
Vuoi analizzare quanto è lungo l'orologio da parete, ora del kernel, eccetera., un programma Linux richiede tempo per essere eseguito? Sia per i test delle prestazioni, ottimizzazione del codice o solo curiosità generale, questa guida rapida ti aiuterà a iniziare.
Programmazione di programmi Linux
Il tempismo di un programma Linux aiuta a capire quanto tempo è stato speso. Il versatile Linux time Il comando può essere usato per questo. il time Il comando misura in tempo reale (In altre parole, l'ora dell'orologio da parete), utente e sistema. Il tempo utente è il tempo in cui il programma viene eseguito in modalità utente, o in un altro modo, fuori dal kernel. L'ora di sistema è l'ora in cui il programma viene eseguito all'interno del kernel.
È essenziale prestare attenzione che sia il tempo dell'utente che il tempo del sistema siano il tempo effettivo della CPU trascorso all'interno della modalità utente e all'interno del kernel., rispettivamente. In altre parole, quando un programma è bloccato per un po' e non utilizza la CPU, quel tempo non conterà per Nome utente oh sys volte. Sapendo questo, possiamo misurare con precisione quanto tempo effettivo della CPU è stato utilizzato (combinandoli).
El Linux tempo metereologico Attrezzo
dato che Nome utente e sys i tempi riportano solo il tempo della CPU, mentre vero il tempo riporta l'ora reale dell'orologio da parete, è (perché) molto comune vedere il time output di ritorno utensile in cui una combinazione di Nome utente + sistema Non é la stessa cosa vero tempo metereologico. Un esempio può essere visto quando il tempismo sleep:
tempo di sonno 1

Qui abbiamo il tempo sleep comando usando il time attrezzo. Come possiamo vedere, Nostro vero tempo metereologico (1.001 secondi) corrisponde all'ora sul nostro orologio da parete e all'ora richiesta (sleep 1 chiedi un sogno di un secondo) ottimo. Vediamo anche che è stato necessario dedicare pochissimo tempo alla CPU al comando nel suo insieme: combinare Nome utente + sistema tempo metereologico, si vede che hanno solo speso 0.001 secondi.
Possiamo anche, probabilmente in modo errato, dedurre che il kernel non era coinvolto in questo comando, dal momento che sistema il tempo è davvero 0. Nonostante questo, Come la time indica il manuale: “Cuando el tiempo de ejecución de un comando es muy cercano a cero, alcuni valori (come esempio, la percentuale di CPU utilizzata) può essere riportato come zero (che è sbagliato) o como un signo de interrogación”.
Usando tempo metereologico Per misurare le prestazioni
Possiamo usare time para examinar cuánto tiempo tomarán las acciones dadas (In altre parole, tiempo de reloj de pared) y cuánto tiempo de CPU consumieron mientras lo hacían. Como ejemplo simple, podríamos examinar si algún caché del sistema de archivos está funcionando en nuestro sistema. Per farlo, podríamos saltar al /usr directory, que fácilmente podría contener 200k a 500k archivos en una instalación común de Linux.
Una volta lì, possiamo usare il find attrezzo, cronometrada por time para examinar cuánto tiempo tomaría escanear todas las carpetas y listar todos los archivos en el /usr directory:
cd /usr
time find . >/dev/null 2>&1
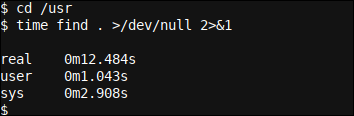
Come possiamo vedere, se necesitan 12.484 segundos para listar todos los archivos en el /usr directory (y debajo de él). Redirigimos la salida stdout (uscita standard) del comando a >/dev/null y además redirigir cualquier error stderr (errore standard) un /dev/null a través de el uso de una redirección de stderr a stdout, In altre parole 2>&1.
Además vemos que nuestro tiempo de CPU es 1.043 secondi (Nome utente) + 2.908 secondi (sistema) per un totale di 3.951 segundos de tiempo de CPU.
Probémoslo en otra ocasión borrando nuestra (S) cache (S) de inodo (e altri):
sync; eco 3 | sudo tee /proc/sys/vm/drop_caches cd /usr time find . >/dev/null 2>&1

Il primo comando cancellerà la cache degli inode, odontoiatria (voci di directory) e pagecache. Questa volta, il risultato è tornato un po' più veloce, insieme a 1,255 secondi salvati nel comando. Probabilmente una cache basata su disco fisico ha aiutato qui.
Per dimostrare come funziona la cache di Linux in generale, rieseguiamo il comando, ma questa volta senza rimuovere le cache di Linux:

