
El Linux curl Il comando può fare molto di più che scaricare file. Scopri cosa curl lui è in grado di, e quando dovresti usarlo al posto di wget.
arricciare contro. wget: Qual è la differenza?
Le persone spesso faticano a identificare i punti di forza relativi del wget e curl comandi. I comandi hanno qualche sovrapposizione funzionale. Ciascuno può recuperare file da postazioni remote, ma è qui che finisce la somiglianza.
wget è un fantastico strumento per scaricare contenuti e file. Puoi scaricare file, pagine web e directory. Contiene routine intelligenti per scorrere i collegamenti nelle pagine Web e scaricare i contenuti in modo ricorsivo in un intero portale Web. Non è secondo a nessuno come gestore di download da riga di comando.
curl soddisfare un'esigenza completamente diversa. sì, può recuperare i file, ma non puoi navigare in modo ricorsivo in un portale web alla ricerca di contenuti da recuperare. Quella curl ciò che realmente fa è permetterti di interagire con i sistemi remoti facendo richieste a quei sistemi e recuperando e visualizzando le loro risposte. Tali risposte possono essere file e contenuti del sito web, ma possono contenere anche dati forniti tramite un servizio web o API a seguito del “domanda” realizzato su richiesta di ricciolo.
E curl non limitato ai siti web. curl supporta più di 20 protocolli, incluso HTTP, HTTPS, SCP, SFTP e FTP. E possibilmente, grazie alla sua gestione superiore delle pipe Linux, curl può essere integrato più facilmente con altri comandi e script.
L'autore di curl ha un sito web che descrivi le differenze che vedi Tra curl e wget.
Installazione di riccioli
Dei computer utilizzati per ricercare questo post, Fedora 31 e Manjaro 18.1.0 Avevano curl già installato. curl doveva essere installato su Ubuntu 18.04 È. In Ubuntu, esegui questo comando per installarlo:
sudo apt-get install curl

La versione curl
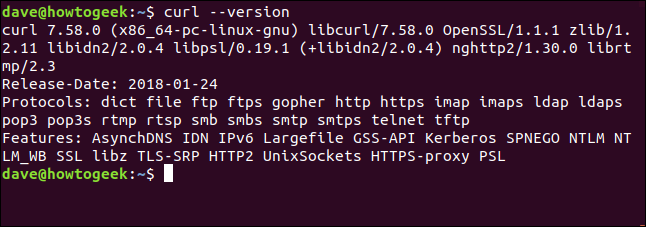
il --version l'opzione fa curlsegnala la tua versione. Elenca anche tutti i protocolli che supporta.
curl --version
Recupera una pagina web
Se miriamo curl Su un sito web, lo riavrà per noi.
ricciolo https://www.bbc.com

Ma la sua azione predefinita è scaricarlo nella finestra del terminale come codice sorgente.
Attenzione: Se non lo dici curl vuoi qualcosa archiviato come file, lo farà per sempre scaricalo nella finestra del terminale. Se il file che stai recuperando è un file binario, il risultato può essere imprevedibile. La shell potrebbe tentare di interpretare alcuni dei valori di byte nel file binario come caratteri di controllo o sequenze di escape.
Salva i dati su file
Diciamo a curl di reindirizzare l'output in un file:
ricciolo https://www.bbc.com > bbc.html

