
Este post demostrará cómo se usan y crean las funciones de variables locales en Bash. La creación de funciones Bash le posibilita hacer su código más estructural, y las variables locales ayudan con la seguridad y evitan errores de codificación. ¡Buceo en!
Cuáles son Funciones Bash?
Del mismo modo que otros lenguajes de codificación, Bash le posibilita crear funciones desde su código o script. Una función se puede establecer para realizar una tarea específica, o un conjunto de tareas, y se puede llamar fácil y rápidamente desde su código principal simplemente usando el nombre dado a la función.
Además puede anidar llamadas a funciones (llamar a una función desde dentro de otra función), utilizar variables locales dentro de la función e inclusive pasar variables de un lado a otro con funciones, o a través de el uso de variables globales. Vamos a explorar.
Función de golpe simple
Definimos un test.sh con nuestro editor de texto, de la próxima manera:
#!/bin/bash
welcome(){
echo "welcome"
}
welcome
Posteriormente, hacemos que ese archivo sea ejecutable agregando la ejecución (x) propiedad y ejecute el script:
chmod +x test.sh ./test.sh
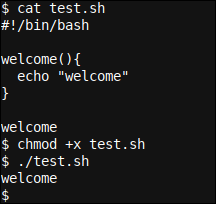
Podemos ver cómo el script establece primero un welcome() función usando los modismos de Bash function_name(), y {…} envoltorios de funciones. En conclusión, llamamos bienvenida a la función simplemente usando su nombre, welcome.
Cuando se ejecuta el script, lo que sucede en segundo plano es que se anota la definición de la función, pero se omite (dicho de otra forma, no se ejecuta), hasta que un poco más baja la llamada a la función. welcome es golpeado, y en qué punto el intérprete de Bash ejecuta el welcome function y regresa a la línea de forma directa después de la llamada a la función, que para este caso es el final de nuestro script.
Pasando variables a funciones Bash
Definimos un test2.sh con nuestro editor de texto favorito (vi;), de la próxima manera:
#!/bin/bash
if [ -z "${1}" ]; then
echo "One option required!"
exit 1
fi
func1(){
echo "${1}"
}
func2(){
echo "${2} ${1}"
}
func1 "${1}"
func2 "a" "b"
Nuevamente hacemos que nuestro script sea ejecutable usando chmod +x test2.sh y ejecutar lo mismo.
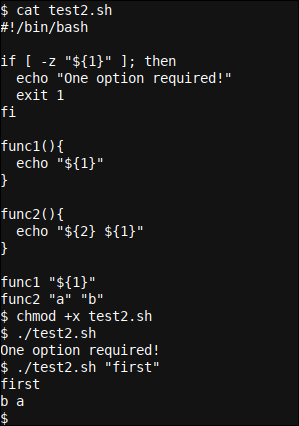
El resultado resultante puede parecer interesante o inclusive confuso al principio. A pesar de esto, es lógico y fácil de seguir. La primera opción pasada al script estará, globalmente, disponible desde el código como ${1}, excepto funciones internas, donde ${1} se convierte en el primer parámetro que se pasa a la función, ${2} el segundo, etc.
Dicho de otra forma, el global ${1} variable (la primera opción pasada al script desde la línea de comando) no está habilitada desde dentro de las funciones, donde el significado de la ${1} La variable cambia a la primera opción pasada a la función. Piense en la jerarquía o piense en cómo una función podría presentar un pequeño script por sí misma y esto pronto tendrá sentido.
Como nota al margen, además se podría usar $1 en lugar de ${1}, pero recomiendo encarecidamente a los aspirantes a programadores de Bash que siempre rodeen los nombres de variables con { y }.
El motivo es que a veces, cuando se usan variables en una cadena, a modo de ejemplo, el intérprete de Bash no puede ver donde una variable termina y parte del texto adjunto puede tomarse como parte del nombre de la variable donde no lo está, lo que genera una salida inesperada. Además es más limpio y claro cuál es la intención, especialmente cuando se trata de matrices y banderas de alternativas especiales.
Por tanto, iniciamos nuestro programa con el ${1} variable establecida en "first". Si observas la vocación de func1, verá que pasamos esa variable a la función, por lo que el ${1} dentro de la función se convierte en lo que estaba en el ${1} del programa, dicho de otra forma "first", y esta es el motivo por la que la primera línea de salida es en realidad first.
