L'ordinamento di un file di registro in base a una colonna specifica è utile per trovare rapidamente le informazioni. I record sono generalmente archiviati come testo normale, in modo da poter utilizzare gli strumenti di manipolazione del testo della riga di comando per elaborarli e visualizzarli in un modo più leggibile.
Estrai colonne con cut e awk
il cut e awk Le utilità sono due modi diversi per estrarre una colonna di informazioni da file di testo. Entrambi presumono che i tuoi file di registro siano delimitati da spazi bianchi, come esempio:
colonna colonna colonna
Questo rappresenta un ostacolo se i dati all'interno delle colonne contengono spazi vuoti, come le date (“mercoledì 12 di giugno”). Tempo metereologico cut puoi vedere questo come tre colonne separate, puoi comunque estrarli tutti e tre contemporaneamente, supponendo che la struttura del file di registro sia coerente.
cut è molto semplice da utilizzare:
cat system.log | cut -d ' ' -f 1-6
il cat comando legge il contenuto di system.log e lo canalizza su cut. il -d flag specifica il delimitatore, per questo caso uno spazio vuoto. (L'impostazione predefinita è tab, t.) Il -f flag specifica quali campi generare. Questo comando stamperà specificamente le prime sei colonne di system.log. Se volessi stampare solo la terza colonna, userei il -f 3 bandiera.
awk è più potente ma non così conciso. cut è utile per estrarre colonne, come se volessi ottenere un elenco di indirizzi IP dai tuoi log di Apache. awk può riorganizzare intere righe, che può essere utile per ordinare un intero documento in base a una colonna specifica. awk è un linguaggio di programmazione completo, ma puoi usare un semplice comando per stampare le colonne:
cat system.log | imbarazzante '{Stampa $1, $2}'
awk esegui il tuo comando per ogni riga del file. Per impostazione predefinita, dividere il file per spazi bianchi e memorizzare ogni colonna in variabili $1, $2, $3, e così via. Usando il print $1 comando, può stampare la prima colonna, ma non esiste un modo semplice per stampare un intervallo di colonne senza utilizzare i loop.
Un vantaggio di awk è che il comando può fare riferimento all'intera riga contemporaneamente. Il contenuto della riga è memorizzato in variabile $0, che puoi usare per stampare l'intera riga. Quindi, Potevo, come esempio, stampa la terza colonna prima di stampare il resto della riga:
imbarazzante '{Stampa $3 " " $0}'
il " " stampa uno spazio tra $3 e $0. Questo comando ripete la colonna tre due volte, ma puoi risolverlo impostando il $3 variabile a nullo:
imbarazzante '{printf $3; $3=""; Stampa " " $0}'
il printf Il comando non stampa una nuova riga. Nello stesso modo, puoi escludere colonne specifiche dall'output impostandole tutte su stringhe vuote prima della stampa $0:
imbarazzante '{$1=$2=$3=""; Stampa $0}'
Puoi fare molto di più con awk, Compreso corrispondenza delle espressioni regolari, ma l'estrazione della colonna predefinita funziona bene per questo caso d'uso.
Ordina colonne con sort e uniq
il sort Il comando può essere utilizzato per ordinare un elenco di dati in base a una colonna specifica. La sintassi è:
sort -k 1
dove lui -k flag indica il numero di colonna. Devi inviare l'input a questo comando e sputare un elenco ordinato. Predefinito, sort utilizza l'ordine alfabetico ma supporta più opzioni tramite i flag, Che cosa -n per la classificazione numerica, -h per l'ordinamento dei suffissi (1M> 1K), -M categorizzare le abbreviazioni per mesi, e -V per ordinare i numeri di versione dei file (file-1.2.3> file-1.2.1).
il uniq Il comando filtra le righe duplicate, lasciando solo gli unici. Funziona solo per linee adiacenti (per motivi di prestazioni), quindi dovresti sempre usarlo dopo sort per rimuovere i duplicati in tutto il file. La sintassi è semplicemente:
sort -k 1 | unico
Se vuoi elencare solo i duplicati, usa el -d bandiera.
uniq puoi anche contare il numero di duplicati con il -c bandiera, che lo rende molto buono per il monitoraggio della frequenza. Come esempio, se vuoi ottenere un elenco dei principali indirizzi IP che raggiungono il tuo server Apache, puoi eseguire il seguente comando nel tuo access.log:
cut -d ' ' -f 1 | ordinare | uniq -c | sort no | testa
Questa stringa di comando taglierà la colonna dell'indirizzo IP, raggrupperà i duplicati, rimuoverà i duplicati contando ogni occorrenza, quindi ordinerà in base alla colonna del conteggio in ordine numerico decrescente, lasciandoti con una lista che assomiglia a questa:
21 192.168.1.1 12 10.0.0.1 5 1.1.1.1 2 8.0.0.8
Puoi applicare queste stesse tecniche ai tuoi file di registro, allo stesso tempo da altre utilità come awk e sed, per estrarre informazioni utili. Questi comandi concatenati sono lunghi, ma non è necessario scriverli tutto il tempo, poiché puoi sempre memorizzarli in uno script bash o alias tramite il tuo ~/.bashrc.
Filtraggio dei dati con grep e awk
grep è un comando molto semplice; ti dà una definizione di ricerca e ti passa l'input, e sputa fuori ogni riga che contiene quel termine di ricerca. Come esempio, se vuoi cercare gli errori 404 nel registro di accesso di Apache, puoi fare quanto segue:
gatto access.log | grep "404"
che sputerebbe un elenco di voci di registro che corrispondono al testo fornito.
Nonostante questo, grep non puoi limitare la tua ricerca a una colonna specifica, Questo comando avrà esito negativo se si dispone del testo “404” in qualsiasi altra posizione del file. Se vuoi solo guardare la colonna del codice di stato HTTP, deve usare awk:
gatto access.log | imbarazzante '{Se ($9 == "404") Stampa $0;}'
Insieme a awk, ha anche il vantaggio di poter effettuare ricerche negative. Come esempio, puoi cercare tutte le voci di registro che Non sono stato io ritorno con codice di stato 200 (ok):
gatto access.log | imbarazzante '{Se ($9 != "200") Stampa $0;}'
pur avendo accesso a tutte le funzioni programmatiche awk fornisce.
Opzioni GUI per i registri web
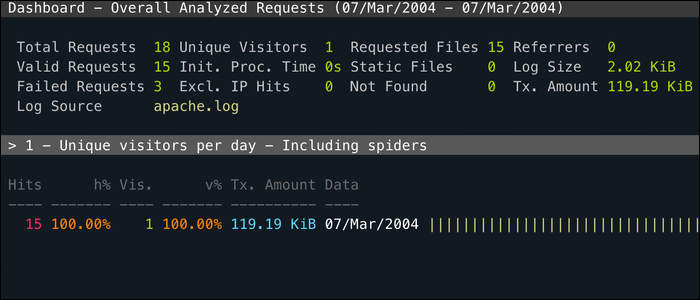
VaiAccesso è un'utility CLI per monitorare il registro di accesso del tuo server web in tempo reale e classificare per ogni campo utile. Funziona interamente sul tuo terminale, quindi puoi usarlo tramite SSH, ma ha anche un'interfaccia web molto più intuitiva.
apachetop è un'altra utility specifica per apache, che può essere utilizzato per filtrare e ordinare per colonne nel registro degli accessi. Funziona in tempo reale direttamente nel tuo access.log.





