
El Linux stat Il comando mostra molti più dettagli di ls lo fa?. Dai un'occhiata dietro le quinte con questa utility informativa e configurabile. Ti mostreremo come usarlo.
stat ti porta dietro le quinte
il ls Il comando è eccellente in quello che fa, e tanto tempo fa, ma con Linux, sembra che ci sia sempre un modo per scavare in profondità e vedere cosa c'è sotto la superficie. E, spesso, non si tratta solo di sollevare il bordo del tappeto. Puoi rompere le assi del pavimento e poi scavare una buca. Puoi sbucciare Linux come una cipolla.
ls ti mostrerà molte informazioni su un file, come quali permessi sono impostati su di esso, quanto è grande e se è un file o un collegamento simbolico. Per visualizzare queste informazioni ls leggilo da a struttura del file system chiamata inode.
Ogni file e directory ha un inode. L'inode tiene metadati sul file, come il blocco del filesystem che occupa e la data associata al file. L'inode è come una tessera della biblioteca per il file. Ma ls ti mostrerà solo una parte delle informazioni. Per vedere tutto, dobbiamo usare il stat comando.
Piace ls , il stat Il comando ha molte opzioni. Questo lo rende un ottimo candidato per l'aliasing.. Una volta scoperto un particolare insieme di alternative che rendono stat darti il risultato che vuoi, avvolgerlo in un alias o in una funzione di shell. Ciò lo rende molto più comodo da usare e non è necessario ricordare un insieme arcano di alternative da riga di comando.
IMPARENTATO: Come usare il comando ls per elencare file e directory in Linux
Un rapido confronto
Usiamo ls per darci un lungo elenco -l opzione) con dimensioni di file leggibili dall'uomo ( -h opzione):
ls -lh ana.h

Da sinistra a destra, le informazioni fornite da ls sono:
- Il primo carattere è un trattino "-" e questo ci dice che il file è un file normale e non un socket, collegamento simbolico o altro tipo di oggetto.
- Proprietario, il gruppo e gli altri permessi sono elencati in formato ottale.
- Il numero di collegamenti fisici che puntano a questo file. Per questo caso, e nella maggior parte dei casi, sarà uno.
- Il proprietario del file è Dave.
- Il proprietario del gruppo è Dave.
- La dimensione del file è 802 byte.
- Il file è stato modificato l'ultima volta venerdì 13 da dicembre a 2015.
- Il nome del file è
ana.c.
Diamo un'occhiata con stat :
stat ana.h
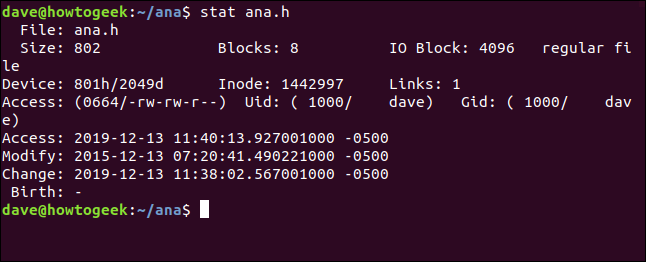
Le informazioni che otteniamo da stat è:
- Procedimenti: Il nome del file. Generalmente, è lo stesso del nome che gli diamo.
statsulla riga di comando, ma potrebbe essere diverso se osserviamo un collegamento simbolico. - Taglia: La dimensione del file in byte.
- blocchi: Il numero di blocchi del filesystem di cui il file deve essere archiviato sul disco rigido.
- Bloque IO: La dimensione di un blocco del file system.
- Tipo di file: Il tipo di oggetto descritto dai metadati. I tipi più comuni sono file e directory, ma possono anche essere link, prese o tubi denominati.
- Dispositivo: Il numero del dispositivo in esadecimale e decimale. Questo è l'ID del disco rigido in cui è archiviato il file.
