
En Linux, awk è una dinamo di manipolazione del testo della riga di comando, così come un potente linguaggio di scripting. Ecco un'introduzione ad alcune delle sue caratteristiche più interessanti.
IMPARENTATO: 10 comandi di base di Linux per principianti
Com'è strano il suo nome?
il awk Il comando è stato nominato usando le iniziali delle tre persone che hanno scritto la versione originale in 1977: Alfred Aho, Peter Weinberger, e Brian Kernighan. Questi tre uomini erano del leggendario A&T Bell Labs Pantheon Unix. Con il contributo di molti altri da allora, awk ha continuato ad evolversi.
È un linguaggio di scripting completo, così come un toolkit di manipolazione del testo completo per la riga di comando. Se questo post ti stuzzica l'appetito, Maggio guarda ogni dettaglio su awk e la sua funzionalità.
Regole, modelli e azioni
awk funziona in programmi che contengono regole composte da schemi e azioni. L'azione viene eseguita sul testo che corrisponde al modello. I modelli sono racchiusi tra parentesi graffe ({}). Insieme, un modello e un'azione formano una regola. La totalità awk Il programma è tra virgolette singole (').
Diamo un'occhiata al tipo più semplice di awk Programma. non ha schema, in modo che corrisponda a tutte le righe di testo immesse al suo interno. Ciò significa che l'azione viene eseguita su ogni riga. Bene usalo sull'uscita di il who comando.
Ecco l'output standard di who:
chi
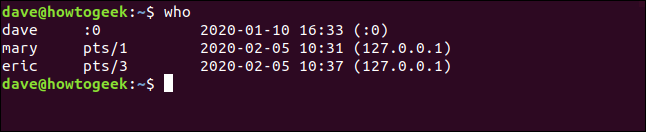
Potremmo non aver bisogno di tutte queste informazioni, ma piuttosto, vogliamo solo vedere i nomi nei conti. Possiamo incanalare l'output da who entro awke poi dire awk per stampare solo il primo campo.
Predefinito, awk considera un campo come una stringa di caratteri circondata da spazi, l'inizio di una riga o la fine di una riga. I campi sono identificati con il simbolo del dollaro ($) e un numero. Quindi, $1 rappresenta il primo campo, cosa useremo con esso? print azione per stampare il primo campo.
Scriviamo quanto segue:
chi | imbarazzante '{Stampa $1}'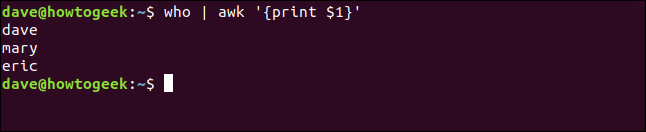
awk stampa il primo campo e scarta il resto della riga.
Possiamo stampare tutti i campi che vogliamo. Se aggiungiamo una virgola come separatore, awk stampa uno spazio tra ogni campo.
Scriviamo quanto segue per stampare anche l'ora della persona che ha effettuato l'accesso (campo quattro):
chi | imbarazzante '{Stampa $1,$4}'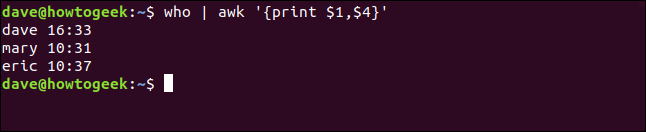
Ci sono un paio di identificatori di campo speciali. Questi rappresentano l'intera riga di testo e l'ultimo campo nella riga di testo:
- $ 0: Rappresenta l'intera riga di testo.
- $ 1: Rappresenta il primo campo.
- $ 2: Rappresenta il secondo campo.
- $ 7: Rappresenta il settimo campo.
- $ 45: Rappresenta il campo 45.
- $ NF: Significa “numero di campi” e rappresenta l'ultimo campo.
Scriveremo quanto segue per far apparire un piccolo file di testo contenente una breve citazione attribuita a Dennis Ritchie:
gatto dennis_ritchie.txt

Vogliamo awk per stampare il primo, secondo e ultimo campo della citazione. Notare che, anche quando avvolto nella finestra del terminale, è solo una riga di testo.
Scriviamo il seguente comando:
imbarazzante '{stampa $1,$2,$NF}' dennis_ritchie.txt
Non lo sappiamo “semplicità”. è il campo numerico 18 nella riga di testo, e non ci interessa. Quello che sappiamo è che è l'ultimo campo e che possiamo usare $NF per ottenere il suo valore. Il periodo è considerato solo un altro personaggio nel corpo del campo.
