
Software di accreditamento ottico dei caratteri (OCR) l'alta qualità potrebbe essere stata costosa in passato, ma ora è abilitato, Senza costi, direttamente dalla riga di comando del tuo terminale Linux. Questo post ti aiuterà a configurare e iniziare con l'OCR.
Cos'è l'OCR?
L'acronimo OCR sta per Accreditamento ottico dei caratteri: un programma software e un sistema attraverso il quale un computer può leggere il testo all'interno delle immagini. Immagina di scattare una foto del tuo brano preferito di uno dei libri de Il Signore degli Anelli.
Vorresti citarlo altrove, ma tutto quello che ha è una foto. Il software OCR può aiutarti analizzando quella foto / immagine e trovando tutto il testo al suo interno.
Dopo, il software OCR analizzerà, per ogni lettera scoperta, i punti grafici visti nell'immagine e tradurli / si trasformerà in testo reale che un computer può utilizzare, come esempio, in un elaboratore di testi.
Sebbene siano disponibili molti programmi OCR, alcuni a pagamento e altri gratuiti, non tutti sono della stessa qualità. Alcuni pacchetti forniranno risultati di qualità inferiore, altri si allineeranno strettamente con il testo visto nella foto o nell'immagine.
In termini generali, libri standard (o impressioni di pagine web su Internet) funzionerà molto bene e dovrebbe produrre risultati di qualità ragionevole in tutti i casi, poiché le sorgenti sono diritte e uniformi e sono ad un solo angolo, purché la foto o la scansione originale sia di dimensioni ragionevoli. qualità.
È anche bene prestare attenzione che anche i pacchetti software avanzati possono avere problemi con immagini di scarsa qualità o sfocate., e la maggior parte dei pacchetti potrebbe avere problemi con diversi stili di scrittura, eccetera. Altre sfide possono includere testo misto a immagini o foto, o direzioni diverse (come esempio, sinistra (testo sia a destra, dall'alto verso il basso o inclinato) all'interno della stessa pagina.
Questo rende la selezione, e potenzialmente pagare, un pacchetto OCR è una procedura forse lunga, soprattutto se vuoi testare ed esaminare ogni pacchetto.
Per chi usa Linux, c'è un ottimo percorso alternativo. Un software OCR di alta qualità e gratuito basato su LSTM Neural Net con supporto Unicode (UTF-8) e che può riconoscere più di 100 lingue per impostazione predefinita. Supporta anche molti formati di output come HTML, PDF e testo normale.
Senza più preamboli; Benvenuto in Tesseract OCR!
installazione Tesseract OCR
Installare Tesseract OCR sulla tua distribuzione Linux basata su Debian / apt (come Ubuntu e Mint), fare:
sudo apt install tesseract-ocr libtesseract-dev tesseract-ocr-eng
Installare Tesseract OCR presso RHEL e Centos, Fare quanto segue:
sudo yum install epel-releasesudo yum install tesseract-devel leptonica-devel
Installare Tesseract OCR in Fedora, fare:
sudo yum install tesseract-devel leptonica-devel
Installare Tesseract OCR su OSX, Fare quanto segue:
brew install tesseract
Passiamo all'OCR!
Useremo una semplice immagine che contiene il seguente testo:

Per convertire questa immagine, Tutto quello che devi fare è aprire il prompt di Terminale, Modificare la directory (usando il cd your_directory_with_images comando) alla directory che contiene le immagini (come esempio, Se è stata creata una directory di immagini nella home directory (~/images) puoi semplicemente usare cd ~/images) e OCR dei file:
tesseract -l eng input_for_ocr.png output_from_ocr
cat output_from_ocr.txt
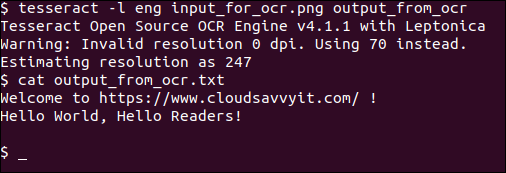
Molto semplice e diretto. E come possiamo vedere, l'output è perfetto.
