
Los formatos en columnas, como Apache Parquet, ofrecen grandes ahorros de compresión y son mucho más fáciles de escanear, procesar y analizar que otros formatos como CSV. En este post, le mostramos cómo convertir sus datos CSV a Parquet usando AWS Glue.
¿Qué es un formato columnar?
Los archivos CSV, los archivos de registro y cualquier otro archivo delimitado por caracteres almacenan datos de forma eficaz en columnas. Cada fila de datos tiene un cierto número de columnas, todas separadas por el delimitador, como comas o espacios. Pero bajo el capó, estos formatos siguen siendo solo líneas de cuerdas. No existe una forma simple de escanear una sola columna de un archivo CSV.
Esto puede ser un obstáculo con servicios como AWS Athena, que pueden ejecutar consultas SQL en datos almacenados en CSV y otros archivos delimitados. Inclusive si solo está consultando una sola columna, Athena tiene que escanear el completo contenido del archivo. El único cargo de Athena son los GB de los datos procesados, por lo que incrementar la factura procesando datos innecesarios no es la mejor idea.
La respuesta es un verdadero formato columnar. Los formatos de columnas almacenan datos en columnas, del mismo modo que una base de datos relacional tradicional. Las columnas se almacenan juntas y los datos son mucho más homogéneos, lo que los hace más fáciles de comprimir. Son no exactamente legible por humanos, pero son entendidos por la aplicación que los procesa sin problemas. En realidad, debido a que hay menos datos para escanear, son mucho más fáciles de procesar.
Debido a que Athena solo tiene que escanear una columna para hacer una selección por columna, reduce drásticamente los costos, especialmente para conjuntos de datos más grandes. Si tiene 10 columnas en cada archivo y solo escanea una, eso significa un ahorro de costos del 90% con solo cambiar a Parquet.
Convierta automáticamente con AWS Glue
AWS Glue es una herramienta de Amazon que convierte conjuntos de datos entre formatos. Se utiliza principalmente como parte de una canalización para procesar datos almacenados en formatos delimitados y otros, y los inyecta en bases de datos para su uso en Athena. Aunque se puede configurar para que sea automático, además puede ejecutarlo manualmente y, con algunos ajustes, se puede utilizar para convertir archivos CSV al formato Parquet.
Diríjase a la consola de AWS Glue y seleccione «Comenzar». En la barra lateral, haga clic en «Agregar rastreador» y cree un nuevo rastreador. El rastreador está configurado para buscar datos de Cucharones S3e importe los datos a una base de datos para utilizarlos en la conversión.
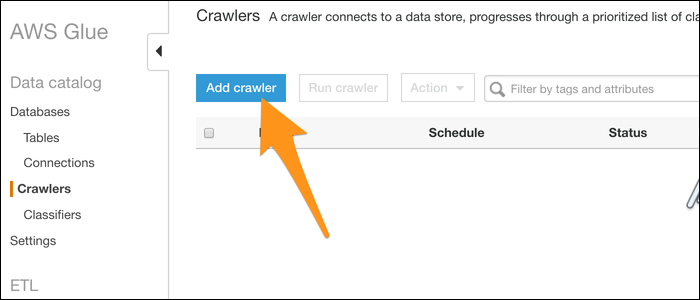
Asigne un nombre a su rastreador y elija importar datos desde un almacén de datos. Seleccione S3 (aún cuando DynamoDB es otra alternativa) e ingrese la ruta a una carpeta que contenga sus archivos. Si solo tiene un archivo que desea convertir, colóquelo en su propia carpeta.
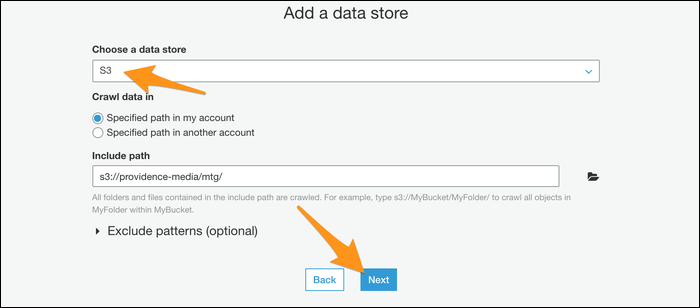
A continuación, se le pedirá que cree una función de IAM para que opere su rastreador. Cree el rol y posteriormente elíjalo de la lista. Es factible que deba presionar el botón de actualización al lado para que aparezca.
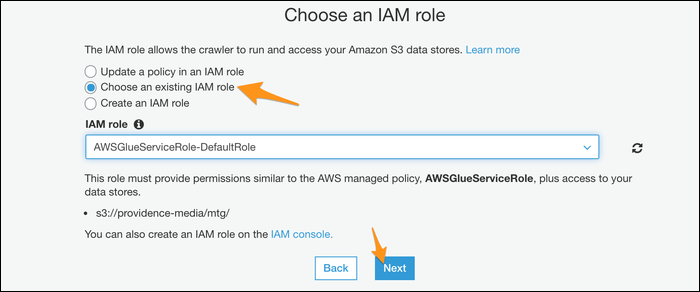
Elija una base de datos para la salida del rastreador; Si ha usado Athena antes, puede utilizar su base de datos personalizada, pero si no, la predeterminada debería funcionar bien.