Aggiungi separatori di campo di output
Puoi anche dire awk per stampare un carattere particolare tra i campi invece del carattere spazio predefinito. L'output predefinito di date il comando è un po' particolare perché il tempo è proprio nel mezzo. Nonostante questo, possiamo scrivere quanto segue e usare awk per estrarre i campi che vogliamo:
Data
Data | imbarazzante '{Stampa $2,$3,$6}'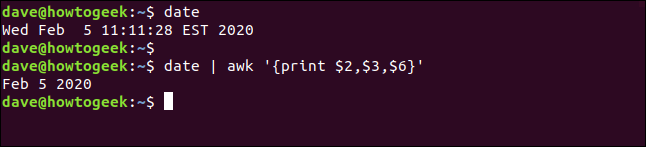
Useremo il OFS (separatore di campo di output) variabile per posizionare un separatore tra il mese, il giorno e l'anno. Nota che racchiudiamo il comando tra virgolette singole di seguito ('), niente chiavi ({}):
Data | awk 'OFS="https://www.systempeaker.com/" {stampa$2,$3,$6}'Data | awk 'OFS="-" {stampa$2,$3,$6}'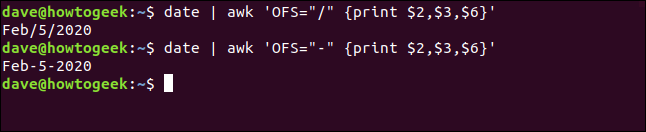
Le regole BEGIN e END
UN BEGIN La regola viene eseguita una volta prima che inizi l'elaborazione di testi. In realtà, corre prima awk anche leggere qualsiasi testo. un END La regola viene eseguita dopo che tutta l'elaborazione è stata completata. Puoi averne diversi BEGIN e END regole, e correranno in ordine.
Per il nostro esempio di BEGIN regola, stamperemo la citazione completa dal dennis_ritchie.txt file che abbiamo usato in precedenza con un titolo in cima.
Per farlo, scriviamo questo comando:
awk 'BEGIN {Stampa "Dennis Ritchie"} {Stampa $0}' dennis_ritchie.txt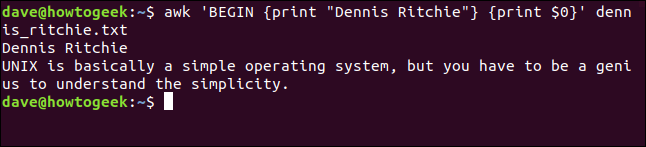
Notare la BEGIN La regola ha il proprio insieme di azioni racchiuso all'interno del proprio insieme di parentesi graffe ({}).
Possiamo usare questa stessa tecnica con il comando che abbiamo usato in precedenza per reindirizzare l'output di who entro awk. Per farlo, scriviamo quanto segue:
chi | awk 'BEGIN {Stampa "Sessioni Attive"} {Stampa $1,$4}'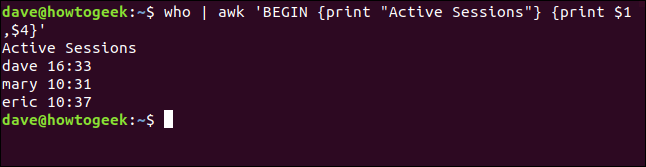
Separatori di campi di input
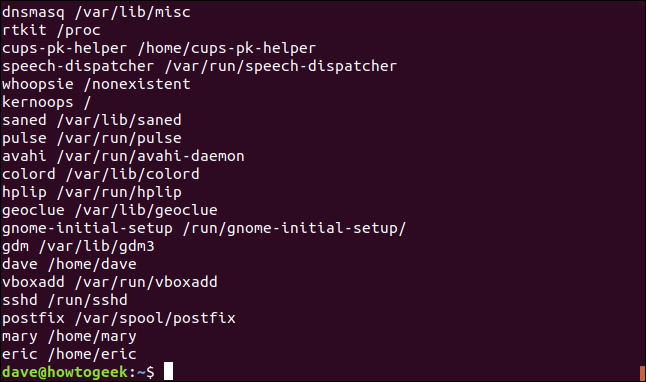
Se fai finta awk per lavorare con testo che non utilizza spazi bianchi per separare i campi, dovrebbe dirti quale carattere usa il testo come separatore di campo. Come esempio, il /etc/passwd il file usa i due punti (:) per separare i campi.
Useremo quel file e il -F (catena di separazione) possibilità di dire awk usa i due punti:) come separatore. Scriviamo quanto segue per contare awk per stampare il nome dell'account utente e la cartella home:
awk -F: '{Stampa $1,$6}' /etc/passwd
L'output contiene il nome dell'account utente (o il nome dell'applicazione o del demone) e la cartella home (o la posizione dell'applicazione).