Specifichiamo la lingua inglese utilizzando il -l eng opzione. Puoi consultare il manuale tesseract (man tesseract) per qualsiasi altro codice lingua disponibile.
Specifichiamo anche l'immagine di input (input_for_ocr.png) così come il file di output output_from_ocr senza alcuna estensione di file, che utilizzerà il testo normale predefinito .txt formato.
Possiamo anche cambiare il formato di output in PDF usando un comando leggermente più lungo che specifica semplicemente il formato di output alla fine:
tesseract -l eng input_for_ocr.png output_from_ocr pdf

Aggiungendo il pdf suffisso, il formato di output utilizzato era PDF. Quando apriamo il file PDF (output_from_ocr.pdf), possiamo vedere che il testo può essere scelto e copiato / incolla come si faceva con la parola lettori! qui:
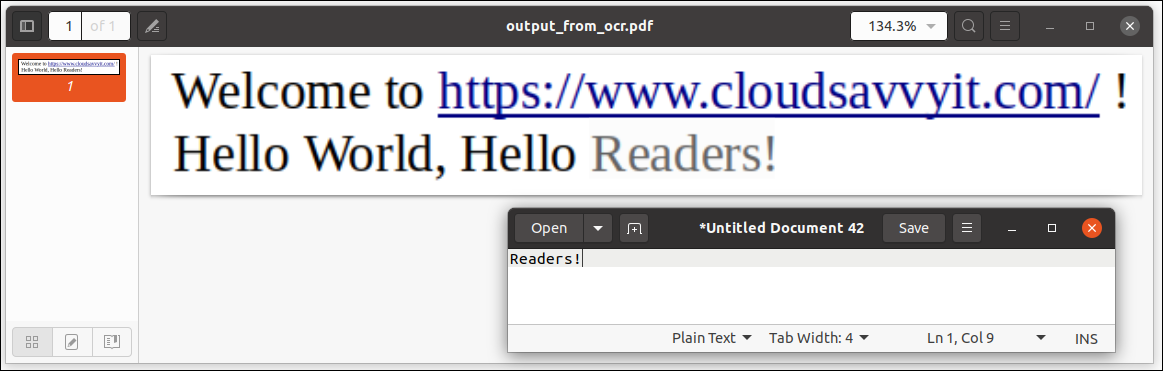
In altre parole, Il file PDF contiene dati selezionabili e basati su testo, nessuna informazione grafica (e quindi non selezionabile). Eccellente!
E se volessi eseguire l'OCR di un file PDF??
Qualche volta, puoi ricevere un file PDF che, anche se il formato PDF supporta il testo reale all'interno delle pagine, contiene solo immagini con testo. Questo può essere frustrante, poiché copia e incolla non saranno disponibili. Puoi anche eseguire l'OCR di queste pagine, con una piccola soluzione.
Prima vorrai convertire il tuo file PDF in immagini, un'immagine per pagina, e successivamente OCR le singole pagine in testo. Ancora un po' di lavoro, ma risparmia comunque molto tempo invece di ridigitare il testo manualmente.
Per conoscere i semplici passaggi per convertire un file PDF in immagini, o anche per creare uno script e automatizzare la conversione di più file PDF, puoi leggere il nostro post Converti PDF in immagini dalla riga di comando di Linux.
Fine
In questo post, esploriamo Tesseract, il motore OCR da riga di comando gratuito di alta qualità per Linux. Abbiamo visto come convertire facilmente le immagini in testo usando un semplice comando.
Analizziamo anche la conversione delle immagini in file PDF basati su testo, e abbiamo menzionato un post in cui puoi trovare informazioni su come pre-convertire file PDF basati su immagini in immagini in modo che possano essere successivamente convertiti in testo utilizzando il metodo OCR mostrato qui.
Godere!





