
La programación de subprocesos múltiples siempre ha sido de interés para los desarrolladores para incrementar el rendimiento de las aplicaciones y aprovechar al máximo el uso de recursos. Esta guía le presentará los conceptos básicos de codificación multiproceso de Bash.
Que es programación multiproceso?
Una imagen vale más que mil palabras, y esto es válido cuando se trata de mostrar la diferencia entre la programación de un solo (1) hilo y la programación de varios hilos (> 1) en Bash:
sleep 1 sleep 1 & sleep 1
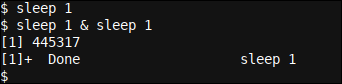
Nuestra primera configuración de programación de subprocesos múltiples o mini script de una sola línea no podría haber sido más simple; en la primera línea, dormimos un segundo usando el sleep 1 mando. En lo que respecta al usuario, un solo hilo estaba ejecutando un solo sueño de un segundo.
En la segunda línea, tenemos dos comandos de suspensión de un segundo. Nos unimos a ellos usando un & separador, que no solo actúa como un separador entre los dos sleep comandos, sino además como un indicador de Bash para iniciar el primer comando en un hilo de fondo.
Regularmente, uno terminaría un comando usando un punto y coma (;). Al hacerlo, se ejecutaría el comando y solo entonces se pasaría al siguiente comando que aparece detrás del punto y coma. A modo de ejemplo, ejecutando sleep 1; sleep 1 tomaría poco más de dos segundos: exactamente un segundo para el primer comando, un segundo para el segundo y una pequeña cantidad de sobrecarga del sistema para cada uno de los dos comandos.
A pesar de esto, en lugar de terminar un comando con un punto y coma, se pueden utilizar otros terminadores de comando que Bash reconoce como &, && y ||. los && la sintaxis no tiene nada que ver con la programación multiproceso, simplemente hace esto; proceda con la ejecución del segundo comando solo si el primer comando fue exitoso. los || es lo contrario de && y ejecutará el segundo comando solo si el primer comando falló.
Volviendo a la programación multiproceso, usando & dado que nuestro terminador de comandos iniciará un procedimiento en segundo plano ejecutando el comando que lo precede. Después procede inmediatamente a ejecutar el siguiente comando en el shell actual mientras deja que el procedimiento en segundo plano (hilo) se ejecute por sí mismo.
En la salida del comando podemos ver que se está iniciando un procedimiento en segundo plano (como lo indica [1] 445317 dónde 445317 es el ID de procedimiento o PID del procedimiento en segundo plano recién iniciado y [1] se indica que este es nuestro primer procedimiento de antecedentes) y posteriormente se dará por terminado (como lo indica [1]+ Done sleep 1).
Si desea ver un ejemplo adicional de manejo de procesos en segundo plano, consulte nuestro post Bash Automation and Scripting Basics (Part 3). Al mismo tiempo, los trucos de terminación del procedimiento de Bash pueden ser de interés.
Ahora demostremos que efectivamente estamos ejecutando dos sleep procesos al mismo tiempo:
time sleep 1; echo 'done' time $(sleep 1 & sleep 1); echo 'done'
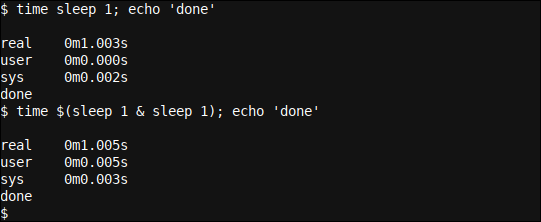
Aquí empezamos nuestro sleep procedimiento bajo time y podemos ver cómo nuestro comando de un solo subproceso se ejecutó durante exactamente 1.003 segundos antes de que se devolviera el indicador de la línea de comandos.
A pesar de esto, en el segundo ejemplo, tomó aproximadamente el mismo tiempo (1,005 segundos) pese a que estábamos ejecutando dos períodos (y procesos) de suspensión, aún cuando no de forma consecutiva. Nuevamente usamos un procedimiento en segundo plano para el primer comando de suspensión, lo que lleva a una ejecución (semi) paralela, dicho de otra forma, multiproceso.
