Ogni volta che viene creata una procedura su un sistema Linux, gli viene assegnato un nuovo numero che lo identifica rispetto ad altre applicazioni. Questo è l'ID della procedura, o PID, e viene utilizzato in tutto il sistema per gestire i processi in esecuzione.
Come funzionano i processi in Linux
Viene chiamata la prima procedura eseguita da Linux systemd, ricezione PID 0. Tutti gli altri processi sono generati come figli di systemd. I primi generalmente saranno cose Linux di basso livello di cui non devi preoccuparti, ma più in basso nell'albero, il sistema inizierà a lanciare processi a livello utente come MySQL e Nginx.
Ogni procedura ha anche un PPID, che memorizza il PID del genitore da cui è stata creata la procedura. Esiste anche un processo TTY, che memorizza l'ID del terminale che hai utilizzato per avviare la procedura, e UID, che memorizza l'ID dell'utente che lo ha creato. Viene chiamata qualsiasi procedura a cui generalmente manca un TTY diavolo, una definizione utilizzata per indicare i processi di sistema che vengono eseguiti in background e non dispongono di un terminale di controllo.
Ogni volta che una procedura viene chiusa, che il PID è abilitato per l'uso da un'altra procedura. Ogni procedura si chiude anche con un codice di uscita, che viene generalmente utilizzato per indicare se si è verificato o meno un errore. Il codice di uscita 0 è un'uscita pulita, qualcosa di più grande è un errore specifico.
In una nota più tecnica, I PID sono una parte importante degli spazi dei nomi di Linux. Gli spazi dei nomi nascondono alcune parti del sistema dai processi in esecuzione in spazi dei nomi diversi, ciò che alimenta gli strumenti di containerizzazione come Docker. Con gli spazi dei nomi, l'albero PID viene tagliato su un certo ramo, e solo quella succursale viene consegnata alla procedura containerizzata. Questo ramo riparte dal PID 1, quindi il contenitore sembra essere in esecuzione su una nuovissima installazione di Linux.
Processi di visualizzazione
Per un elenco completo dei processi, può eseguire il ps comando:
sudo ps -e
Che genererà un elenco molto lungo di tutti i processi in esecuzione, che è certamente un po' difficile da navigare.
È possibile filtrare i risultati reindirizzando l'output a grep, Che cosa ps non ha una funzione di ricerca integrata:
sudo ps -e | grep "nome del processo"
Anche se dovresti essere avvertito che, abbastanza strano, questo corrisponderà anche al nuovo creato grep processi, Che cosa ps mostra gli argomenti del comando, che includono la stringa corrispondente, che evidentemente corrisponde a se stesso. Se è necessario solo il PID di un determinato nome di procedura, il pgrep Il comando restituisce solo il PID e nient'altro.
