
Tengo un procedimiento en el que necesito copiar todas las imágenes de una página web. Solía ejecutar este procedimiento con xmllint, que procesará un archivo XML o HTML e imprimirá las entradas que especifique. Pero cuando mi proveedor de host de servidor actualizó sus sistemas, no incluyeron xmllint. Entonces tuve que hallar otra manera de extraer una lista de imágenes de una página HTML. Resulta que puedes hacer esto en Bash.
Puede que no crea que Bash pueda analizar archivos de datos, pero puede hacerlo con un pensamiento inteligente. Bash, del mismo modo que otros shells de UNIX anteriores, puede analizar las líneas de una en una desde un archivo a través de la función incorporada read declaración.
Por defecto, el read declaración escanea una línea de datos y la divide en campos. De forma general, read divide los campos usando espacios y tabulaciones, con nuevas líneas al final de cada línea, pero puede cambiar esta conducta configurando el Separador de campo interno (IFS) valor y el delimitador de final de línea (-d).
Para analizar un archivo HTML usando read , selecciona el IFS a un símbolo mayor que (>) y el delimitador a un símbolo menor que (<). Cada vez que Bash escanea una línea, analiza hasta la próxima < (el comienzo de una etiqueta HTML) después divide esos datos en cada > (el final de una etiqueta HTML). Este código de muestra toma una línea de entrada y divide los datos en TAG y VALUE variables:
local IFS='>' read -d '<' TAG VALUE
Exploremos cómo funciona esto. Considere este simple archivo HTML:
<img src="https://www.systempeaker.com/8315/parsing-html-in-bash/logo.png" alt="My logo" /> <p>some text</p>
La primera vez read analiza este archivo, se detiene en el primer < símbolo. Puesto que < es el primer carácter de esta entrada de muestra, lo que significa que Bash encuentra una cadena vacía. La resultante TAG y VALUE las cadenas además están vacías. Pero eso está bien para mi caso de uso.
La próxima vez que Bash lee la entrada, obtiene img src="https://www.systempeaker.com/8315/parsing-html-in-bash/logo.png"↲alt="My logo" />↲ con una nueva línea justo antes de la alt, y se detiene antes de la < símbolo en la próxima línea. Después read divide la línea en el > símbolo, que deja TAG con img src="https://www.systempeaker.com/8315/parsing-html-in-bash/logo.png"↲alt="My logo" / y VALUE con una nueva línea vacía.
La tercera vez read analiza el archivo HTML, obtiene p>some text. Bash divide la cuerda en el > Resultando en TAG conteniendo p y VALUE con some text .
Ahora que comprendes cómo utilizar read, es fácil analizar un archivo HTML más largo con Bash. Comience con una función Bash llamada xmlgetnext para analizar los datos usando read , dado que lo hará una y otra vez en el guión. Nombré mi función xmlgetnext para recordarme que este es un reemplazo para Linux xmllint programa, pero podría haberlo llamado con la misma facilidad htmlgetnext .
xmlgetnext () {
local IFS='>'
read -d '<' TAG VALUE
}
Ahora llama a eso xmlgetnext función para analizar el archivo HTML. Esta es mi completa htmltags texto:
#!/bin/sh
# print a list of all html tags
xmlgetnext () {
local IFS='>'
read -d '<' TAG VALUE
}
cat $1 | while xmlgetnext ; do echo $TAG ; done
La última línea es la clave. Recorre el archivo usando xmlgetnext para analizar el HTML e imprime solo el TAG entradas. Y por como echo opera con los separadores de campo estándar, cualquier línea como img src="https://www.systempeaker.com/8315/parsing-html-in-bash/logo.png"↲alt="My logo" / que contienen una nueva línea se imprimen en una sola línea, como img src="https://www.systempeaker.com/8315/parsing-html-in-bash/logo.png" alt="My logo" /.
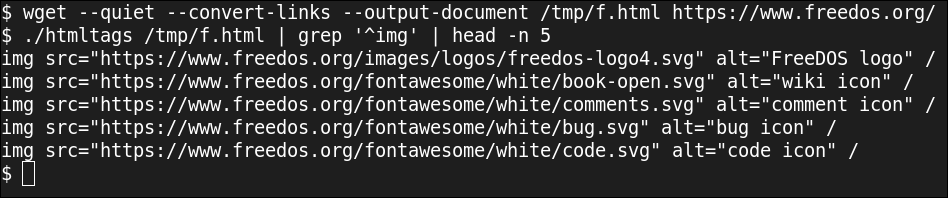
Para obtener solo la lista de imágenes, ejecuto la salida de este script a través de grep para imprimir solo las líneas que disponen un img etiqueta al comienzo de la línea.