- Inodo: numero di inode. In altre parole, il numero di identificazione di questo inode. Insieme, numero di inode e numero di dispositivo identificano in modo univoco un file.
- Link: Questo numero indica quanti collegamenti fisici puntano a questo file. Ogni collegamento fisico ha il suo inode. Quindi, un altro modo di pensare a questa figura è quanti inode puntano a questo file. Ogni volta che viene creato o eliminato un collegamento fisico, questo numero verrà aumentato o diminuito. Quando raggiunge lo zero, il file stesso è stato rimosso e l'inode è stato rimosso. Se usi
statin una directory, questo numero rappresenta il numero di file nella directory, includendo il “.” la voce per la directory corrente e la voce “..” la voce per la directory corrente e la voce. - Accesso: I permessi dei file sono mostrati nella loro ottale e tradizionale.
rwx(leggere, scrivere, eseguire formati). - Uid: ID utente e nome account del proprietario.
- Guida: ID del gruppo e nome dell'account del proprietario.
- Accesso: Il timestamp di accesso. Non è così facile come potrebbe sembrare. Le moderne distribuzioni Linux usano uno schema chiamato
relatime, cosa stai provando? ottimizzare le scritture del disco rigido necessarie per aggiornare il tempo di accesso. Brevemente, l'orario di accesso viene aggiornato se è precedente all'orario modificato. - Modificare: Il timestamp della modifica. Questo è il momento in cui il file contenuto sono stati modificati l'ultima volta. (fortunatamente, il contenuto di questo file è stato modificato l'ultima volta quattro anni fa).
- Modificare: Il timestamp del cambiamento. Questo è il momento in cui il file attributi oh contenuto sono stati modificati l'ultima volta. Se modifichi un file impostando nuovi permessi per i file, il timestamp della modifica verrà aggiornato (perché il file attributi sono cambiati), ma il timestamp modificato non si aggiornerà (perché il file contenuto non sono cambiati).
- Nascita: Riservato per mostrare la data di creazione originale del file, ma questo non è implementato in Linux.
Comprensione dei timestamp
I timestamp sono sensibili al fuso orario. il -0500 alla fine di ogni riga mostra che questo file è stato creato su un computer in a Tempo Universale Coordinato (UTC) fuso orario che è cinque ore avanti rispetto al fuso orario del computer corrente. Quindi, questo computer è cinque ore indietro rispetto al computer che ha creato questo file. In realtà, Il file è stato creato su un computer con fuso orario del Regno Unito e lo stiamo visualizzando qui su un computer nel fuso orario standard degli Stati Uniti orientale. UU.
Modificare e modificare i timestamp può causare confusione perché, per chi non lo sapesse, I loro nomi sembrano significare la stessa cosa.
Usiamo chmod per modificare i permessi del file su un file denominato ana.c. Facciamolo scrivere a tutti. Ciò non influirà sul contenuto del file, ma influenzerà gli attributi del file.
chmod +w ana.c
E poi useremo stat per vedere i timestamp:
stat ana.c
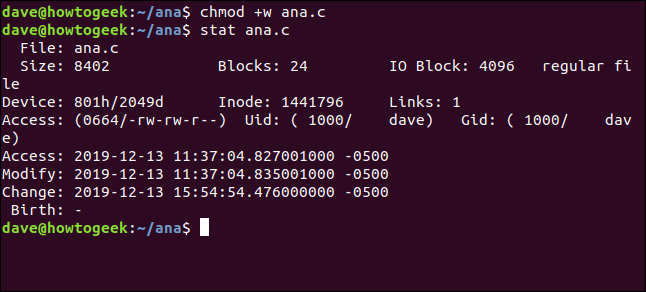
Il timestamp della modifica è stato aggiornato, ma il no modificato.
il modificato Il timestamp verrà aggiornato solo se il contenuto del file viene modificato. il modificare Il timestamp viene aggiornato sia per le modifiche al contenuto che per le modifiche agli attributi.
