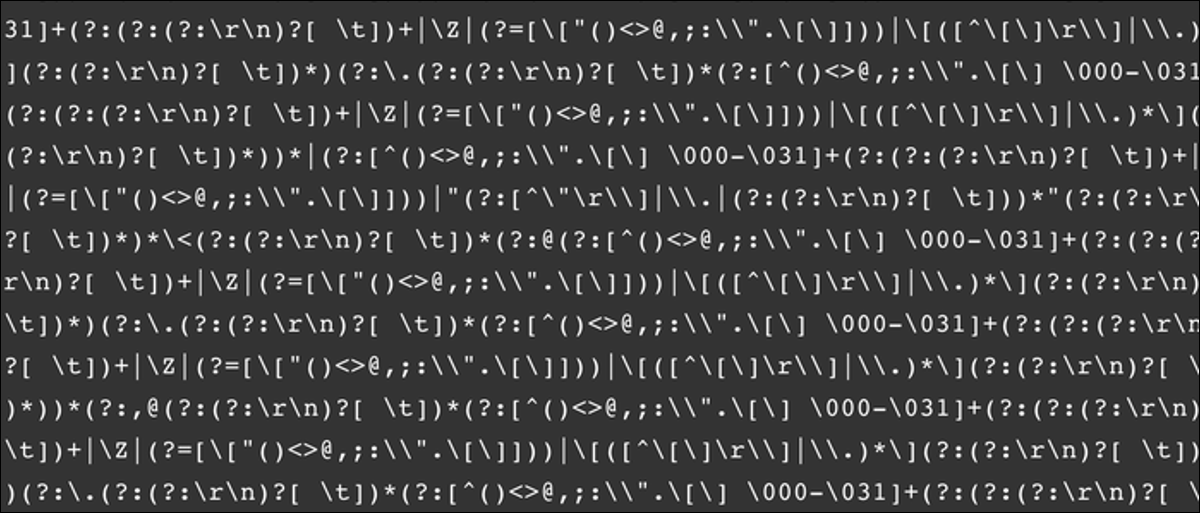
Regex, Abkürzung für reguläre Ausdrücke, wird oft in Programmiersprachen verwendet, um Muster in Strings abzugleichen, suchen und ersetzen, Eingabevalidierung und Neuformatierung von Text. Das Erlernen der richtigen Verwendung von Regex kann die Arbeit mit Text erheblich erleichtern.
Syntax für reguläre Ausdrücke, erklärt
Regex soll eine schreckliche Syntax haben, aber es ist viel einfacher zu schreiben als zu lesen. Als Beispiel, Hier ist ein allgemeiner regulärer Ausdruck für einen RFC-konformen E-Mail-Validator 5322:
(?:[A-Z0-9!#$%&'*+/=?^_`~-]+(?:.[A-Z0-9!#$%&'*+/=?^_`~-]+)*|"(?:[x01-
x08x0bx0cx0e-x1fx21x23-x5bx5d-x7f]|[x01-x09x0bx0cx0e-x7f])*")
@(?:(?:[A-Z0-9](?:[A-Z0-9-]*[A-Z0-9])?.)+[A-Z0-9](?:[A-Z0-9-]*[A-Z0-9])?|[(?
:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?).){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-
9][0-9]?|[A-Z0-9-]*[A-Z0-9]:(?:[x01-x08x0bx0cx0e-x1fx21-x5ax53-x7f]|
[x01-x09x0bx0cx0e-x7f])+)])
Wenn es so aussieht, als hätte jemand sein Gesicht gegen die Tastatur geschlagen, Du bist nicht allein. Aber unter der Haube, all dieses Durcheinander plant tatsächlich eine endliche Zustandsmaschine. Dieses System wird für jedes Zeichen ausgeführt, Voranschreiten und Kombinieren nach den von Ihnen festgelegten Regeln. Viele Online-Tools rendern Eisenbahndiagramme, zeigen, wie Ihr Regex-Gerät funktioniert. Hier ist die gleiche Regex in visueller Form:
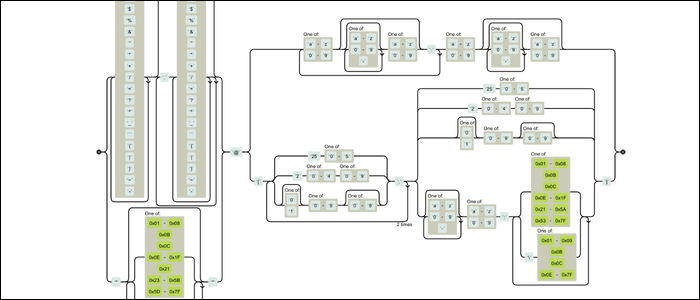
Immer noch sehr verwirrend, aber es ist viel verständlicher. Es ist eine Maschine mit beweglichen Teilen, die Regeln haben, die definieren, wie alles passt. Sie können sehen, wie jemand das zusammengebaut hat; es ist nicht nur viel text.
Entscheiden : Verwenden Sie einen Regex-Debugger
Bevor es losgeht, es sei denn, Ihre Regex ist besonders kurz oder Sie sind besonders kompetent, Sie sollten beim Schreiben und Testen einen Online-Debugger verwenden. Macht es viel einfacher die Syntax zu verstehen. Wir schlagen vor Regex101 und RegExr, bietet integrierte Syntaxreferenz und Tests.
Wie funktioniert Regex?
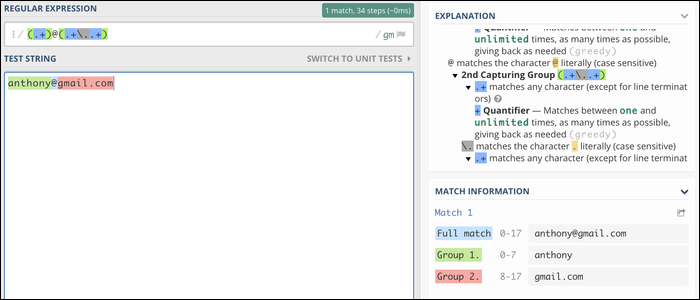
Zur Zeit, konzentrieren wir uns auf etwas viel einfacheres. Dies ist ein Diagramm von Regulex für eine sehr kurze E-Mail-Korrespondenz regulärer Ausdruck (und definitiv nicht RFC-konform 5322):

Die Regex-Engine startet links und fährt die Linien entlang, passende Charaktere, während du gehst. Die Gruppe # 1 entspricht jedem Zeichen außer einem Zeilenumbruch, und es werden weiterhin Zeichen abgeglichen, bis der nächste Block eine Übereinstimmung findet. Für diesen Fall, stoppt, wenn es a dreht @ Symbol, was bedeutet, dass die Gruppe # 1 erfasst den Namen der E-Mail-Adresse und alles, was folgt, stimmt mit der Domain überein.
Der reguläre Ausdruck, der die Gruppe festlegt # 1 in unserem E-Mail-Beispiel ist es:
(.+)
Klammern definieren eine Erfassungsgruppe, was die Regex-Engine anweist, den Inhalt der Übereinstimmung dieser Gruppe in eine spezielle Variable aufzunehmen. Wenn Sie einen regulären Ausdruck für eine Zeichenfolge ausführen, das Standardergebnis ist das komplette Spiel (für diesen Fall, alle E-Mails). Aber es gibt auch jede Capture-Gruppe zurück, was diese Regex nützlich macht, um Namen aus E-Mails zu extrahieren.
Der Punkt ist das Symbol von “Jedes Zeichen außer neuer Zeile”. Das passt alles in einer Zeile zusammen, Also, wenn Sie diese E-Mail an Regex weitergegeben haben, eine Adresse wie:
%$#^&%*#%$#^@gmail.com
Würde passen %$#^&%*#%$#^ als der Name, auch wenn das lächerlich ist.
