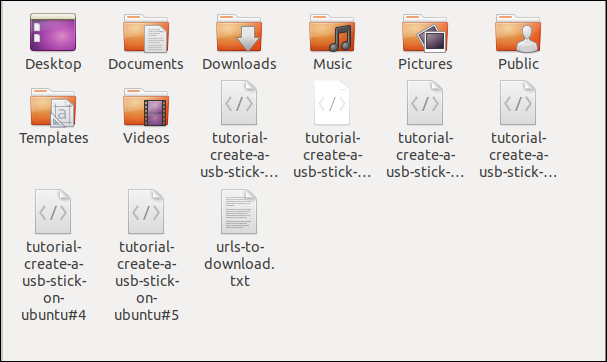
Wenn Sie den Befehl ausführen, Sie werden sehen, dass mehrere Downloads beginnen und enden, einer nach demanderen.
Das Einchecken im Datei-Explorer zeigt, dass mehrere Dateien heruntergeladen wurden. Jeder trägt den Namen, den er auf dem entfernten Server hatte.
VERBUNDEN: So verwenden Sie den xargs-Befehl unter Linux
Herunterladen von Dateien von einem FTP-Server
Verwenden von curl mit einem Dateiübertragungsprotokoll (FTP) Es ist leicht, auch wenn Sie sich mit Benutzername und Passwort authentifizieren müssen. So übergeben Sie einen Benutzernamen und ein Passwort mit curl benutze die -u (Nutzername) und schreibe den Benutzernamen, zwei Punkte ":" und das Passwort. Setzen Sie kein Leerzeichen vor oder nach dem Doppelpunkt.
Dies ist ein kostenloser FTP-Server, gehostet von Rebex. Die Test-FTP-Site hat einen voreingestellten Benutzernamen von “Demonstration” und das Passwort ist “Passwort”. Verwenden Sie diese Art von schwachem Benutzernamen und Kennwort nicht auf einem Produktions-FTP-Server oder “etwas namens erschaffen”.
curl -u Demo:Passwort ftp://test.rebex.net

curl es erkennt, dass wir auf einen FTP-Server verweisen und gibt eine Liste der Dateien zurück, die auf dem Server vorhanden sind.

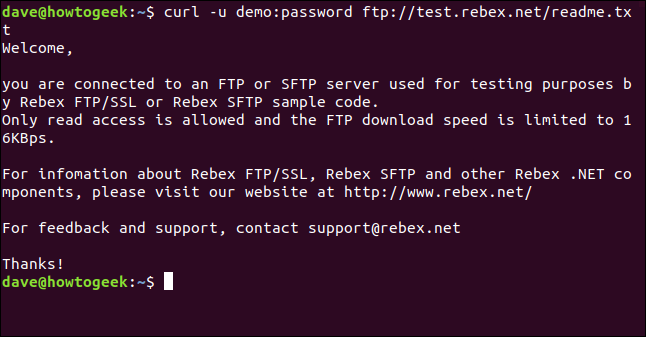
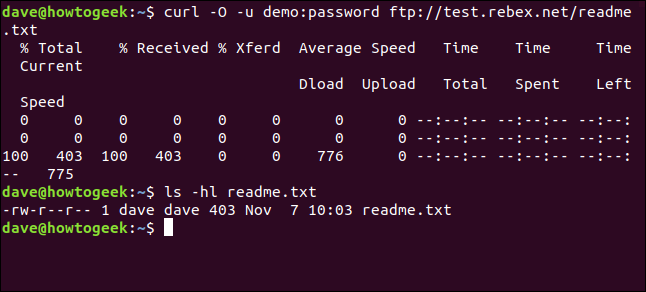
Die einzige Datei auf diesem Server ist eine Datei “Readme.txt”, von 403 Byte lang. Holen wir es zurück. Verwenden Sie den gleichen Befehl wie gerade jetzt, mit angehängtem Dateinamen:
curl -u Demo:Passwort ftp://test.rebex.net/readme.txt