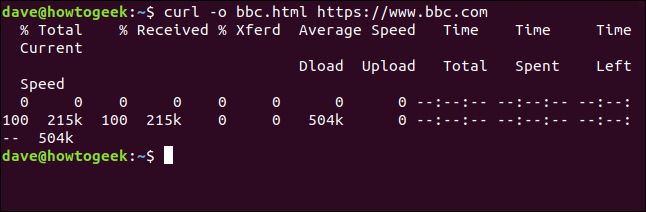
Questa volta non vediamo le informazioni recuperate, inviato direttamente all'archivio da noi. Perché non c'è un output della finestra del terminale da visualizzare, curl genera una serie di informazioni sullo stato di avanzamento.
Non l'hai fatto nell'esempio sopra perché le informazioni sullo stato di avanzamento sarebbero state sparse nel codice sorgente della pagina web, affinché curl l'ho cancellato automaticamente.
In questo esempio, curl rileva che l'output viene reindirizzato a un file e che è sicuro generare le informazioni sullo stato di avanzamento.
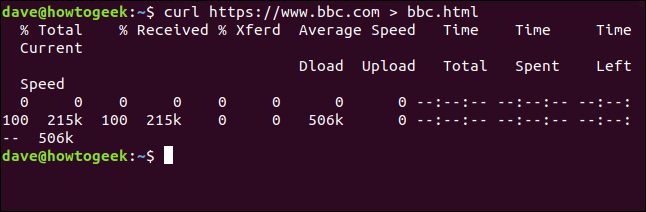
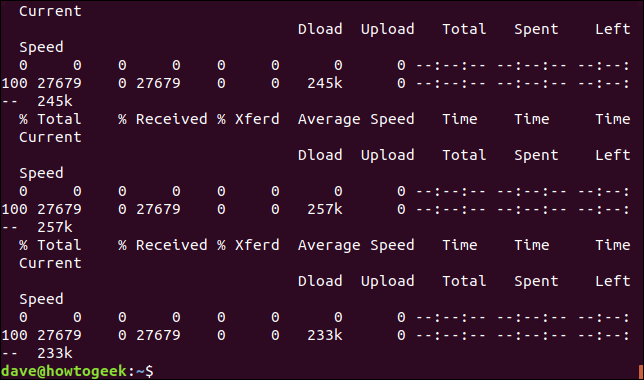
Le informazioni fornite sono:
- % Totale: L'importo totale da recuperare.
- % Ha ricevuto: La percentuale e i valori effettivi dei dati recuperati finora.
- % Xferd: La percentuale e la spedizione effettiva, se i dati si stanno caricando.
- Download a media velocità: Velocità di download media.
- Carico a velocità media: Velocità di caricamento media.
- Tempo totale: La durata totale stimata del trasferimento.
- Tempo impiegato: Il tempo trascorso finora per questo trasferimento.
- Tempo rimasto: Il tempo stimato rimanente per il completamento del trasferimento.
- Velocità attuale: La velocità di trasferimento corrente per questo trasferimento.
Perché reindirizziamo l'output di curl in un file, ora abbiamo un file chiamato “bbc.html”.
Facendo doppio clic su quel file, si aprirà il browser predefinito per visualizzare la pagina Web recuperata.
Si prega di notare che l'indirizzo nella barra degli indirizzi del browser è un file locale su questo computer, non un portale web remoto.
Non dobbiamo reindirizzare l'output per creare un file. Possiamo creare un file usando il -o (Uscita) opzione, e dicendo curl per creare il file. Qui stiamo usando il -o e fornendo il nome del file che vogliamo creare “bbc.html”.
curl -o bbc.html https://www.bbc.com
Utilizzo di una barra di avanzamento per monitorare i download
Affinché le informazioni di download basate su testo vengano sostituite da una semplice barra di avanzamento, usa el -# (barra di avanzamento) opzione.
curl -x -o bbc.html https://www.bbc.com

Riavvio di un download interrotto
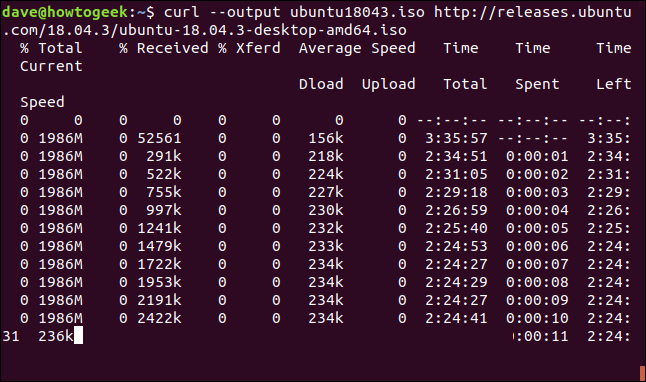
È facile riavviare un download terminato o interrotto. Iniziamo a scaricare un file di dimensioni considerevoli. Useremo l'ultima build di supporto a lungo termine di Ubuntu 18.04. Stiamo usando il --output opzione per specificare il nome del file in cui desideriamo salvarlo: “libero180403.iso”.
curl --output ubuntu18043.iso http://releases.ubuntu.com/18.04.3/ubuntu-18.04.3-desktop-amd64.iso

Il download inizia e prosegue fino al completamento.
Se interrompiamo forzatamente lo scarico con Ctrl+C , torniamo al prompt dei comandi e il download viene abbandonato.
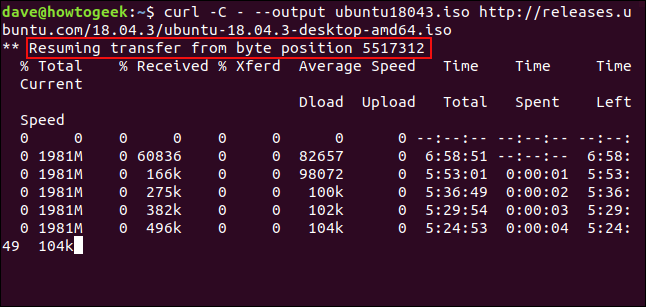
Per riavviare il download, usa el -C (continua) opzione. Questo causa curl per riavviare il download in un punto specificato oppure rimediare all'interno del file di destinazione. Se usi un trattino - come lo spostamento, curl guarderà la parte già scaricata del file e determinerà l'offset corretto da usare per se stesso.
arricciatura -C - --uscita ubuntu18043.iso http://releases.ubuntu.com/18.04.3/ubuntu-18.04.3-desktop-amd64.iso