Das Plus-Symbol (+) ist eine Kontrollstruktur, die bedeutet “Den vorherigen Charakter oder die vorherige Gruppe ein- oder mehrmals zuordnen”. Stellen Sie sicher, dass alle Namen übereinstimmen, und nicht nur das erste zeichen. Dies ist es, was die Schleife im Eisenbahndiagramm erstellt.
Der Rest von Regex ist ziemlich einfach herauszufinden:
(.+)@(.+..+)
Die erste Gruppe stoppt, wenn sie die @ Symbol. Später beginnt die nächste Gruppe, was wieder einigen Zeichen entspricht, bis es auf ein Punktzeichen trifft.
Weil Zeichen wie Punkte, Klammern und Schrägstriche werden als Teil der Syntax in Regrex verwendet, wann immer Sie diese Zeichen zuordnen möchten, muss korrekt mit einem Backslash auskommen. In diesem Beispiel, passend zum Zeitraum, wir schrieben . und der Analysator behandelt es als ein Symbol, das bedeutet “Zuordnen eines Punktes”.
Zeichenabgleich
Wenn Sie unkontrollierte Charaktere in Ihrem Regex haben, die Regex-Engine geht davon aus, dass diese Zeichen einen übereinstimmenden Block bilden. Als Beispiel, Regex:
er + es
Stimmt mit dem Wort überein “Hallo” mit beliebiger E-Nummer. Es ist notwendig, jedem anderen Zeichen zu entkommen, damit es richtig funktioniert.
Regex hat auch Charakterklassen, die als Abkürzung für eine Reihe von Zeichen fungieren. Diese können je nach Regex-Implementierung variieren, aber diese paar sind standard:
.– stimmt mit allem überein außer newline.w– Entspricht einem beliebigen Zeichen von “Wort”, einschließlich Ziffern und Unterstrichen.d– Ordne die Nummern richtig zu.b– stimmt mit Leerzeichen überein (Mit anderen Worten, Platz, tabellarisch, Neue Zeile).
Diese drei haben Gegenstücke in Großbuchstaben, die ihre Funktion umkehren. Als Beispiel, D stimmt mit etwas anderem als einer Zahl überein.
Regex hat auch einen Zeichensatz. Als Beispiel:
[ABC]
Passt zu jedem a, b, Ö c. Dies wirkt wie ein Block und die Klammern sind nur Kontrollstrukturen. Alternative, Sie können einen Zeichenbereich angeben:
[a-c]
Oder verweigere das Set, das passt zu jedem Zeichen, das nicht im Set ist:
[^a-c]
Quantifizierer
Quantifizierer sind ein wichtiger Bestandteil von Regex. Sie ermöglichen es Ihnen, Ketten zuzuordnen, bei denen Sie die nicht kennen Exakt Format, aber du hast eine ziemlich gute idee.
das + Der Operator im E-Mail-Beispiel ist ein Quantor, speziell der Quantifikator “eine oder mehrere”. Wenn wir nicht wissen, wie lang eine bestimmte Kette ist, aber wir wissen, dass es aus alphanumerischen Zeichen besteht (und es ist nicht leer), wir können schreiben:
w+
Zur gleichen Zeit von +, Es gibt auch:
- das
*Operator, die übereinstimmt “Null oder mehr”. Im Wesentlichen das gleiche wie+, außer Sie haben die Möglichkeit, keine Übereinstimmung zu finden. - das
?Operator, die übereinstimmt “Null oder Eins”. Hat den Effekt, einen Charakter optional zu machen; Entweder ist es da oder nicht, und es wird nicht mehr als einmal passen. - Numerische Quantoren. Dies kann eine einzelne Zahl sein wie
{3}, Was bedeutet das “Exakt 3 mal” oder ein Bereich wie{3-6}. Sie können die zweite Zahl überspringen, um sie unbegrenzt zu machen. Als Beispiel,{3,}es bedeutet “3 oder öfter”. neugierig, kann die erste zahl nicht überspringen, Also, wenn Sie wollen “3 Zeiten oder weniger”, du musst einen bereich verwenden.