Utilizzo delle statistiche con molti file
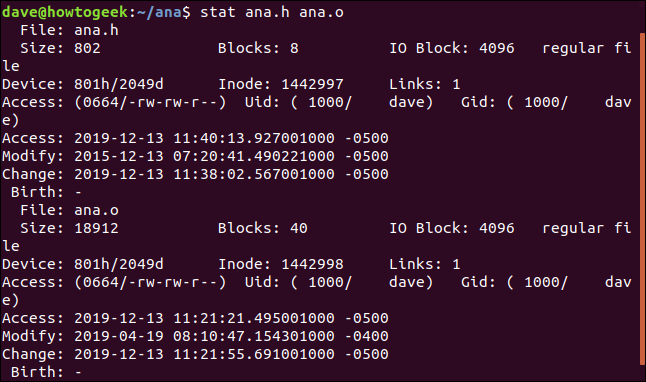
Per avere un report statistico su più file contemporaneamente, passa i nomi dei file a stat sulla riga di comando:
stat ana.h ana.o
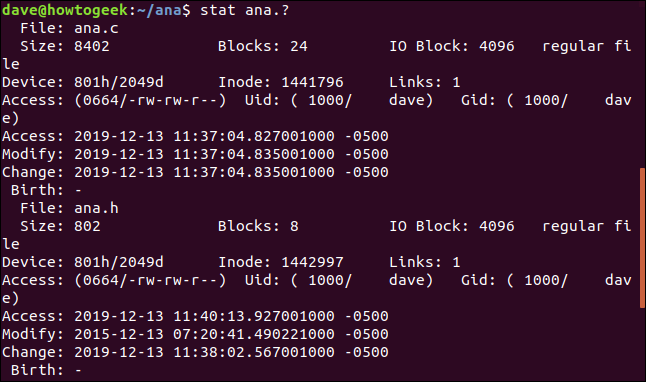
Utilizzo stat in una serie di file, usa la corrispondenza del modello. Il punto interrogativo “?” la voce per la directory corrente e la voce “*” la voce per la directory corrente e la voce. Possiamo dire stat la voce per la directory corrente e la voce “la voce per la directory corrente e la voce” la voce per la directory corrente e la voce, con questo comando:
statistica ana.?
Utilizzo delle statistiche per creare report sui file system
stat può riferire sullo stato dei file system, così come lo stato dei file. il -f (File System) opzione dice stat per segnalare il file system in cui risiede il file. la voce per la directory corrente e la voce “/” un stat invece di un nome di file.
stat -f ana.c
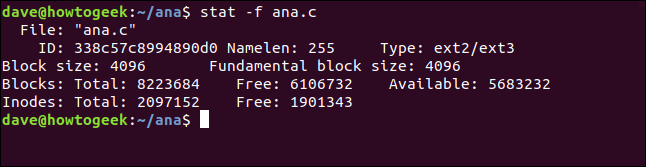
Informazione stat ci dà è:
- Procedimenti: Il nome del file.
- ID: L'ID del file system in notazione esadecimale.
- Nome: La lunghezza massima consentita per i nomi dei file.
- scrive: Il tipo di filesystem.
- Misura del blocco: La quantità di dati per richiedere richieste di lettura per velocità di trasferimento dati ottimali.
- Dimensione fondamentale del blocco: La dimensione di ogni blocco nel filesystem.
blocchi:
- Totale: Il conteggio totale di tutti i blocchi nel file system.
- Gratuito: Il numero di blocchi liberi nel file system.
- A disposizione: Il numero di blocchi gratuiti disponibili per gli utenti regolari (nessuna radice).
inode:
- Totale: Il conteggio totale degli inode nel file system.
- Gratuito: Il numero di inode liberi nel file system.
