
Tenho um procedimento em que preciso copiar todas as imagens de uma página da web. Eu costumava executar este procedimento com xmllint, que irá processar um arquivo XML ou HTML e imprimir as entradas que você especificar. Mas quando meu provedor de host de servidor atualizou seus sistemas, eles não incluíram xmllint. Então, eu tive que encontrar outra maneira de extrair uma lista de imagens de uma página HTML. Acontece que você pode fazer isso no bash.
Você pode não pensar que o Bash pode analisar arquivos de dados, mas você pode fazer isso com pensamento inteligente. Bash, da mesma forma que outros shells UNIX anteriores, você pode analisar as linhas uma a uma de um arquivo através da função embutida read demonstração.
Por padrão, a read declaração varre uma linha de dados e os divide em campos. Geralmente, read dividir os campos usando espaços e tabulações, com novas linhas no final de cada linha, mas você pode mudar este comportamento configurando o Separador de Campo Interno (IFS) valor e o delimitador de fim de linha (-d).
Para analisar um arquivo HTML usando read , selecione os IFS a un símbolo mayor que (>) y el delimitador a un símbolo menor que (<). Cada vez que Bash escanea una línea, analiza hasta la próxima < (el comienzo de una etiqueta HTML) después divide esos datos en cada > (el final de una etiqueta HTML). Este código de muestra toma una línea de entrada y divide los datos en TAG e VALUE variáveis:
local IFS='>' read -d '<' TAG VALUE
Exploremos cómo funciona esto. Considere este simple archivo HTML:
<img src="https://www.systempeaker.com/8315/parsing-html-in-bash/logo.png" alt="My logo" /> <p>some text</p>
La primera vez read analiza este archivo, pára no primeiro < símbolo. Sendo que < é o primeiro caractere deste exemplo de entrada, o que significa que o Bash encontra uma string vazia. O resultado TAG e VALUE as correntes também estão vazias. Mas isso é bom para o meu caso de uso.
Da próxima vez que o Bash ler a entrada, pegue img src="https://www.systempeaker.com/8315/parsing-html-in-bash/logo.png"↲alt="My logo" />↲ com uma nova linha antes do alt, e para antes < símbolo na próxima linha. Depois de read divide a linha no > símbolo, o que sai TAG com img src="https://www.systempeaker.com/8315/parsing-html-in-bash/logo.png"↲alt="My logo" / e VALUE com uma nova linha vazia.
O terceiro tempo read analise o arquivo HTML, pegue p>some text. Bash divide a corda no > Resultando em TAG contendo p e VALUE com some text .
Ahora que comprendes cómo utilizar read, es fácil analizar un archivo HTML más largo con Bash. Comience con una función Bash llamada xmlgetnext para analizar los datos usando read , dado que lo hará una y otra vez en el guión. Nombré mi función xmlgetnext para recordarme que este es un reemplazo para Linux xmllint Programa, pero podría haberlo llamado con la misma facilidad htmlgetnext .
xmlgetnext () { local IFS='>' read -d '<' TAG VALUE }
Ahora llama a eso xmlgetnext función para analizar el archivo HTML. Esta es mi completa htmltags texto:
#!/bin / sh # print a list of all html tags xmlgetnext () { local IFS='>' read -d '<' TAG VALUE } gato $1 | while xmlgetnext ; do echo $TAG ; feito
La última línea es la clave. Percorra o arquivo usando xmlgetnext para analisar o HTML e imprimir apenas o TAG ingressos. E para como echo opera com separadores de campo padrão, qualquer linha como img src="https://www.systempeaker.com/8315/parsing-html-in-bash/logo.png"↲alt="My logo" / contendo uma nova linha são impressos em uma única linha, O que img src="https://www.systempeaker.com/8315/parsing-html-in-bash/logo.png" alt="My logo" /.
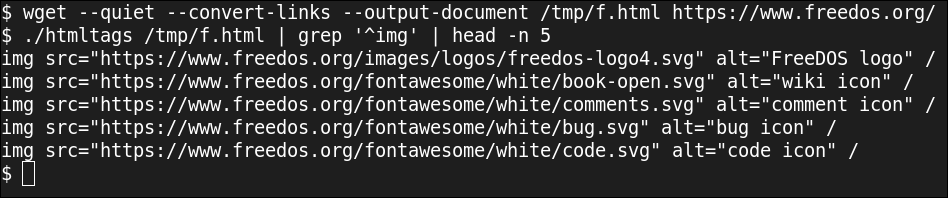
Para obter apenas a lista de imagens, Eu executo a saída deste script por meio de grep para imprimir apenas linhas que tenham um img etiqueta no início da linha.