Aggiunta di modelli
Se l'unica cosa che ci interessa sono i soliti account utente, possiamo includere un motivo con la nostra azione di stampa per filtrare tutti gli altri input. Perché ID utente Se i numeri sono uguali o maggiori di 1.000, possiamo basare il nostro filtro su tali informazioni.
Scriviamo quanto segue per eseguire la nostra azione di stampa solo quando il terzo campo ($3) contiene un valore di 1000 o più:
awk -F: '$ 3 >= 1000 {Stampa $1,$6}' /etc/passwd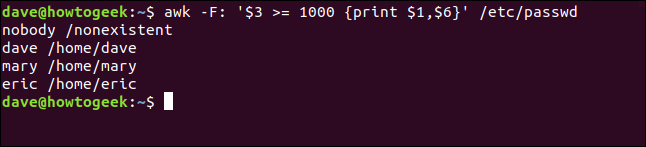
Il pattern deve precedere immediatamente l'azione a cui è correlato.
Possiamo usare il BEGIN regola per dare un titolo al nostro piccolo report. Scriviamo quanto segue, usando il (n) notazione per l'inserimento di un carattere di nuova riga nella stringa del titolo:
awk -F: 'INIZIO {Stampa "Account utenten-------------"} $3 >= 1000 {Stampa $1,$6}' /etc/passwd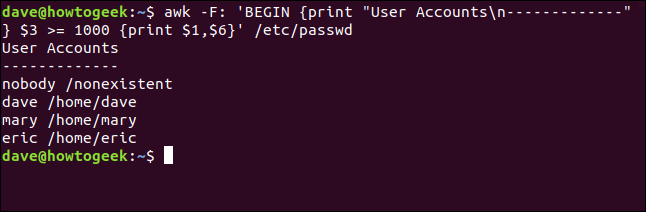
I modelli sono completi espressioni regolari, e sono una delle glorie di awk.
Diciamo che vogliamo vedere gli identificatori univoci universali (UUID) di file system montati. Se cerchiamo attraverso il /etc/fstab file per le occorrenze di stringa “UUID”, dovresti restituirci queste informazioni.
Usiamo il modello di ricerca "/ UUID /" nel nostro comando:
awk '/UUID/ {Stampa $0}' /etc/fstab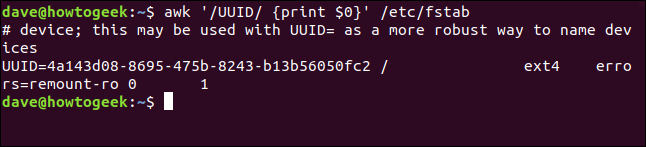
Trova tutte le occorrenze di "UUID" e stampa quelle righe. In realtà, avremmo ottenuto lo stesso risultato senza print action perché l'azione predefinita stampa l'intera riga di testo. Nonostante questo, per maggiore chiarezza, spesso è utile essere espliciti. Quando si esamina uno script o il suo archivio, sarai felice di aver lasciato degli indizi per te.
La prima riga trovata era una riga di commento e, anche quando la catena “UUID” è nel mezzo, awk l'ho ancora trovato. Possiamo modificare la regex e dire awk per elaborare solo le righe che iniziano con “UUID”. Per farlo, scriviamo quanto segue che include il token di inizio riga (^):
awk '/^UUID/ {Stampa $0}' /etc/fstab
Quello è meglio! Ora, vediamo solo istruzioni di montaggio originali. Per perfezionare ulteriormente l'output, scriviamo quanto segue e restringiamo la visualizzazione al primo campo:
awk '/^UUID/ {Stampa $1}' /etc/fstab
Se avessimo più file system montati su questa macchina, otterremmo una tabella ordinata dei suoi UUID.
Funzioni integrate
awk avere molte funzioni che puoi chiamare e usare nei tuoi programmi, sia dalla riga di comando che negli script. Se fai una piccola ricerca, lo troverai molto fruttuoso.