Die Datei wird abgerufen und curl zeigt seinen Inhalt im Terminalfenster an.
In fast allen Fällen, Es ist bequemer, die wiederhergestellte Datei auf der Festplatte zu speichern, anstatt es im Terminalfenster anzuzeigen. Wir können wieder die -O (Remote-Datei) Exit-Befehl, um die Datei auf der Festplatte zu speichern, mit dem gleichen Dateinamen, den Sie auf dem Remote-Server haben.
curl -O -u Demo:Passwort ftp://test.rebex.net/readme.txt

Die Datei wird abgerufen und auf der Festplatte gespeichert. Wir können benutzen ls um die Dateidetails zu überprüfen. Hat den gleichen Namen wie die Datei auf dem FTP-Server und hat die gleiche Länge, 403 Bytes.
ls -hl readme.txt
VERBUNDEN: So verwenden Sie den FTP-Befehl unter Linux
Senden von Parametern an Remote-Server
Einige Remote-Server akzeptieren Parameter in Anfragen, die an sie gesendet werden. Parameter können verwendet werden, um die zurückgegebenen Daten zu formatieren, als Beispiel, oder sie können verwendet werden, um die genauen Daten auszuwählen, die der Benutzer wiederherstellen möchte. Es ist oft möglich, mit dem Web zu interagieren. Anwendungsprogrammierschnittstellen (API) mit curl.
Als einfaches Beispiel, das ipify Das Webportal verfügt über eine API, mit der Sie Ihre externe IP-Adresse ermitteln können.
locken https://api.ipify.org
Hinzufügen der format Parameter zum Befehl, mit dem Wert von “json” Wir können unsere externe IP-Adresse neu anordnen, aber dieses Mal werden die zurückgegebenen Daten im codierten JSON-Format.
locken https://api.ipify.org?format=json

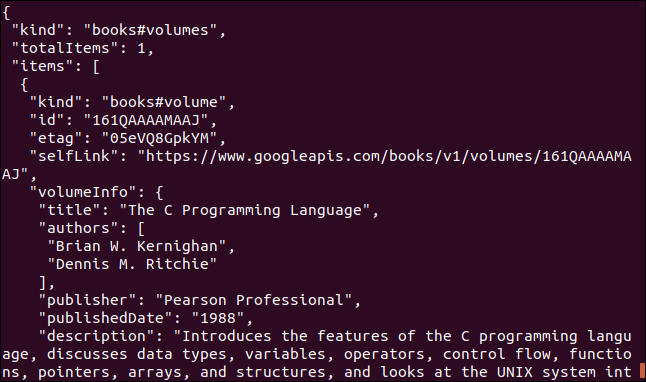
Hier ist ein weiteres Beispiel, das eine Google API verwendet. Gibt ein JSON-Objekt zurück, das ein Buch beschreibt. Der Parameter, den Sie angeben müssen, ist der Internationale Standardbuchnummer (ISBN) Nummer eines Buches. Sie finden sie auf der Rückseite der meisten Bücher, in der Regel unter einem Strichcode. Der Parameter, den wir hier verwenden werden, ist “0131103628”.
locken https://www.googleapis.com/books/v1/volumes?q=isbn:0131103628

Die zurückgegebenen Daten sind vollständig:
Manchmal locken, ein veces wget
Wenn Sie Inhalte von einem Webportal herunterladen und die Baumstruktur des Webportals rekursiv nach diesen Inhalten suchen lassen möchten, würde benutzen wget.
Wenn Sie mit einem Remote-Server oder einer API interagieren möchten, und möglicherweise einige Dateien oder Webseiten herunterladen, würde benutzen curl. Vor allem, wenn das Protokoll eines von vielen war, die von nicht unterstützt werden wget.
setTimeout(Funktion(){
!Funktion(F,B,e,v,n,T,S)
{wenn(f.fbq)Rückkehr;n=f.fbq=Funktion(){n.callMethode?
n.callMethod.apply(n,Argumente):n.queue.push(Argumente)};
wenn(!f._fbq)f._fbq = n;n.drücken=n;n.geladen=!0;n.version=’2.0′;
n.Warteschlange=[];t=b.Element erstellen(e);t.async=!0;
t.src=v;s=b.getElementsByTagName(e)[0];
s.parentNode.insertBefore(T,S) } (window, dokumentieren,'Skript',
„https://connect.facebook.net/en_US/fbevents.js’);
fbq('drin', ‘335401813750447’);
fbq('Spur', 'Seitenansicht');
},3000);





