
Si desea fusionar datos de dos archivos de texto haciendo coincidir un campo común, puoi usare linux join comando. Aggiungi un pizzico di brio ai tuoi file di dati statici. Ti mostreremo come usarlo.
Corrispondenza dei dati tra i file
I dati sono re. corporazioni, le imprese e le famiglie lo gestiscono. Ma i dati archiviati in file diversi e raccolti da persone diverse sono una seccatura. Allo stesso tempo sapere quali file aprire per trovare le informazioni che desideri, è probabile che il layout e il formato dei file siano diversi.
Inoltre devi affrontare il mal di testa amministrativo di quali file devono essere aggiornati, quali dovrebbero essere supportati?, quali sono ereditati e quali possono essere archiviati.
Allo stesso tempo, se hai bisogno di consolidare i tuoi dati o eseguire alcune analisi su un set di dati completo, ha un ostacolo in più. Come razionalizzi i dati nei diversi file prima di poter fare ciò che devi fare con loro?? Come affronti la fase di preparazione dei dati??
La buona notizia è che se i file condividono almeno un elemento di dati comune, Linux join Il comando può tirarti fuori dal fango.
File di dati
Tutti i dati che utilizzeremo per dimostrare l'uso del join Il comando è fittizio, iniziando con i seguenti due file:
cat file-1.txt
cat file-2.txt
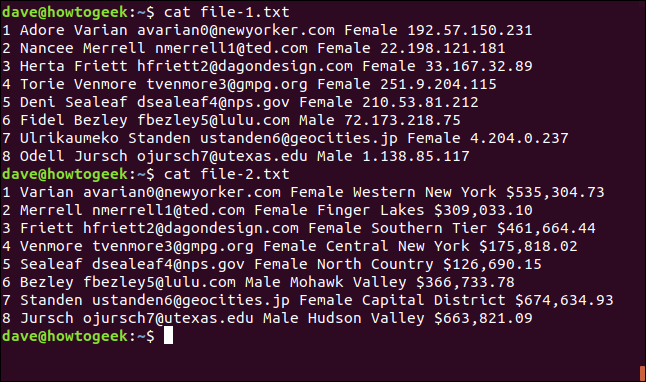
Quello che segue è il contenuto di file-1.txt:
1 Adoro Varian [email protected] Femmina 192.57.150.231 2 Nancee Merrell [email protected] Femmina 22.198.121.181 3 Herta Friett [email protected] Femmina 33.167.32.89 4 Torie Venmore [email protected] Femmina 251.9.204.115 5 Deni Sealeaf [email protected] Femmina 210.53.81.212 6 Fidel Bezley [email protected] Maschio 72.173.218.75 7 Ulrikaumeko Standen [email protected] Femmina 4.204.0.237 8 Odell Jursch [email protected] Male 1.138.85.117
Abbiamo una serie di righe numerate e ogni riga contiene tutte le informazioni successive:
- Un numero
- Un nome
- Un cognome
- Un indirizzo email
- Il sesso della persona
- Un indirizzo IP
Quello che segue è il contenuto di file-2.txt:
1 Varian [email protected] Donna New York occidentale $535,304.73 2 Merrell [email protected] Finger Lakes femminili $309,033.10 3 Friett [email protected] Femmina di livello meridionale $461,664.44 4 Venmore [email protected] Femmina centro di New York $175,818.02 5 Sealeaf [email protected] Femmina North Country $126,690.15 6 Bezley [email protected] Male Mohawk Valley $366,733.78 7 Standen [email protected] Distretto Capitale Femminile $674,634.93 8 Jursch [email protected] Male Hudson Valley $663,821.09
Ogni riga in file-2.txt contiene le informazioni successive:
- Un numero
- Un cognome
- Un indirizzo email
- Il sesso della persona
- Una regione di New York
- Un valore in dollari
il join El comando funciona con “campi”, Quello, in tale contesto, indica una sezione di testo circondata da spazi vuoti, l'inizio di una riga o la fine di una riga. Per join per abbinare le linee tra i due file, ogni riga deve contenere un campo comune.
Perché, possiamo abbinare un campo solo se appare in entrambi i file. L'indirizzo IP appare solo in un file, quindi non va bene. Il nome appare solo in un file, quindi non possiamo usarlo neanche noi. Il cognome è in entrambi i file, ma sarebbe una pessima scelta, visto che persone diverse hanno lo stesso cognome.
Inoltre, non puoi collegare i dati a voci maschili e femminili, perché sono troppo vaghi. Le regioni di New York e i valori in dollari vengono visualizzati solo in un file plus.