Entonces llamamos func2 y pasamos dos hilos "a" y "b" a la función. Estos posteriormente se convierten en los ${1} y ${2} automáticamente dentro del func2 función. Dentro de la función, los imprimimos al revés, y nuestra salida coincide muy bien con b a como la segunda línea de salida.
En conclusión, además hacemos una verificación en la parte de arriba de nuestro script que asegura que una opción se pasa verdaderamente al test2.sh script comprobando si "${1}" está vacío o no utiliza el -z prueba dentro del if mando. Salimos del script con un código de salida distinto de cero (exit 1) para indicar a los programas de llamada que algo salió mal.
Variables locales y valores de retorno
Para nuestro ejemplo final, definimos un script test3.sh de la próxima manera:
#!/bin/bash
func3(){
local REVERSE="$(echo "${1}" | rev)"
echo "${REVERSE}"
}
INPUT="abc"
REVERSE="$(func3 "${INPUT}")"
echo "${REVERSE}"
De nuevo lo hacemos ejecutable y ejecutamos el script. La salida es cba como se puede esperar escaneando el código y anotando los nombres de las variables, etc.

A pesar de esto, el código es complejo y lleva un poco acostumbrarse. Vamos a explorar.
Primero, definimos una función func3 en el que creamos una variable local llamada REVERSE. Le asignamos un valor llamando a una subcapa ($()), y desde dentro de esta subcapa hacemos eco de lo que se pasó a la función (${1}) y canalice esta salida al rev mando.
los rev El comando imprime la entrada recibida de la tubería (o de otro modo) al revés. Además es interesante notar aquí que el ${1} ¡La variable permanece dentro de la subcapa! Es pasado integralmente.
A continuación, aún desde dentro del func3 función, imprimimos la salida. A pesar de esto, esta salida no se enviará a la pantalla, sino que será capturada por nuestra llamada de función y, por eso, almacenada dentro de la ‘global’ REVERSE variable.
Establecemos nuestra entrada en "abc", llama a func3 funcionar de nuevo desde dentro de una subcapa, pasando el INPUT variable, y asigne la salida a la REVERSE variable. Tenga en cuenta que no hay absolutamente ninguna conexión entre el ‘global’ REVERSE variable y la local REVERSE variable dentro del script.
Mientras que cualquier variable global, incluida cualquier MARCHA ATRÁS se pasará a la función, tan pronto como se defina una variable local con el mismo nombre, se utilizará la variable local. Además podemos probar y ver este otro pequeño script test4.sh:
#!/bin/bash
func3(){
local REVERSE="$(echo "${1}" | rev)"
echo "${REVERSE}"
}
INPUT="abc"
REVERSE="test"
func3 "${INPUT}"
echo "${REVERSE}"
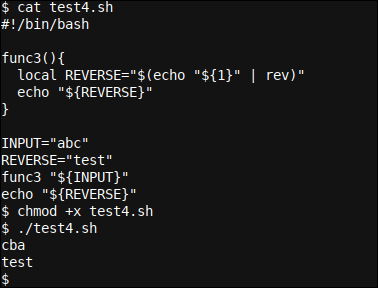
Cuando se ejecuta, la salida es cba y test. los cba es este tiempo generado por el mismo echo "${REVERSE}" dentro de func3 función, pero esta vez se emite de forma directa en lugar de capturarse en el código siguiente como el func3 "${INPUT}" La función no se llama desde dentro de una subcapa.
Este script destaca dos puntos de aprendizaje que cubrimos previamente: en primer lugar, que, aún cuando establecimos el REVERSE variable a "test" dentro del script antes de llamar al func3 función – que el local variable REVERSE toma el control y se utiliza en lugar de ‘global’ uno.
En segundo lugar, que nuestro ‘global’ REVERSE la variable retiene su valor pese a que hubo un local variable con el mismo nombre usado desde dentro de la función llamada func3.
Terminando
Como puede ver, las funciones Bash, el paso de variables, así como el uso de variables locales y semi-globales hacen que el lenguaje de scripting Bash sea versátil, fácil de codificar y le brinda la oportunidad de establecer código bien estructurado.
Además es digno de mención aquí que, al mismo tiempo de mejorar la legibilidad del código y la facilidad de uso, el uso de variables locales proporciona seguridad adicional, puesto que las variables no serán accesibles fuera del contexto de una función, etc. ¡Disfrute de funciones y variables locales mientras codifica en Bash!
Si está interesado en obtener más información sobre Bash, consulte Cómo analizar correctamente los nombres de archivo en Bash y Uso de xargs en combinación con bash -c para crear comandos complejos.