Download riavvia. curl riporta l'offset al quale si sta riavviando.
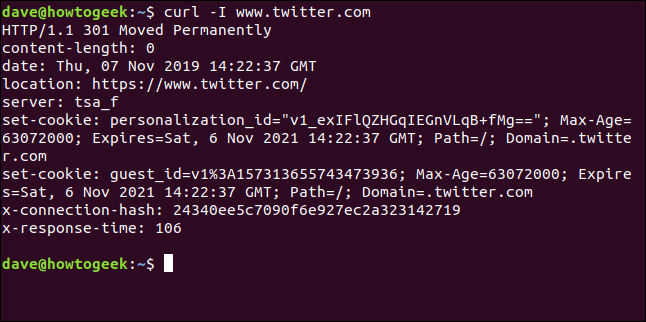
Recupero delle intestazioni HTTP
Con il -I (testa), può recuperare solo le intestazioni HTTP. Questo è lo stesso che inviare il Comando HTTP HEAD a un server web.
curl -I www.twitter.com

Questo comando recupera solo informazioni; non scarica pagine web o file.
Scarica da più URL
Usando xargs possiamo scaricarne diversi URL al momento. Forse vogliamo scaricare una serie di pagine web che compongono un singolo post o tutorial.
Copia questi URL in un editor e salvali in un file chiamato “URL-to-download.txt”. Possiamo usare xargs per trattare il contenuto di ogni riga del file di testo come parametro a cui verrà inviato curl, Successivamente.
https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#0 https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#1 https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#2 https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#3 https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#4 https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#5
Questo è il comando che dobbiamo usare per avere xargs passa questi URL a curl uno allo stesso tempo:
xargs -n 1 ricciolo -O < URL-to-download.txt
Nota che questo comando usa il -O (file remoto) comando di uscita, chi usa un “oh” lettera maiuscola. Questa opzione fa sì che curl per salvare il file recuperato con lo stesso nome del file sul server remoto.
il -n 1 opzione dice xargs trattare ogni riga del file di testo come un singolo parametro.
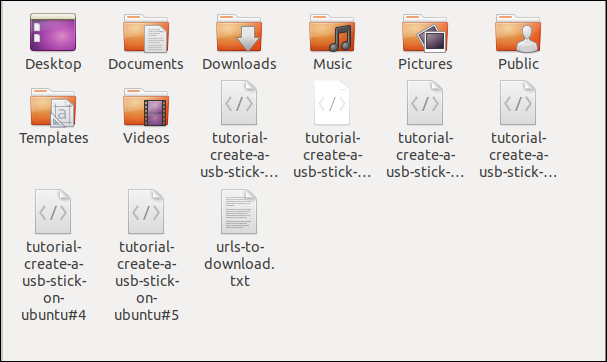
Quando esegui il comando, vedrai l'inizio e la fine di più download, uno dopo l'altro.
Il check-in in Esplora file mostra che sono stati scaricati più file. Ognuno porta il nome che aveva sul server remoto.
IMPARENTATO: Come usare il comando xargs in Linux
Download di file da un server FTP
Usando curl con un File Transfer Protocol (FTP) È facile, anche se devi autenticarti con username e password. Per passare un nome utente e una password con curl utilizzare il -u (Nome utente) e scrivi il nome utente, due punti ":" e la password. Non mettere uno spazio prima o dopo i due punti.
Questo è un server FTP gratuito ospitato da Rebex. Il sito FTP di prova ha un nome utente predefinito di “dimostrazione” e la password è “parola d'ordine”. Non utilizzare questo tipo di nome utente e password deboli su un server FTP di produzione o “vero”.
curl -u demo:password ftp://test.rebex.net

curl si accorge che lo stiamo puntando a un server FTP e restituisce un elenco dei file presenti sul server.

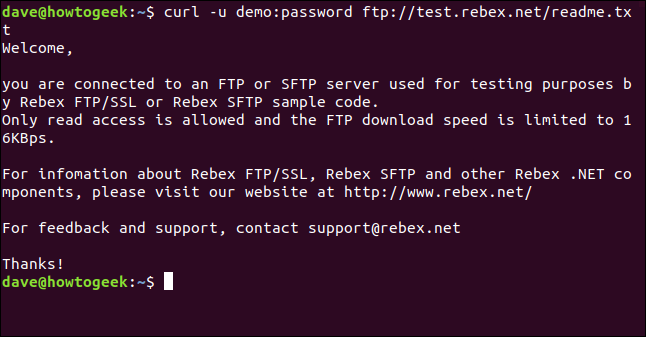
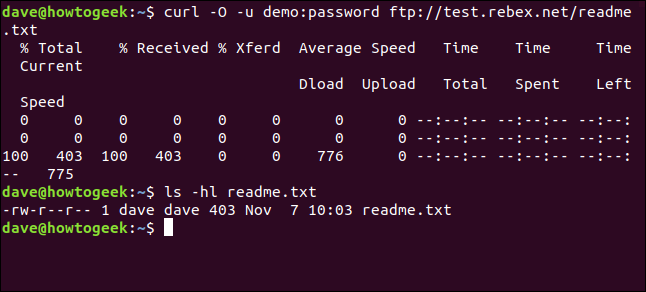
L'unico file su questo server è un file “leggimi.txt”, a partire dal 403 byte lunghi. Riprendiamolo. Usa lo stesso comando di adesso, con il nome del file allegato:
curl -u demo:password ftp://test.rebex.net/readme.txt