Nonostante questo, possiamo usare l'indirizzo email perché è presente in entrambi i file e ognuno è unico per un individuo. Una rapida occhiata ai file conferma anche che le righe in ciascuno corrispondono alla stessa persona., quindi possiamo usare i numeri di riga come nostro campo da abbinare (useremo un campo diverso in seguito).
Nota che ci sono un diverso numero di campi nei due file, quale è giusto, possiamo dire join quale campo usare da ogni file.
Nonostante questo, stai attento con campi come le regioni di New York; in un file separato da spazi, ogni parola nel nome di una regione sembra un campo. Perché alcune regioni hanno due o tre nomi di parole, in realtà ha un numero diverso di campi all'interno dello stesso file. Questo è buono, purché i campi che appaiono sulla riga prima che le regioni di New York corrispondano.
Il comando join
Primo, il campo da abbinare deve essere ordinato. Abbiamo numeri crescenti in entrambi i file, quindi soddisfiamo quel criterio. Predefinito, join usa il primo campo di un file, Cosa vogliamo. Un'altra impostazione predefinita ragionevole è che join aspettati che i separatori di campo siano spazi vuoti. Ancora, abbiamo quello, così possiamo andare avanti e accendere join.
Come usiamo tutte le impostazioni predefinite, il nostro comando è semplice:
unisci file-1.txt file-2.txt
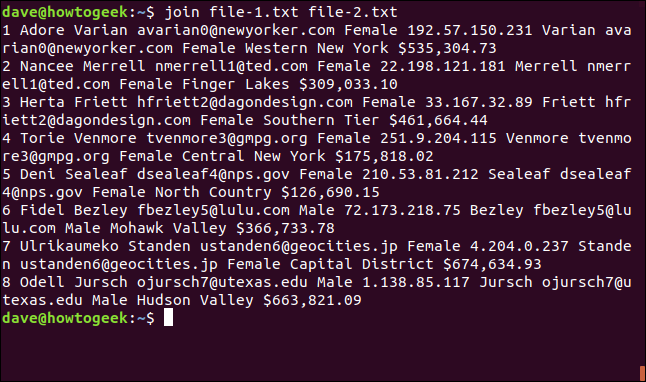
join considera que los archivos son “archivo uno” e “archivo dos” según el orden en el que aparecen en la línea de comandos.
il risultato è il seguente:
1 Adoro Varian [email protected] Femmina 192.57.150.231 Varian [email protected] Donna New York occidentale $535,304.73 2 Nancee Merrell [email protected] Femmina 22.198.121.181 Merrell [email protected] Finger Lakes femminili $309,033.10 3 Herta Friett [email protected] Femmina 33.167.32.89 Friett [email protected] Femmina di livello meridionale $461,664.44 4 Torie Venmore [email protected] Femmina 251.9.204.115 Venmore [email protected] Femmina centro di New York $175,818.02 5 Deni Sealeaf [email protected] Femmina 210.53.81.212 Sealeaf [email protected] Femmina North Country $126,690.15 6 Fidel Bezley [email protected] Maschio 72.173.218.75 Bezley [email protected] Male Mohawk Valley $366,733.78 7 Ulrikaumeko Standen [email protected] Femmina 4.204.0.237 Standen [email protected] Distretto Capitale Femminile $674,634.93 8 Odell Jursch [email protected] Male 1.138.85.117 Jursch [email protected] Male Hudson Valley $663,821.09
L'output è formattato come segue: Viene stampato per primo il campo in cui sono state abbinate le righe, seguito dagli altri campi del file uno, e poi i campi del file due senza il campo di confronto.
Campi non categorizzati
Proviamo qualcosa che sappiamo non funzionerà. Metteremo le righe in un file fuori ordine per join non sarà in grado di elaborare correttamente il file. Il contenuto di file-3.txt sono uguali a file-2.txt, ma la riga otto è tra le righe cinque e sei.
