
El Linux stat El comando te muestra muchos más detalles que ls lo hace. Eche un vistazo detrás de la cortina con esta utilidad informativa y configurable. Te mostraremos cómo usarlo.
stat te lleva detrás de escena
los ls El comando es excelente en lo que hace, y hace mucho, pero con Linux, parece que siempre hay una manera de profundizar y ver qué hay debajo de la superficie. Y, a menudo, no se trata solo de levantar el borde de la alfombra. Puede romper las tablas del suelo y posteriormente cavar un agujero. Puedes pelar Linux como una cebolla.
ls le mostrará una gran cantidad de información con relación a un archivo, como qué permisos están establecidos en él, qué tan grande es y si es un archivo o un link simbólico. Para mostrar esta información ls lo lee de un estructura del sistema de archivos llamada inodo.
Cada archivo y directorio tiene un inodo. El inodo sostiene metadatos sobre el archivo, como qué bloques de sistema de archivos ocupa y las marcas de fecha asociadas con el archivo. El inodo es como una tarjeta de biblioteca para el archivo. Pero ls solo te mostrará parte de la información. Para ver todo, necesitamos utilizar el stat mando.
Igual que ls , los stat El comando tiene muchas opciones. Esto lo convierte en un gran candidato para el uso de alias. Una vez que haya descubierto un conjunto particular de alternativas que hacen stat darle el resultado que desea, envolverlo en un alias o función de shell. Esto lo hace mucho más conveniente de utilizar y no es necesario que recuerde un conjunto arcano de alternativas de línea de comandos.
RELACIONADO: Cómo utilizar el comando ls para enumerar archivos y directorios en Linux
Una comparación rápida
Usemos ls para darnos una lista larga -l opción) con tamaños de archivo legibles por humanos ( -h opción):
ls -lh ana.h

De izquierda a derecha, la información que proporciona ls es:
- El primer carácter es un guión “-” y esto nos dice que el archivo es un archivo normal y no un socket, link simbólico u otro tipo de objeto.
- El propietario, el grupo y otros permisos se enumeran en formato octal.
- El número de links físicos que apuntan a este archivo. Para este caso, y en la mayoría de los casos, será uno.
- El propietario del archivo es Dave.
- El propietario del grupo es Dave.
- El tamaño del archivo es de 802 bytes.
- El archivo fue modificado por última vez el viernes 13 de diciembre de 2015.
- El nombre del archivo es
ana.c.
Echemos un vistazo con stat :
stat ana.h
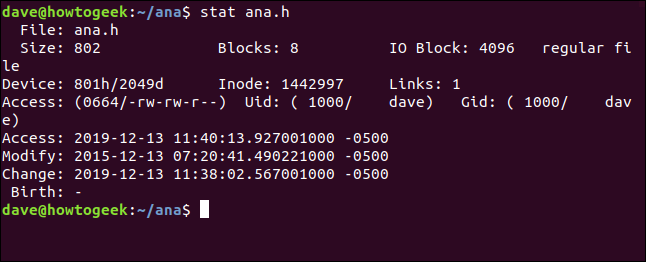
La información que obtenemos de stat es:
- Expediente: El nombre del archivo. Por lo general, es el mismo que el nombre que le pasamos.
staten la línea de comandos, pero puede ser distinto si miramos un link simbólico. - Tamaño: El tamaño del archivo en bytes.
- Bloques: El número de bloques del sistema de archivos que necesita el archivo para ser almacenado en el disco duro.
- Bloque IO: El tamaño de un bloque del sistema de archivos.
- Tipo de archivo: El tipo de objeto que describen los metadatos. Los tipos más comunes son archivos y directorios, pero además pueden ser links, sockets o canalizaciones con nombre.
- Dispositivo: El número de dispositivo en hexadecimal y decimal. Este es el ID del disco duro en el que está almacenado el archivo.
- Inodo: El número de inodo. Dicho de otra forma, el número de identificación de este inodo. Juntos, el número de inodo y el número de dispositivo identifican un archivo de forma única.
- Links: Este número indica cuántos links físicos apuntan a este archivo. Cada link físico tiene su propio inodo. Entonces, otra manera de pensar en esta figura es cuántos inodos apuntan a este archivo. Cada vez que se crea o elimina un link físico, este número se ajustará hacia arriba o hacia abajo. Cuando llega a cero, el archivo en sí se ha eliminado y el inodo se elimina. Si utiliza
staten un directorio, este número representa el número de archivos en el directorio, incluido el «.» la entrada para el directorio actual y la entrada «..» para el directorio principal. - Acceso: Los permisos de archivo se muestran en su octal y tradicional.
rwx(leer, escribir, ejecutar formatos). - Uid: ID de usuario y nombre de cuenta del propietario.
- Gid: ID de grupo y nombre de cuenta del propietario.