Además usamos un contenedor de subcapa ($(...)) alrededor de nuestros dos comandos de sueño para combinarlos bajo time. Como podemos ver nuestro done la salida se muestra en 1.005 segundos y, por eso, los dos sleep 1 los comandos deben haberse ejecutado simultáneamente. Es interesante el aumento muy pequeño en el tiempo de procesamiento total (0,002 segundos) que puede explicarse fácilmente por el tiempo necesario para iniciar una subcapa y el tiempo necesario para iniciar un procedimiento en segundo plano.
Administración de procesos de subprocesos múltiples (y en segundo plano)
En Bash, la codificación de subprocesos múltiples regularmente implicará subprocesos en segundo plano desde un script principal de una línea o un script Bash completo. En esencia, uno puede pensar en la codificación de subprocesos múltiples en Bash como el inicio de varios subprocesos en segundo plano. Cuando uno comienza a codificar usando múltiples subprocesos, rápidamente queda claro que tales subprocesos de forma general requerirán algún manejo. A modo de ejemplo, tome el ejemplo ficticio donde empezamos cinco períodos concurrentes (y procesos) de sueño en un script Bash;
#!/bin/bash sleep 10 & sleep 600 & sleep 1200 & sleep 1800 & sleep 3600 &
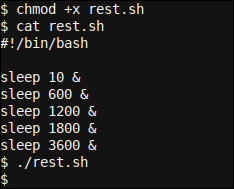
Cuando iniciamos el script (después de hacerlo ejecutable usando chmod +x rest.sh), ¡no vemos ninguna salida! Inclusive si ejecutamos jobs (el comando que muestra los trabajos en segundo plano en curso), no hay salida. ¿Por qué?
El motivo es que el shell que se utilizó para iniciar este script (dicho de otra forma, el shell actual) no es el mismo shell (ni el mismo hilo; para comenzar a pensar en términos de subcapas como hilos en y por sí mismos) que ejecutó el sueño real. comandos o los colocó en segundo plano. Fue más bien el (sub) shell que se inició cuando ./rest.sh Fue ejecutado.
Cambiemos nuestro script agregando jobs dentro del guión. Esto asegurará que jobs se ejecuta desde dentro del (sub) shell donde es relevante, el mismo en el que se iniciaron los períodos (y procesos) de sueño.
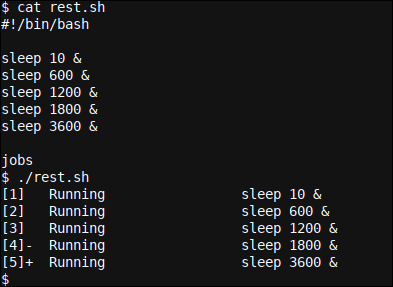
Esta vez podemos ver la lista de procesos en segundo plano que se están iniciando gracias al jobs comando al final del script. Además podemos ver sus PID (identificadores de procedimiento). Estos PID son muy importantes cuando se trata de manejar y administrar procesos en segundo plano.
Otra manera de obtener el Identificador de procedimiento en segundo plano es consultarlo inmediatamente después de colocar un programa / procedimiento en segundo plano:
#!/bin/bash
sleep 10 &
echo ${!}
sleep 600 &
echo ${!}
sleep 1200 &
echo ${!}
sleep 1800 &
echo ${!}
sleep 3600 &
echo ${!}
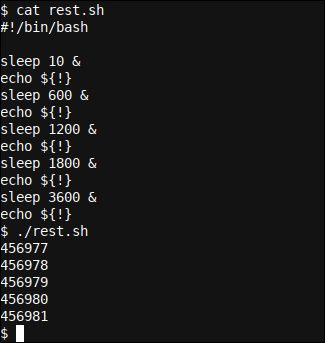
Semejante a nuestro jobs comando (con nuevos PID ahora cuando reiniciamos nuestro rest.sh script), gracias al Bash ${!} Cuando se repite la variable, ahora veremos que los cinco PID se muestran casi inmediatamente después de que se inicia el script: los múltiples procesos de suspensión se colocaron en subprocesos en segundo plano uno tras otro.