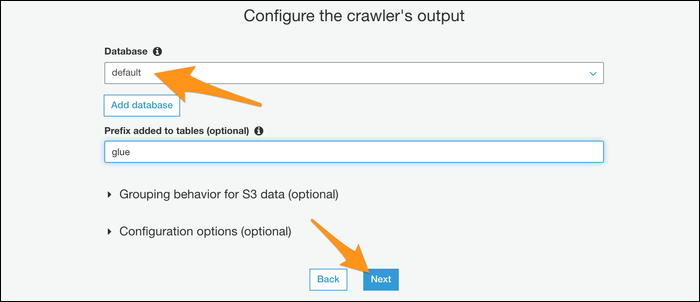
Si desea automatizar el procedimiento, puede darle a su rastreador una programación para que se ejecute de forma regular. Si no es así, elija el modo manual y ejecútelo usted mismo desde la consola.
Una vez creado, siga adelante y ejecute el rastreador para importar los datos a la base de datos que eligió. Si todo funcionó, debería ver su archivo importado con el esquema adecuado. Los tipos de datos para cada columna se asignan automáticamente en función de la entrada de origen.
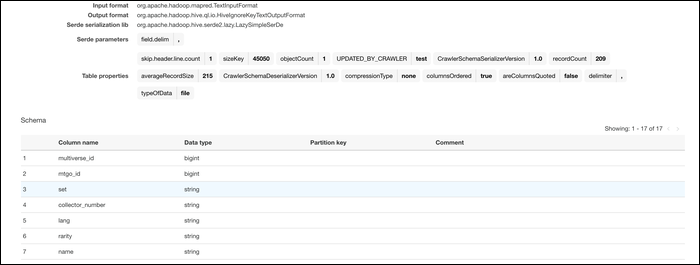
Una vez que sus datos estén en el sistema AWS, puede convertirlos. Desde Glue Console, cambie a la pestaña «Trabajos» y cree un nuevo trabajo. Asígnele un nombre, agregue su función de IAM y seleccione «Una secuencia de comandos iniciativa generada por AWS Glue» como lo que se ejecuta el trabajo.
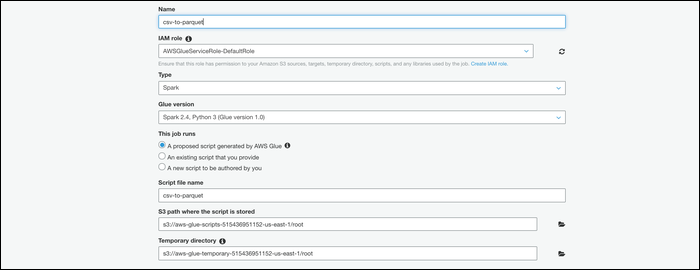
Seleccione su tabla en la próxima pantalla, posteriormente elija «Cambiar esquema» para especificar que este trabajo ejecuta una conversión.

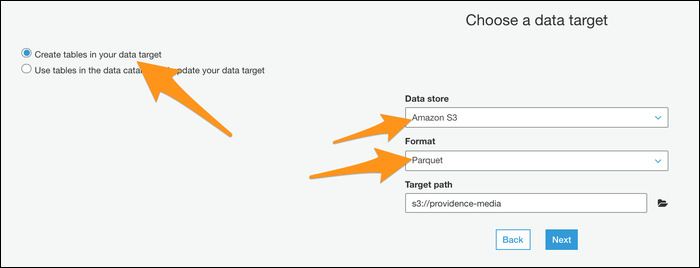
A continuación, debe elegir «Crear tablas en su destino de datos», especificar Parquet como formato e ingresar una nueva ruta de destino. Asegúrese de que esta sea una ubicación vacía sin ningún otro archivo.
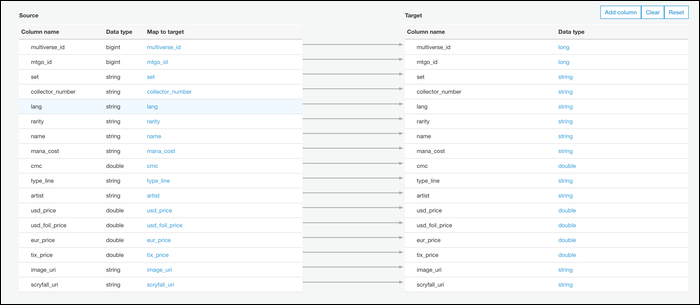
A continuación, puede editar el esquema de su archivo. Esto tiene como valor predeterminado un mapeo uno a uno de columnas CSV a columnas Parquet, que es probablemente lo que desea, pero puede modificarlo si lo necesita.
Cree el trabajo y accederá a una página que le permitirá editar la secuencia de comandos de Python que ejecuta. La secuencia de comandos predeterminada debería funcionar bien, por lo tanto presione «Guardar» y vuelva a la pestaña de trabajos.
En nuestras pruebas, la secuencia de comandos siempre fallaba a menos que el rol de IAM tuviera un permiso específico para escribir en la ubicación a la que especificamos la salida. Puede que tenga que editar manualmente los permisos desde el Consola de administración de IAM si se encuentra con el mismo problema.
Caso contrario, haga clic en «Ejecutar» y su secuencia de comandos debería iniciarse. El procedimiento puede tardar uno o dos minutos, pero debería ver el estado en el panel de información. Cuando haya terminado, verá un nuevo archivo creado en S3.
Este trabajo se puede configurar para que se ejecute fuera de los activadores establecidos por el rastreador que importa los datos, por lo que todo el procedimiento se puede automatizar de principio a fin. Si está importando registros del servidor a S3 de esta manera, este puede ser un método sencillo para convertirlos a un formato más utilizable.