- Acceso: La marca de tiempo de acceso. No es tan fácil como podría parecer. Las distribuciones modernas de Linux usan un esquema llamado
relatime, que intenta optimizar las escrituras del disco duro necesarias para actualizar el tiempo de acceso. Resumidamente, el tiempo de acceso se actualiza si es anterior al tiempo modificado. - Modificar: La marca de tiempo de la modificación. Este es el momento en que el archivo contenido fueron modificados por última vez. (Por suerte, el contenido de este archivo se modificó por última vez hace cuatro años).
- Cambio: La marca de tiempo del cambio. Este es el momento en que el archivo atributos o contenido fueron modificados por última vez. Si modifica un archivo estableciendo nuevos permisos de archivo, la marca de tiempo del cambio se actualizará (debido a que el archivo atributos han cambiado), pero la marca de tiempo modificada no se actualizará (debido a que el archivo contenido no se cambiaron).
- Nacimiento: Reservado para mostrar la fecha de creación original del archivo, pero esto no está implementado en Linux.
Comprensión de las marcas de tiempo
Las marcas de tiempo son sensibles a la zona horaria. los -0500 al final de cada línea muestra que este archivo fue creado en una computadora en un Hora universal coordinada (UTC) zona horaria que se adelanta cinco horas a la zona horaria del equipo actual. Entonces, esta computadora está cinco horas detrás de la computadora que creó este archivo. En realidad, el archivo se creó en una computadora de zona horaria del Reino Unido y lo estamos viendo aquí en una computadora en la zona horaria estándar del este de EE. UU.
Las marcas de tiempo de modificación y cambio pueden causar confusión debido a que, para los no iniciados, sus nombres suenan como si significaran lo mismo.
Usemos chmod para modificar los permisos de archivo en un archivo llamado ana.c. Vamos a hacer que todos puedan escribirlo. Esto no afectará el contenido del archivo, pero afectará los atributos del archivo.
chmod +w ana.c
Y posteriormente usaremos stat para ver las marcas de tiempo:
stat ana.c
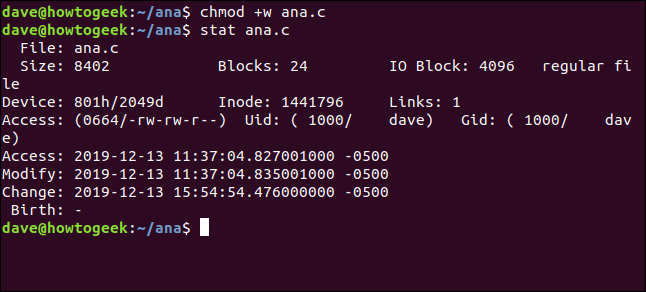
La marca de tiempo del cambio se ha actualizado, pero la modificada no.
los modificado La marca de tiempo solo se actualizará si se cambia el contenido del archivo. los cambio La marca de tiempo se actualiza tanto para los cambios de contenido como para los cambios de atributos.
Uso de estadísticas con muchos archivos
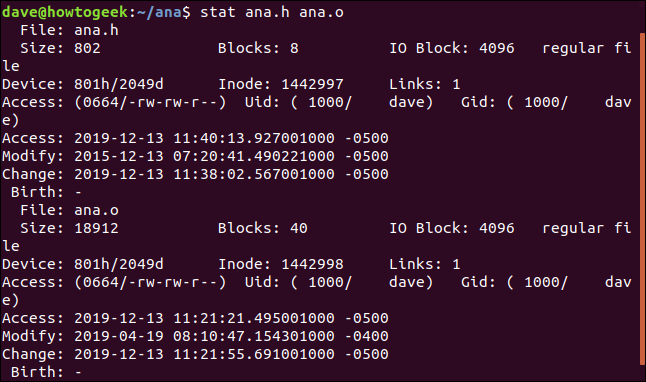
Para tener un reporte estadístico sobre varios archivos al mismo tiempo, pase los nombres de archivo a stat en la línea de comando:
stat ana.h ana.o
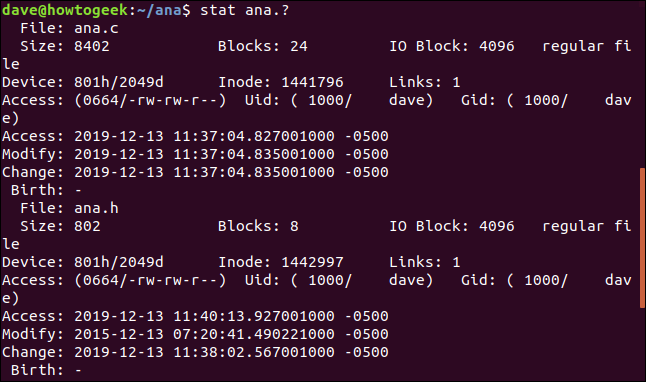
Utilizar stat en un conjunto de archivos, utilice la coincidencia de patrones. El signo de interrogación «?» representa cualquier carácter individual y el asterisco «*» representa cualquier cadena de caracteres. Podemos decir stat para informar sobre cualquier archivo llamado «ana» con una extensión de una sola letra, con este comando:
stat ana.?