Gierige und faule Quantoren
Unter der Haube, das * und + die Betreiber sind geizig. Stimmt so gut wie möglich überein und gibt zurück, was zum Starten des nächsten Blocks benötigt wird. Dies kann eine große Hürde sein..
Hier ist ein Beispiel: Angenommen, Sie versuchen, HTML oder etwas anderes mit schließenden geschweiften Klammern abzugleichen. Ihr Eingabetext ist:
<div>Hallo Welt</div>
Und Sie möchten alles innerhalb der Klammern zusammenbringen. Du kannst sowas schreiben wie:
<.*>
Das ist die richtige Idee, aber es scheitert aus einem entscheidenden grund: el motor Regex zusammenfallen “div>Hello World</div>“Für die Sequenz .*, und sichert dann, bis der nächste Block übereinstimmt, für diesen Fall, mit schließender Klammer (>). Hoffentlich wird es sich zurückziehen, nur um zu passen “div“, Und dann noch einmal wiederholen, um das abschließende div abzugleichen. Aber der Backtracker läuft vom Ende der Kette und stoppt an der Endhalterung, was am Ende zu allem innerhalb der Klammern passt.
Die Antwort ist, unseren Quantor faul zu machen, was bedeutet, dass so wenige Zeichen wie möglich übereinstimmen. Unter der Haube, das passt eigentlich nur zu einem zeichen, und dann wird es erweitert, um den Raum zu füllen, bis der nächste Block übereinstimmt, was es bei großen Regex-Operationen viel effizienter macht.
Um einen Quantor lazy zu machen, wird ein Fragezeichen direkt nach dem Quantor hinzugefügt. Das ist etwas verwirrend, weil ? ist schon ein Quantor (und es ist standardmäßig gierig). Für unser HTML-Beispiel, die Regex wird mit diesem einfachen Zusatz behoben:
<.*?>
Der Lazy-Operator kann zu jedem Quantor hinzugefügt werden, inbegriffen +?, {0,3}?, e inklusive ??. Auch wenn das letzte keine Wirkung hat; weil Sie sowieso mit null oder einem Zeichen übereinstimmen, kein raum zum erweitern.
Gruppierung und Lookarounds
Gruppen in Regex haben viele Zwecke. Auf einer grundlegenden Ebene, Kombiniere mehrere Kacheln in einem Block. Als Beispiel, Sie können eine Gruppe erstellen und dann einen Quantifizierer für die gesamte Gruppe verwenden:
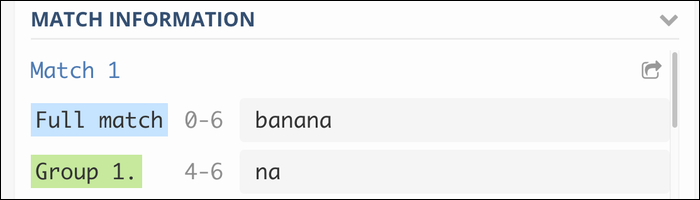
ba(An)+
Diese gruppiert die “An” wiederholt, um der Phrase zu entsprechen banana, und banananana, und so weiter. Ohne die Gruppe, die Regex-Engine würde immer und immer wieder mit dem endgültigen Zeichen übereinstimmen.
Diese Art von Gruppe mit zwei einzelnen Klammern wird als Erfassungsgruppe bezeichnet und wird in die Ausgabe aufgenommen:
Wenn Sie dies vermeiden möchten und die Token nur zu Ausführungszwecken gruppieren, Sie können eine Gruppe verwenden, die nicht erfasst:
ba(?:An)
Das Fragezeichen (ein reservierter Charakter) legt eine nicht standardmäßige Gruppe fest und das nächste Zeichen legt fest, um welche Art von Gruppe es sich handelt. Ideal ist es, Gruppen mit einem Fragezeichen zu starten, weil sonst, wenn ich Semikolons in einer Gruppe abgleichen wollte, Ich müsste ihnen ohne triftigen Grund entkommen. Aber du bis in alle Ewigkeit muss den Fragezeichen in Regex entkommen.