Che differenza! Vediamo un'enorme diminuzione del tempo necessario in tutte e tre le aree cronometrate e il nostro comando viene eseguito in meno di mezzo secondo!!
Usando tempo metereologico Per l'ottimizzazione del codice
Una volta che ci sentiamo a nostro agio nell'usare il time comando sulla riga di comando, possiamo espandere il suo utilizzo per sfruttare appieno i nostri script e il codice bash. Come esempio, un approccio comunemente usato tra alcuni professionisti è quello di eseguire un certo comando di solito, Che cosa 1000 esecuzioni, e calcola il tempo totale (o media) di queste esecuzioni.
Quindi, è possibile utilizzare un comando alternativo. Quel comando alternativo (o soluzione / implementazione, In altre parole, più comandi presi insieme come un unico pezzo di codice da cronometrare) può essere cronometrato di nuovo. En Linux (o più specificamente nella codifica Bash, eccetera.), ci sono spesso molte alternative per affrontare un dato ostacolo; Generalmente, ci sono più strumenti disponibili per ottenere / ottenere lo stesso risultato.
Testare quale funziona meglio ottimizza il tempo di esecuzione del programma e potenzialmente altri fattori come E / S dal disco (riduzione dell'usura del disco) o l'utilizzo della memoria (consentire l'esecuzione di più programmi nella stessa istanza). Per sfruttare al meglio il tempo dell'orologio da parete, un certo strumento usa, in media, così come il tempo CPU consumato dallo strumento (un altro fattore / consideración importante de optimización) se puede medir a través de el time attrezzo.
Exploremos un ejemplo práctico del uso de la línea de comandos para ejecutar un comando que queremos utilizar en uno de nuestros scripts. El comando obtendrá una lista de procesos y mostrará la segunda columna. Usamos ambos awk e sed per farlo, y ejecute cada comando 1000 veces para ver la diferencia en el rendimiento general.
time for ((i=1;io<=1000;io++)); do ps -ef | imbarazzante '{Stampa $2}' >/dev/null 2>&1; done time for ((i=1;io<=1000;io++)); do ps -ef | ma 's|^[^ ]+[ T]+||;S|[ T].*||' >/dev/null 2>&1; fatto
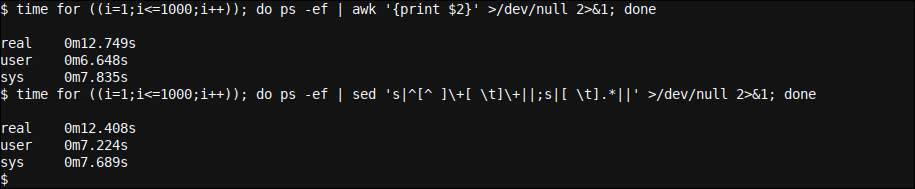
Anche quando sembra più complesso (usa una doppia espressione regolare per analizzare la seconda colonna), il nostro secondo comando è un po' più veloce del nostro primo comando quando si tratta dell'ora dell'orologio da parete.
Usando una configurazione molto simile (In altre parole time for ((i=1;i<=1000;i++)); do command_to_be_timed >/dev/null 2>&1; done dove command_to_be_timed è il comando da testare per l'orologio da parete o il tempo della CPU), si può testare il tempo di qualsiasi comando o insieme di comandi (come è il caso qui; usiamo tanto il ps e awk/sed comandi).
Segui questi passaggi per vari comandi che richiedono tempo (in qualsiasi script Linux) ci aiuterà a ridurre i tempi di esecuzione complessivi e / oh (se ottimizzi per ridurre il tempo della CPU) il carico di sistema dei nostri script.
Se vuoi saperne di più sulle espressioni regolari, Potresti essere interessato a Come modificare il testo usando le espressioni regolari con sed Stream Editor.
Fine
In questo post, esploriamo Linux time comando. Lo chiariamo vero, Nome utente e sistema i tempi indicano e come gli ultimi due si riferiscono all'utilizzo della CPU. Esaminiamo anche diversi esempi di come utilizzare tempo metereologico in modo pratico.
Se ti è piaciuto leggere questo post, dai un'occhiata alle Dichiarazioni, errori e crash: Qual è la differenza? e cos'è Stack Smashing?? Si può aggiustare ?.