Uso de estadísticas para informar sobre sistemas de archivos
stat puede informar sobre el estado de los sistemas de archivos, así como el estado de los archivos. los -f (sistema de archivos) la opción dice stat para informar sobre el sistema de archivos en el que reside el archivo. Tenga en cuenta que además podemos pasar un directorio como «/» a stat en lugar de un nombre de archivo.
stat -f ana.c
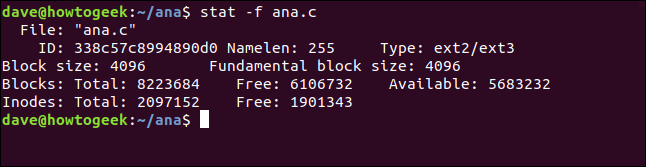
La información stat nos da es:
- Expediente: El nombre del archivo.
- IDENTIFICACIÓN: El ID del sistema de archivos en notación hexadecimal.
- Namelen: La longitud máxima permitida para los nombres de archivo.
- Escribe: El tipo de sistema de archivos.
- Tamaño de bloque: La cantidad de datos para solicitar solicitudes de lectura para obtener velocidades de transferencia de datos óptimas.
- Tamaño de bloque fundamental: El tamaño de cada bloque del sistema de archivos.
Bloques:
- Total: El recuento total de todos los bloques en el sistema de archivos.
- Gratis: El número de bloques libres en el sistema de archivos.
- Disponible: El número de bloques gratuitos disponibles para usuarios regulares (no root).
Inodos:
- Total: El recuento total de inodos en el sistema de archivos.
- Gratis: El número de inodos libres en el sistema de archivos.
Desreferenciar links simbólicos
Si utiliza stat en un archivo que en realidad es un link simbólico, informará sobre el link. Si querías stat para informar sobre el archivo al que apunta el link, utilice el -L (desreferencia) opción. El archivo code.c es un link simbólico a ana.c . Veámoslo sin el -L opción:
stat code.c
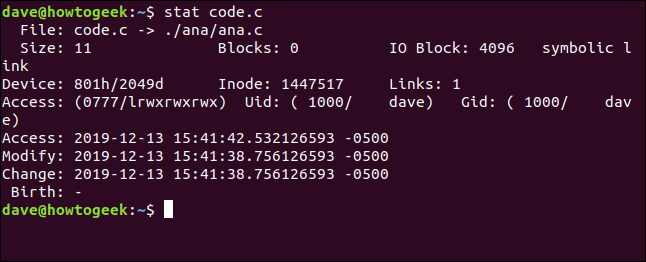
El nombre del archivo muestra code.c apuntando a ( -> ) ana.c. El tamaño del archivo es de solo 11 bytes. No hay bloques dedicados a almacenar este link. El tipo de archivo se muestra como un link simbólico.
Claramente, no estamos viendo el archivo real aquí. Hagamos eso de nuevo y agreguemos el -L opción:
stat -L code.c
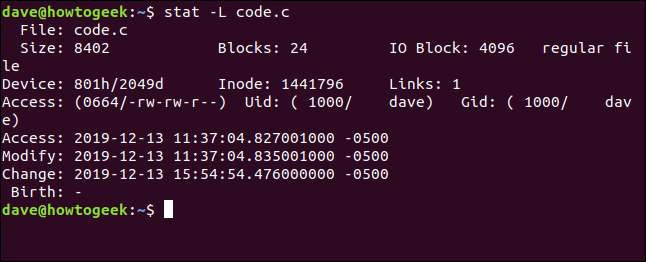
Esto ahora muestra los detalles del archivo para el archivo al que apunta el link simbólico. Pero tenga en cuenta que el nombre del archivo aún se da como code.c. Este es el nombre del link, no el archivo de destino. Esto sucede debido a que este es el nombre al que le pasamos stat en la línea de comando.
El reporte conciso
los -t (conciso) opción causas stat para proporcionar un resumen condensado:
stat -t ana.c

No se dan pistas. Para darle sentido, hasta que haya memorizado la secuencia del campo, debe hacer una referencia cruzada de esta salida a una stat producción.
Formatos de salida personalizados
Una mejor manera de obtener un conjunto distinto de datos de stat es usar un formato personalizado. Existe una larga lista de tokens llamados secuencias de formato. Cada uno de estos representa un elemento de datos. Seleccione los que desea incluir en la salida y cree una cadena de formato. Cuando llamamos stat y pasarle la cadena de formato, la salida solo incluirá los ítems de datos que solicitamos.