Per dimostrare la tecnica generale per chiamare una funzione, vedremo dei numeri. Come esempio, il seguente stampa la radice quadrata di 625:
awk 'BEGIN { print sqrt(625)}'Questo comando stampa l'arcotangente di 0 (zero) e -1 (che risulta essere la costante matematica, pi):
awk 'BEGIN {stampa atan2(0, -1)}'Nel seguente comando, modifichiamo il risultato di atan2() funzione prima della stampa:
awk 'BEGIN {stampa atan2(0, -1)*100}'Le funzioni possono accettare espressioni come parametri. Come esempio, ecco un modo complicato per chiedere la radice quadrata di 25:
awk 'BEGIN { print sqrt((2+3)*5)}'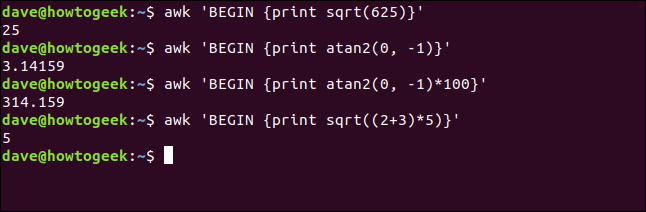
script awk
Se la tua riga di comando si complica o sviluppi una routine che sai che vorrai usare di nuovo, puoi trasferire il tuo awk comando in uno script.
Nel nostro script di esempio, faremo tutto quanto segue:
- Indica alla shell quale eseguibile utilizzare per eseguire lo script.
- Impostare
awkutilizzare ilFSvariabile di separazione dei campi per leggere il testo di input con i campi separati da due punti (:). - Utilizzare il
OFSseparatore di campo di output per contareawkusa i due punti:) per separare i campi nell'output. - Imposta un contatore su 0 (zero).
- Imposta il secondo campo di ogni riga di testo su un valore vuoto (è sempre un “X”, quindi non è necessario per noi vederlo).
- Stampa la riga con il secondo campo modificato.
- Aumenta il contatore.
- Stampa il valore del contatore.
Il nostro script è mostrato di seguito.

il BEGIN il sovrano esegue i passaggi preparatori, Nel frattempo lui END Il righello mostra il valore del contatore. La regola del mezzo (che non ha nome o modello, quindi corrisponde a tutte le linee) modificare il secondo campo, stampa la riga e incrementa il contatore.
La prima riga dello script dice alla shell quale eseguibile usare (awk, nel nostro esempio) per eseguire lo script. Passa anche il -f (nome del file) opzione per awk, che ti informa che il testo da elaborare proverrà da un file. Passeremo il nome del file allo script quando lo eseguiremo.
Abbiamo incluso il seguente script come testo in modo da poter tagliare e incollare:
#!/usr/bin/awk -f BEGIN { # set the input and output field separators FS=":" OFS=":" # zero the accounts counter accounts=0 } { # imposta campo 2 to nothing $2="" # print the entire line print $0 # count another account accounts++ } FINE { # print the results print accounts " accounts.n" }
Salva questo in un file chiamato omit.awk. Per Rendere eseguibile lo scriptme, Scriviamo quanto segue usando chmod:
chmod +x omit.awk

Ora, lo eseguiremo e passeremo il /etc/passwd da file a script. Questo è il file awk elaborerà per noi, usando le regole all'interno dello script:
./omit.awk /etc/passwd

Il file viene elaborato e ogni riga viene visualizzata, come mostrato di seguito.
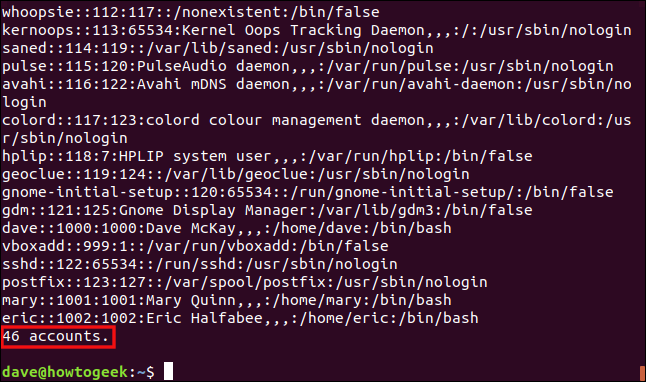
Voci rimosse “X” nel secondo campo, ma nota che i separatori di campo sono ancora presenti. Le righe vengono contate e il totale viene riportato in fondo all'output.
imbarazzante non significa imbarazzante
awk non significa scomodo; è sinonimo di eleganza. È stato descritto come un filtro di elaborazione e uno scrittore di report. Più accuratamente, sono entrambi o?, piuttosto, uno strumento che puoi usare per entrambi i compiti. In poche righe, awk raggiunge ciò di cui ha bisogno la codifica estesa in una lingua tradizionale.
Quel potere è imbrigliato dal semplice concetto di regole che contengono schemi., che selezionano il testo da elaborare e le azioni che definiscono l'elaborazione.