Quello che segue è il contenuto di file-3.txt:
1 Varian [email protected] Donna New York occidentale $535,304.73 2 Merrell [email protected] Finger Lakes femminili $309,033.10 3 Friett [email protected] Femmina di livello meridionale $461,664.44 4 Venmore [email protected] Femmina centro di New York $175,818.02 5 Sealeaf [email protected] Femmina North Country $126,690.15 8 Jursch [email protected] Male Hudson Valley $663,821.09 6 Bezley [email protected] Male Mohawk Valley $366,733.78 7 Standen [email protected] Distretto Capitale Femminile $674,634.93
Scriviamo il seguente comando per provare a partecipare file-3.txtper file-1.txt:
unisci file-1.txt file-3.txt
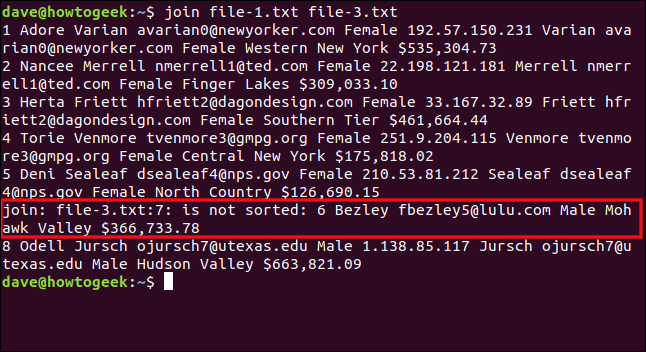
join riporta che la settima riga in file-3.txt È fuori servizio, quindi non viene elaborato. La riga sette è quella che inizia con il numero sei, che deve venire prima delle otto in un elenco correttamente ordinato. La sesta riga del file (iniziando con "8 Odell") è stato l'ultimo elaborato, così vediamo il risultato.
Puoi usare il --check-order opzione se fai finta di vedere se join sei soddisfatto dell'ordinamento dei file; non verrà fatto alcun tentativo di combinarli.
Per farlo, scriviamo quanto segue:
join --check-order file-1.txt file-3.txt
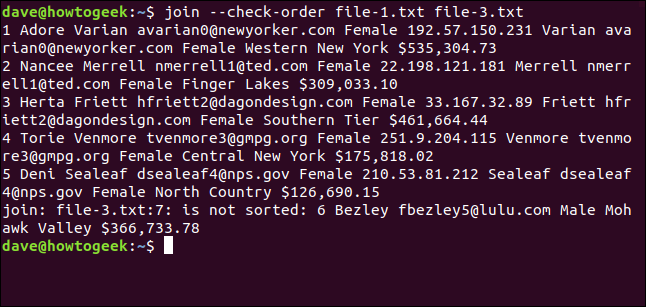
join ti dice in anticipo che ci sarà un intoppo con la riga sette del file file-3.txt.
File con righe mancanti
Sopra file-4.txt, l'ultima riga è stata rimossa, quindi non c'è la riga otto. I contenuti sono i seguenti:
1 Varian [email protected] Donna New York occidentale $535,304.73 2 Merrell [email protected] Finger Lakes femminili $309,033.10 3 Friett [email protected] Femmina di livello meridionale $461,664.44 4 Venmore [email protected] Femmina centro di New York $175,818.02 5 Sealeaf [email protected] Femmina North Country $126,690.15 6 Bezley [email protected] Male Mohawk Valley $366,733.78 7 Standen [email protected] Distretto Capitale Femminile $674,634.93
Scriviamo quanto segue e, sorprendentemente, join non si lamenta ed elabora tutte le righe che può:
unisci file-1.txt file-4.txt
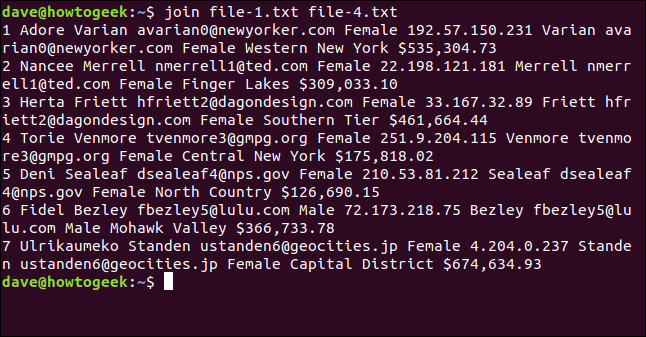
L'output elenca sette linee unite.
il -a L'opzione (la stampa non può essere abbinata) indica join per stampare anche le righe che non possono corrispondere.