Sie können Ihre Gruppen auch benennen, zur Bequemlichkeit, wenn ich mit der Ausgabe arbeite:
(?'Gruppe')
Sie können diese in Ihrem Regex referenzieren, wodurch sie äquivalent zu Variablen funktionieren. Sie können mit dem Token auf unbenannte Gruppen verweisen 1, aber das geht nur bis 7, Danach müssen Sie mit der Benennung von Gruppen beginnen. Die Syntax für die Bezugnahme auf benannte Gruppen ist:
k{Gruppe}
Dies bezieht sich auf die Ergebnisse der genannten Gruppe, was dynamisch sein kann. Im Wesentlichen, Überprüfen Sie, ob die Gruppe mehrmals vorkommt, sich aber nicht um die Position kümmert. Als Beispiel, Dies kann verwendet werden, um den gesamten Text zwischen drei identischen Wörtern abzugleichen:
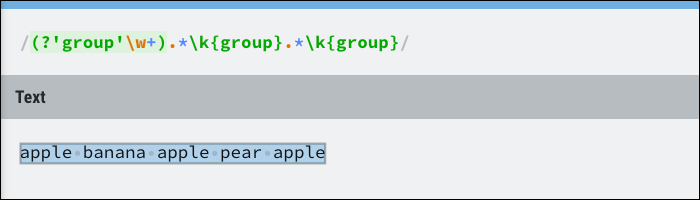
In der Gruppenklasse finden Sie den größten Teil der Regex-Kontrollstruktur, inklusive Look-Ahead. Lookaheads stellen sicher, dass ein Ausdruck übereinstimmen muss, fügen ihn jedoch nicht in das Ergebnis ein. In gewisser Weise, ist äquivalent zu einer if-Anweisung und stimmt nicht überein, wenn sie false zurückgibt.
Die Syntax für einen positiven Lookahead ist (?=). Hier ist ein Beispiel:
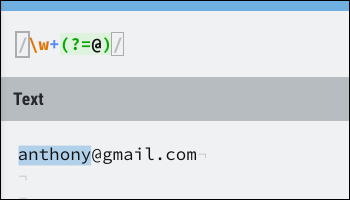
Das passt sehr gut zum Namensteil einer E-Mail-Adresse, Stoppen der Ausführung bei Division @. Lookahead-Suchen verbrauchen keine Zeichen, Wenn Sie also nach einem erfolgreichen Lookahead weiterlaufen möchten, Sie können immer noch das in Lookahead verwendete Zeichen abgleichen.
Gleichzeitig der positiven Outlooke, Es gibt auch:
(?!)– Lookaheads Negativos, die einen Ausdruck gewährleisten. Nein Spiel.(?<=)– Lookbehinds positiv, die aufgrund technischer Einschränkungen nicht überall unterstützt werden. Diese werden vor dem zu vergleichenden Ausdruck platziert und müssen eine feste Breite haben (Mit anderen Worten, keine Quantoren außer{number}. In diesem Beispiel, Du könntest benutzen(?<=@)w+.w+um den Domänenteil der E-Mail abzugleichen.(?<!)– Negative Blicke zurück, die den positiven Rückblicken gleichkommen, aber verweigert.
Unterschiede zwischen Regex-Engines
Nicht alle regulären Ausdrücke sind gleich. Die meisten Regex-Motoren folgen keinem bestimmten Standard, und einige ändern die Dinge ein wenig, um sie ihrer Sprache anzupassen. Einige Funktionen, die in einer Sprache funktionieren, funktionieren möglicherweise nicht in einer anderen.
Als Beispiel, die Versionen von sed kompiliert für macOS und FreeBSD unterstützt die Verwendung nicht t ein Tabulatorzeichen darstellen. Sie müssen ein Tabulatorzeichen manuell kopieren und in das Terminal einfügen, um ein Tabulatorzeichen in der Befehlszeile zu verwenden sed.