Il file viene recuperato e curl visualizza il suo contenuto nella finestra del terminale.
In quasi tutti i casi, sarà più conveniente salvare il file recuperato su disco, invece di visualizzarlo nella finestra del terminale. Ancora una volta possiamo usare il -O (file remoto) comando exit per salvare il file su disco, con lo stesso nome di file che hai sul server remoto.
curl -O -u demo:password ftp://test.rebex.net/readme.txt

Il file viene recuperato e salvato su disco. Possiamo usare ls per controllare i dettagli del file. Ha lo stesso nome del file sul server FTP e ha la stessa lunghezza, 403 byte.
ls -hl readme.txt
IMPARENTATO: Come usare il comando FTP in Linux
Invio di parametri a server remoti
Alcuni server remoti accetteranno parametri nelle richieste inviate loro. I parametri possono essere utilizzati per formattare i dati restituiti, come esempio, oppure possono essere utilizzati per scegliere i dati esatti che l'utente vuole recuperare. Spesso è possibile interagire con il web. interfacce di programmazione delle applicazioni (API) usando curl.
Come semplice esempio, il ipificare Il portale web ha un'API che può essere consultata per stabilire il tuo indirizzo IP esterno.
ricciolo https://api.ipify.org
Aggiungendo il format parametro da comandare, con il valore di “json” possiamo richiedere nuovamente il nostro indirizzo IP esterno, ma questa volta i dati restituiti saranno codificati nel Formato JSON.
ricciolo https://api.ipify.org?formato=json

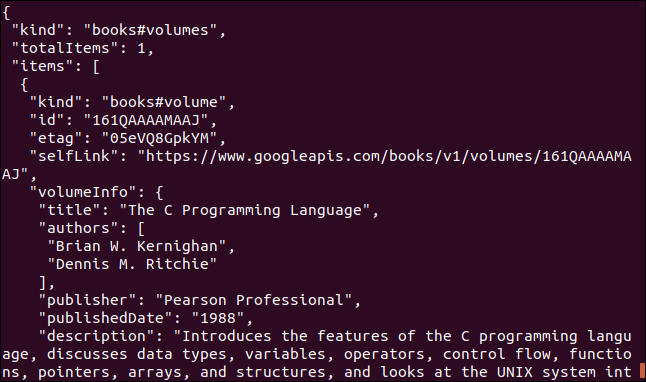
Ecco un altro esempio che utilizza un'API di Google. Restituisce un oggetto JSON che descrive un libro. Il parametro che devi fornire è il Numero di libro standard internazionale (ISBN) numero di un libro. Li puoi trovare sul retro della copertina della maggior parte dei libri, generalmente sotto un codice a barre. Il parametro che useremo qui è “0131103628”.
ricciolo https://www.googleapis.com/books/v1/volumes?q=isbn:0131103628

I dati restituiti sono completi:
a volte arricciare, a veces wget
Se si desidera scaricare contenuti da un portale Web e fare in modo che la struttura ad albero del portale Web cerchi in modo ricorsivo quel contenuto, userebbe wget.
Se volessi interagire con un server remoto o un'API, ed eventualmente scaricare alcuni file o pagine web, userebbe curl. Soprattutto se il protocollo fosse uno dei tanti non supportati da wget.
impostaTimeout(funzione(){
!funzione(F,B,e,v,n,T,S)
{Se(f.fbq)Restituzione;n=f.fbq=funzione(){n.callMethod?
n.callMethod.apply(n,argomenti):n.queue.push(argomenti)};
Se(!f._fbq)f._fbq = n;n.push=n;n.loaded=!0;n.version='2.0′;
n.coda=[];t=b.createElement(e);t.async=!0;
t.src=v;s=b.getElementsByTagName(e)[0];
s.parentNode.insertBefore(T,S) } (window, documento,'copione',
'https://connect.facebook.net/en_US/fbevents.js');
fbq('dentro', '335401813750447');
fbq('traccia', 'Visualizzazione della pagina');
},3000);