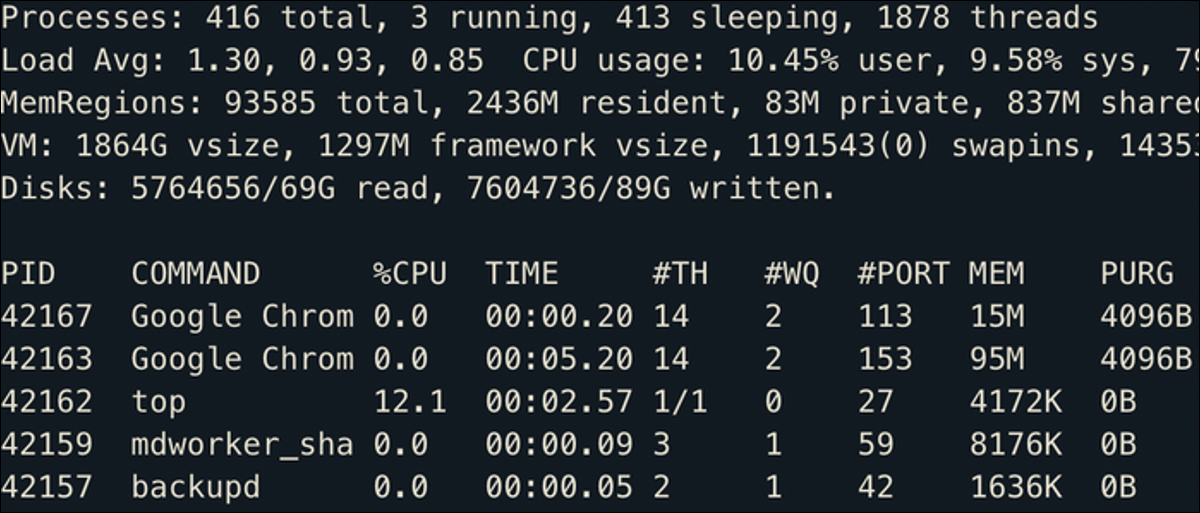
Un visualizzatore molto più utile è il top comando, che funge da Task Manager dal tuo terminale. Mostra tutti i processi ordinati per utilizzo della CPU, così come alcune statistiche generali di sistema:
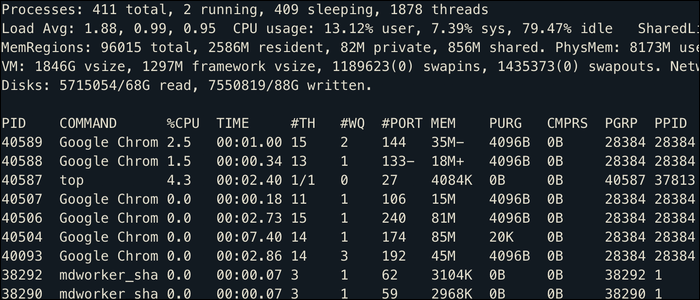
Se stai utilizzando un desktop Linux, questo mostra anche le applicazioni in esecuzione al momento, anche se la maggior parte delle applicazioni sarà multi-thread, quindi Google Chrome popola questo elenco in esecuzione in più processi con diversi PID.
Interrompi processi
Essere realistici, non farà molto con la procedura effettiva oltre a spegnerlo, visto che non dovrai gestire la creazione della procedura. (Gestito automaticamente quando si esegue un comando o uno script). Il comando per farlo si chiama succintamente kill, che prende un dato PID e chiude quella procedura:
sudo kill 40589
Inoltre puoi uccidere tutti i processi con un dato nome usando il killall comando. Come esempio, per liberare un po' di RAM nel sistema, può eseguire:
sudo killall chrome
Evidentemente, questo non è il modo migliore per chiudere le applicazioni desktop, ma la maggior parte dei processi non genererà molto clamore se vengono chiusi in questo modo.
Nonostante questo, se la procedura è un servizio Linux, vorrai usare il service comando per interagire con esso. Come esempio, ricaricare nginx:
servizio nginx ricarica
Oppure spegnilo:
servizio nginx stop
File PID
Un ID di procedura identifica in modo univoco una procedura solo mentre quella procedura è in esecuzione. Se devi riavviare Nginx, è possibile che gli venga assegnato un nuovo ID di procedura.
È qui che entrano in gioco i file PID; sono una forma di comunicazione tra processi, essenzialmente un file che memorizza il PID corrente di una determinata procedura. Un'altra procedura può leggere questo file e intrinsecamente sapere, come esempio, qual è il PID di MySQL. All'avvio di MySQL, scrivi il tuo PID su questo file affinché l'intero sistema lo veda.
Generalmente, I file PID sono memorizzati in /var/run/, anche se questa è solo una pratica comune e non un requisito, simile a come vengono archiviati i file di registro in /var/log/.
La maggior parte dei processi con file PID ne avrà anche uno in esecuzione contemporaneamente, cosa si fa con l'aiuto dei file di blocco. I file di blocco sono un modo per determinare un flag che consente l'avvio di una sola procedura alla volta. Quando viene avviata una procedura come Nginx, controlla se il file di blocco esiste e, Se non è così, inizierà normalmente. Ma se è già lì, Nginx genererà un errore e si rifiuterà di iniziare.