Qui, scriviamo il seguente comando per dirlo join per stampare le righe del file uno che non possono corrispondere alle righe del file due:
unirsi a 1 file-1.txt file-4.txt
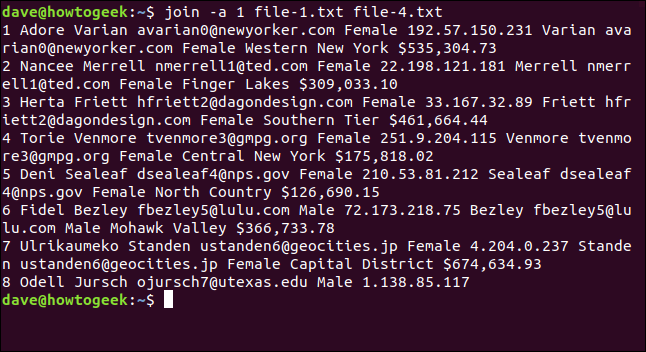
Sette righe corrispondono e la riga otto del file viene stampata, nessuna coincidenza. Non ci sono informazioni combinate perché file-4.txt non conteneva una riga otto che potesse corrispondere. Nonostante questo, almeno appare ancora nell'output così sai che non hai una corrispondenza in file-4.txt.
Scriviamo quanto segue -v (sopprimere le linee unite) per rivelare le linee non corrispondenti:
join -v file-1.txt file-4.txt

Vediamo che la riga otto è l'unica che non ha una corrispondenza nel file due.
Corrispondenza con altri campi
Associamo due nuovi file in un campo diverso da quello predefinito (campo uno). Quello che segue è il contenuto del file-7.txt:
[email protected] Femmina 192.57.150.231 [email protected] Femmina 210.53.81.212 [email protected] Maschio 72.173.218.75 [email protected] Femmina 33.167.32.89 [email protected] Femmina 22.198.121.181 [email protected] Male 1.138.85.117 [email protected] Femmina 251.9.204.115 [email protected] Femmina 4.204.0.237
E quello che segue è il contenuto del file-8.txt:
[email protected] New York occidentale $535,304.73 Femmina [email protected] North Country $126,690.15 Maschio [email protected] Mohawk Valley $366,733.78 Femmina [email protected] Livello sud $461,664.44 Femmina [email protected] Finger Lakes $309,033.10 Maschio [email protected] Hudson Valley $663,821.09 Femmina [email protected] New York centrale $175,818.02 Femmina [email protected] Distretto Capitale $674,634.93
L'unico campo sensato che può essere utilizzato per partecipare è l'indirizzo email, che è il campo uno nel primo file e il campo due nel secondo. Per adattarsi a questo, possiamo usare il -1 (archiviare un campo) e -2 (file a due campi) opzioni. Seguiremo questi con un numero che indica quale campo in ogni file dovrebbe essere usato per unirsi.
Scriviamo quanto segue per contare join per usare il primo campo nel file uno e il secondo nel file due:
aderire -1 1 -2 2 file-7.txt file-8.txt
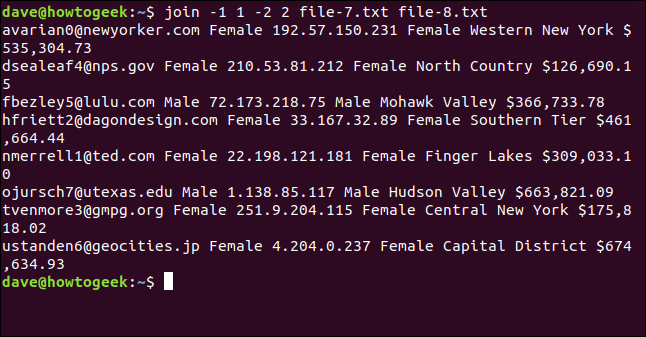
I file si uniscono nell'indirizzo e-mail, visualizzato come primo campo di ogni riga nell'output.
Utilizzo di divisori di campo diversi
Cosa succede se hai file con campi separati da qualcosa di diverso dagli spazi??