Collegamenti simbolici di dereferenziazione
Se usi stat in un file che in realtà è un collegamento simbolico, informerà sul collegamento. Sì, lo vuoi stat per informare sul file a cui punta il collegamento, Utilizzare il -L (dereferenziazione) opzione. Il file code.c è un collegamento simbolico a ana.c . Vediamolo senza di lui -L opzione:
codice statistico.c
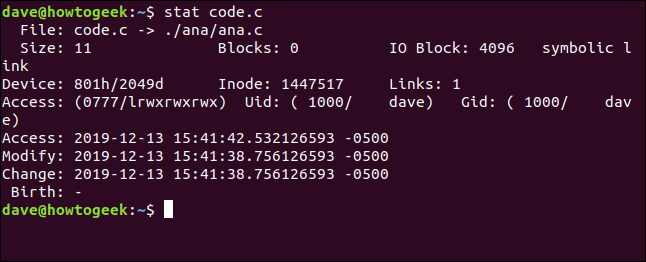
Il nome del file mostra code.c mirare a ( -> ) ana.c. La dimensione del file è solo 11 byte. Non ci sono blocchi dedicati alla memorizzazione di questo collegamento. Il tipo di file viene visualizzato come collegamento simbolico.
Chiaramente, non stiamo vedendo il file effettivo qui. Facciamolo di nuovo e aggiungiamo il -L opzione:
stat -L codice.c
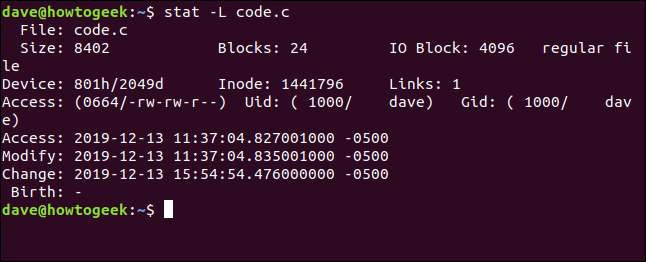
Questo ora mostra i dettagli del file per il file puntato dal collegamento simbolico. Ma nota che il nome del file è ancora dato come code.c. Questo è il nome del link, non il file di destinazione. Questo succede perché questo è il nome a cui passiamo stat sulla riga di comando.
Il resoconto sintetico
il -t (conciso) cause di opzione stat per fornire un riassunto condensato:
stat -t ana.c

Non vengono forniti indizi. Per dare un senso, fino a quando non avrai memorizzato la sequenza dei campi, devi fare un riferimento incrociato a questo output con a stat produzione.
Formati di output personalizzati
Un modo migliore per ottenere un diverso insieme di dati da stat è usare un formato personalizzato. C'è una lunga lista di token chiamati sequenze di formato. Ognuno di questi rappresenta un elemento di dati. Seleziona quelli che vuoi includere nell'output e crea una stringa di formato. Quando chiamiamo stat e passagli la stringa di formato, l'output includerà solo i dati che richiediamo.
Esistono diversi set di sequenze di formato per file e file system. L'elenco dei file è:
- %un: Diritti di accesso in octal.
- %UN: Diritti di accesso in forma leggibile dall'uomo (
rwx). - %B: Il numero di blocchi allocati.
- %B: La dimensione in byte di ogni blocco.
- %D: Il numero del dispositivo in decimale.
- %D: Il numero del dispositivo in esadecimale.
- %F: Modalità raw in esadecimale.
- %F Il tipo di file.
- %grammo: L'ID del gruppo del proprietario.
- %GRAMMO: Il nome del gruppo del proprietario.
- % h: Il numero di collegamenti fisici.
- %io: numero di inode.
- %Metro: Punto di montaggio.
- %Nord: Il nome del file.
- %NORD: Il nome del file tra virgolette, con il nome del file senza riferimento se si tratta di un collegamento simbolico.
- % oh: Il suggerimento sulla dimensione del trasferimento di E / S ottimale.
- %S: Dimensione complessiva, e byte.