Existen diferentes conjuntos de secuencias de formato para archivos y sistemas de archivos. La lista de archivos es:
- %a: Los derechos de acceso en octal.
- %A: Los derechos de acceso en forma legible por humanos (
rwx). - %B: El número de bloques asignados.
- %B: El tamaño en bytes de cada bloque.
- %D: El número de dispositivo en decimal.
- %D: El número de dispositivo en hexadecimal.
- %F: El modo sin formato en hexadecimal.
- %F El tipo de archivo.
- %gramo: El ID de grupo del propietario.
- %GRAMO: El nombre del grupo del propietario.
- % h: El número de links físicos.
- %I: El número de inodo.
- %metro: El punto de montaje.
- %norte: El nombre del archivo.
- %NORTE: El nombre del archivo entre comillas, con el nombre de archivo sin referencia si es un link simbólico.
- % o: La sugerencia de tamaño de transferencia de E / S óptimo.
- %s: El tamaño total, en bytes.
- % t: El tipo de dispositivo principal en hexadecimal, para archivos especiales de dispositivos de caracteres / bloques.
- % T: El tipo de dispositivo menor en hexadecimal, para archivos especiales de dispositivo de caracteres / bloques.
- % u: ID de usuario del propietario.
- % U: El nombre de usuario del propietario.
- % w: La hora de nacimiento del archivo, legible por humanos o un guión “-” si se desconoce.
- % W: La hora de nacimiento del archivo, segundos desde la Época; 0 si se desconoce.
- %X: La hora del último acceso, legible por humanos.
- %X: La hora del último acceso, segundos desde la Época.
- % y: La hora de la última modificación de datos, legible por humanos.
- % Y: La hora de la última modificación de datos, segundos desde la Época.
- % z: La hora del último cambio de estado, legible por humanos.
- % Z: La hora del último cambio de estado, segundos desde la Época.
La «época» es la Época Unix, que tuvo lugar el 1 de enero de 1970 a las 00:00:00 + 0000 (UTC).
Para los sistemas de archivos, las secuencias de formato son:
- %a: El número de bloques gratuitos disponibles para usuarios regulares (no root).
- %B: El total de bloques de datos en el sistema de archivos.
- %C: El total de inodos en el sistema de archivos.
- %D: El número de inodos libres en el sistema de archivos.
- %F: El número de bloques libres en el sistema de archivos.
- %I: El ID del sistema de archivos en hexadecimal.
- % l: La longitud máxima de los nombres de archivo.
- %norte: El nombre del archivo.
- %s: El tamaño del bloque (el tamaño de escritura óptimo).
- %S: El tamaño de los bloques del sistema de archivos (para recuentos de bloques).
- % t: El tipo de sistema de archivos en hexadecimal.
- % T: tipo de sistema de archivos en formato legible por humanos.
Hay dos opciones que aceptan cadenas de secuencias de formato. Estos son --format y --printf. La diferencia entre ellos es --printf interpreta Secuencias de escape estilo C como nueva línea n y pestaña t y no agrega automáticamente un carácter de nueva línea a su salida.
Creemos una cadena de formato y pasámosla a stat. Las secuencias de formato que se iban a usar son %n para el nombre del archivo, %s para el tamaño del archivo y %F para el tipo de archivo. Vamos a agregar el n secuencia de escape al final de la cadena para asegurarse de que cada archivo se maneja en una nueva línea. Nuestra cadena de formato se ve así:
"File %n is %s bytes, and is a %Fn"
Vamos a pasar esto a stat usando el --printf opción. Vamos a preguntar stat para informar sobre un archivo llamado code.c y un conjunto de archivos que coinciden ana.?. Este es el comando completo. Tenga en cuenta el signo igual «=» Entre --printf y la cadena de formato:
stat --printf="File %n is %s bytes, and is a %Fn" code.c ana/ana.?
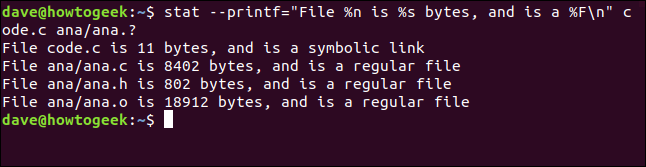
El reporte de cada archivo aparece en una nueva línea, que es lo que solicitamos. El nombre del archivo, el tamaño del archivo y el tipo de archivo se nos proporcionan.
Los formatos personalizados le brindan acceso a inclusive más ítems de datos de los que se incluyen en el estándar stat producción.
Control de grano fino
Como puede ver, existe un gran alcance para extraer los ítems de datos particulares que son de su interés. Probablemente además pueda ver por qué sugerimos utilizar alias para los encantamientos más largos y complejos.