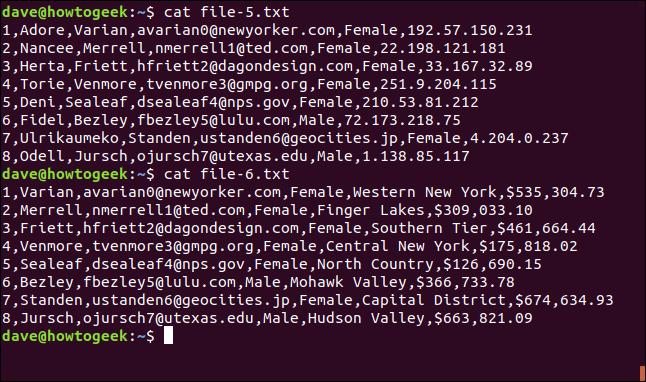
I seguenti due file sono delimitati da virgole; l'unico spazio bianco è tra i nomi di luoghi composti da più parole:
cat file-5.txt
cat file-6.txt
Possiamo usare il -t (carattere separatore) dire join quale carattere usare come separatore di campo. In questa circostanza, è la virgola?, quindi scriviamo il seguente comando:
giunto, file-5.txt file-6.txt
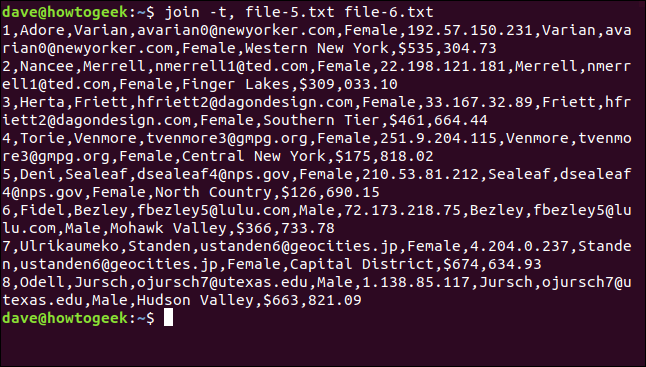
Tutte le linee corrispondono e gli spazi sono conservati nei nomi dei luoghi.
Ignora maiuscole e minuscole
Altro file, file-9.txt, è quasi identico a file-8.txt. L'unica differenza è che alcuni indirizzi e-mail hanno una lettera maiuscola, come mostrato di seguito:
[email protected] New York occidentale $535,304.73 Femmina [email protected] North Country $126,690.15 Maschio [email protected] Mohawk Valley $366,733.78 Femmina [email protected] Livello sud $461,664.44 Femmina [email protected] Finger Lakes $309,033.10 Male [email protected] Hudson Valley $663,821.09 Femmina [email protected] New York centrale $175,818.02 Femmina [email protected] Distretto Capitale $674,634.93
Quando ci riuniamo file-7.txt e file-8.txt, ha funzionato alla grande. Vediamo cosa succede con file-7.txt e file-9.txt.
Scriviamo il seguente comando:
aderire -1 1 -2 2 file-7.txt file-9.txt
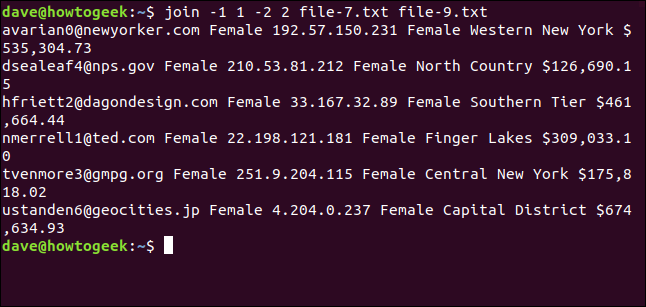
Abbiniamo solo sei righe. Le differenze tra lettere maiuscole e minuscole hanno impedito l'unione degli altri due indirizzi e-mail.
Nonostante questo, possiamo usare il -i (ignora maiuscole e minuscole) opzione per forzare join ignorare quelle differenze e abbinare i campi che contengono lo stesso testo, indipendentemente dal caso.
Scriviamo il seguente comando:
aderire -1 1 -2 2 -i file-7.txt file-9.txt
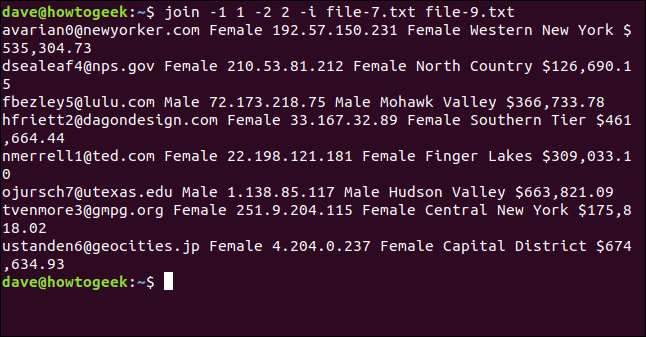
Tutte le otto linee sono correttamente combinate e unite.
Mescolare e abbinare
Sopra join, hai un potente alleato quando stai lottando con una preparazione dei dati imbarazzante. Forse hai bisogno di analizzare i dati, o tal vez esté tratando de darles forma para realizar una importación a un sistema distinto.
No importa cuál sea la situación, se alegrará de tener join en tu esquina!