The wait Command
Una vez que hemos comenzado nuestros procesos en segundo plano, no tenemos nada más que hacer que esperar a que finalicen. A pesar de esto, cuando cada procedimiento en segundo plano está ejecutando una subtarea compleja, y necesitamos que el script principal (que inició los procesos en segundo plano) reanude la ejecución cuando uno o más de los procesos en segundo plano finalicen, necesitamos código adicional para manejar esto.
Ampliemos nuestro script ahora con el wait comando para manejar nuestros hilos de fondo:
#!/bin/bash
sleep 10 &
T1=${!}
sleep 600 &
T2=${!}
sleep 1200 &
T3=${!}
sleep 1800 &
T4=${!}
sleep 3600 &
T5=${!}
echo "This script started 5 background threads which are currently executing with PID's ${T1}, ${T2}, ${T3}, ${T4}, ${T5}."
wait ${T1}
echo "Thread 1 (sleep 10) with PID ${T1} has finished!"
wait ${T2}
echo "Thread 2 (sleep 600) with PID ${T2} has finished!"
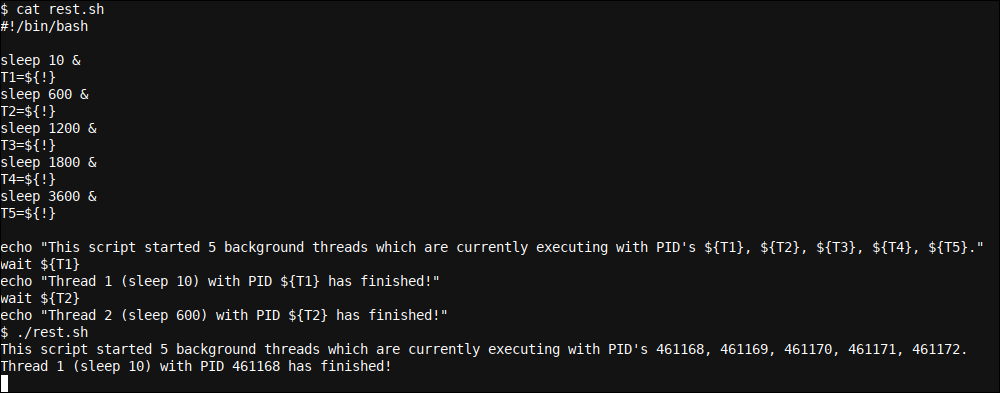
Aquí ampliamos nuestro guión con dos wait comandos que esperan a que termine el PID adjunto al primer y segundo subprocesos. Después de 10 segundos, existe nuestro primer hilo y se nos notifica del mismo. Paso a paso, este script hará lo siguiente: iniciar cinco subprocesos casi al mismo tiempo (aún cuando el inicio de los subprocesos en sí sigue siendo secuencial y no paralelo) donde cada uno de los cinco sleepse ejecutará en paralelo.
Después, el script principal informa (secuencialmente) sobre el subproceso creado y, posteriormente, espera a que termine el ID de procedimiento del primer subproceso. Cuando eso suceda, informará secuencialmente sobre el final del primer hilo y comenzará a esperar a que termine el segundo hilo, etc.
Usando los modismos de Bash &, ${!} y el wait El comando nos brinda una gran flexibilidad cuando se trata de ejecutar múltiples subprocesos en paralelo (como subprocesos en segundo plano) en Bash.
Terminando
En este post, exploramos los conceptos básicos de secuencias de comandos multiproceso de Bash. Introdujimos el operador de procedimiento en segundo plano (&) usando algunos ejemplos fáciles de seguir que muestran tanto de un solo subproceso como de varios subprocesos sleep comandos. A continuación, analizamos cómo manejar los procesos en segundo plano a través de los modismos Bash de uso común. ${!} y wait. Además exploramos el jobs comando para ver la ejecución de subprocesos / procesos en segundo plano.
Si disfrutó leyendo este post, eche un vistazo a nuestro post Hacks de terminación del procedimiento Bash.