Der Großteil dieses Tutorials ist PCRE-kompatibel, die standardmäßige Regex-Engine, die für PHP verwendet wird. Aber die JavaScript Regex-Engine ist anders: unterstützt keine Erfassungsgruppen, die mit Anführungszeichen benannt sind (wollen Klammern) und kann keine Rekursion machen, unter anderem. Auch PCRE ist nicht vollständig kompatibel mit verschiedenen Versionen, und hat viele Unterschiede de Perl regex.
Es gibt zu viele kleine Unterschiede, um sie hier aufzulisten, damit du es verwenden kannst diese Referenztabelle um die Unterschiede zwischen verschiedenen Regex-Engines zu vergleichen. Zur selben Zeit, Regex-Debugger wie Regex101 ermöglicht den Austausch von Regex-Motoren, Stellen Sie daher sicher, dass Sie mit der richtigen Engine debuggen.
So führen Sie Regex aus
Wir haben den passenden Teil von Regex besprochen, was den größten Teil dessen ausmacht, was ein regulärer Ausdruck tut. Aber wenn Sie Ihre Regex wirklich ausführen möchten, Sie müssen es in eine vollständige Regex umwandeln.
Dies nimmt in der Regel das Format:
/Spiel/g
Alles innerhalb der Schrägstriche ist unser Match. das g es ist ein Modusmodifikator. Für diesen Fall, sagt der Engine, dass sie nicht aufhören soll zu laufen, nachdem die erste Übereinstimmung gefunden wurde. So finden und ersetzen Sie Regex, Sie müssen es oft formatieren als:
/finden/ersetzen/g
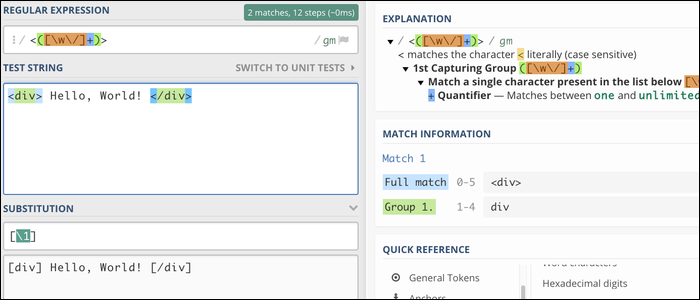
Dies ersetzt die gesamte Datei. Sie können beim Ersetzen Capture-Gruppenreferenzen verwenden, Dadurch kann Regex sehr gut Text formatieren. Als Beispiel, Diese Regex passt zu jedem HTML-Tag und ersetzt standardmäßige eckige Klammern durch eckige Klammern:
/<(.+?)>/[1]/g
Wenn das funktioniert, der motor wird passen <div> und </div>, wodurch Sie diesen Text ersetzen können (und nur dieser text). Wie du siehst, internes HTML ist nicht betroffen:
Dies macht Regex sehr nützlich zum Suchen und Ersetzen von Text. Das Befehlszeilen-Dienstprogramm dafür ist sed, welches das Grundformat von verwendet:
sed '/find/replace/g'-Datei > Datei
Dies wird in einer Datei ausgeführt und an STDOUT gesendet. Sie müssen es mit sich selbst verbinden (wie hier gezeigt) um die Datei auf der Festplatte zu ersetzen.
Regex ist auch mit vielen Texteditoren kompatibel und kann Ihren Arbeitsablauf durch Ausführen von Stapelvorgängen wirklich beschleunigen.. Drücken, Atom, und VS KabeljauAlle verfügen über eine integrierte Regex-Funktion zum Suchen und Ersetzen.
Auf jeden Fall, Regex kann auch durch Programmierung verwendet werden und, im Allgemeinen, ist in vielen Sprachen integriert. Die genaue Implementierung hängt von der Sprache ab, Sie sollten also die Dokumentation für Ihre Sprache konsultieren.
Als Beispiel, und JavaScript, Regex kann buchstäblich oder dynamisch mit dem globalen RegExp-Objekt erstellt werden:
var re = neuer RegExp('ABC')
Dies kann direkt durch Anrufen verwendet werden .exec() neu erstellte Regex-Objektmethode, oder mit dem .replace(), .match(), und .matchAll() Methoden auf Zeichenfolgen.