- % T: Il tipo di dispositivo principale in esadecimale, per i file speciali del dispositivo a caratteri / blocchi.
- % T: Il tipo di dispositivo minore in esadecimale, per i file speciali del dispositivo a caratteri / blocchi.
- % tu: ID utente proprietario.
- % tu: Il nome utente del proprietario.
- % w: L'ora di nascita del file, leggibile dall'uomo o un trattino "-" se sconosciuto.
- % W: L'ora di nascita del file, secondi dall'ora; 0 se sconosciuto.
- %X: L'ora dell'ultimo accesso, leggibile dagli umani.
- %X: L'ora dell'ultimo accesso, secondi dall'ora.
- % e: L'ora dell'ultima modifica dei dati, leggibile dagli umani.
- % E: L'ora dell'ultima modifica dei dati, secondi dall'ora.
- % Insieme a: L'ora dell'ultimo cambio di stato, leggibile dagli umani.
- % INSIEME A: L'ora dell'ultimo cambio di stato, secondi dall'ora.
Il “la voce per la directory corrente e la voce” è il Era Unix, che ha avuto luogo il 1 di gennaio di 1970 a 00:00:00 + 0000 (UTC).
Per file system, le sequenze di formato sono:
- %un: Il numero di blocchi gratuiti disponibili per gli utenti regolari (nessuna radice).
- %B: I blocchi totali di dati nel file system.
- %C: Gli inode totali nel file system.
- %D: Il numero di inode liberi nel file system.
- %F: Il numero di blocchi liberi nel file system.
- %io: L'ID del file system in esadecimale.
- % io: La lunghezza massima dei nomi dei file.
- %Nord: Il nome del file.
- %S: Misura del blocco (la dimensione di scrittura ottimale).
- %S: La dimensione dei blocchi del filesystem (per il conteggio dei blocchi).
- % T: Il tipo di file system in esadecimale.
- % T: tipo di file system in formato leggibile dall'uomo.
Ci sono due opzioni che accettano stringhe di sequenze di formato. Questi sono --format e --printf. La differenza tra loro è --printf interpretare Sequenze di escape in stile C come nuova linea n e tab t e non aggiunge automaticamente un carattere di nuova riga al suo output.
Creiamo una stringa di formato e passiamola a stat. Le sequenze di formato da utilizzare sono %n per il nome del file, %s per la dimensione del file e %F per tipo di file. Stiamo per aggiungere il n sequenza di escape alla fine della stringa per assicurarsi che ogni file venga gestito su una nuova riga. La nostra stringa di formato è simile a questa:
"Il file %n è %s byte, ed è un %Fn"
Lo trasmetteremo a stat usando il --printf opzione. Chiediamo stat per riferire su un file chiamato code.c e una serie di file corrispondenti ana.?. Questo è il comando completo. la voce per la directory corrente e la voce “=” Tra --printf e la stringa di formato:
stat --printf="Il file %n è %s byte, ed è un %Fn" code.c ana/ana.?
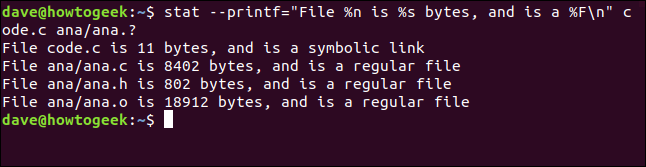
Il rapporto per ogni file viene visualizzato su una nuova riga, cosa chiediamo. Il nome del file, la dimensione del file e il tipo di file ci vengono forniti.
I formati personalizzati ti danno accesso a un numero ancora maggiore di elementi di dati rispetto a quelli inclusi nello standard stat produzione.
Control de grano fino
Come potete vedere, c'è molto spazio per estrarre i dati particolari che ti interessano. Probabilmente puoi anche capire perché suggeriamo di usare alias per gli incantesimi più lunghi e complessi..





