
Formatos de coluna, como Apache Parquet, oferecem grande economia de compressão e são muito mais fáceis de escanear, processar e analisar outros formatos como CSV. Neste post, Mostramos como converter seus dados CSV em Parquet usando AWS Glue.
O que é um formato colunar?
Arquivos CSV, arquivos de log e quaisquer outros arquivos delimitados por caracteres armazenam dados em colunas de forma eficiente. Cada linha de dados tem um certo número de colunas, todos separados pelo delimitador, como vírgulas ou espaços. Mas sob o capô, esses formatos ainda são apenas linhas de string. Não há uma maneira simples de verificar uma única coluna de um arquivo CSV.
Isso pode ser um obstáculo com serviços como AWS Athena, que pode executar consultas SQL em dados armazenados em CSV e outros arquivos delimitados. Mesmo se você estiver consultando apenas uma única coluna, Atena tem que escanear o cheio conteúdo do arquivo. A única cobrança do Athena é o GB de dados processados, portanto, aumentar a conta processando dados desnecessários não é a melhor ideia.
A resposta é um verdadeiro formato colunar. Os formatos de coluna armazenam dados em colunas, da mesma forma que um banco de dados relacional tradicional. As colunas são armazenadas juntas e os dados são muito mais homogêneos, o que os torna mais fáceis de compactar. Filho não exatamente legível por humanos, mas são compreendidos pela aplicação que os processa sem problemas. Na realidade, porque há menos dados para escanear, eles são muito mais fáceis de processar.
Porque Atena só precisa escanear uma coluna para fazer uma seleção por coluna, reduz drasticamente os custos, especialmente para conjuntos de dados maiores. Se tem 10 colunas em cada arquivo e verificar apenas uma, isso significa economia de custos de 90% apenas mudando para Parquet.
Converta automaticamente com AWS Glue
AWS Glue é uma ferramenta da Amazon que converte conjuntos de dados entre formatos. Usado principalmente como parte de um pipeline para processar dados armazenados em formatos delimitados e outros, e os injeta em bancos de dados para uso no Athena. Embora possa ser configurado para ser automático, você também pode executá-lo manualmente e, com alguns ajustes, pode ser usado para converter arquivos CSV para o formato Parquet.
Vá para o console do AWS Glue e selecione “Começar”. Na barra lateral, Clique em “adicionar rastreador” e crie um novo rastreador. O rastreador está configurado para pesquisar dados de Baldes S3e importar os dados para um banco de dados para usar na conversão.
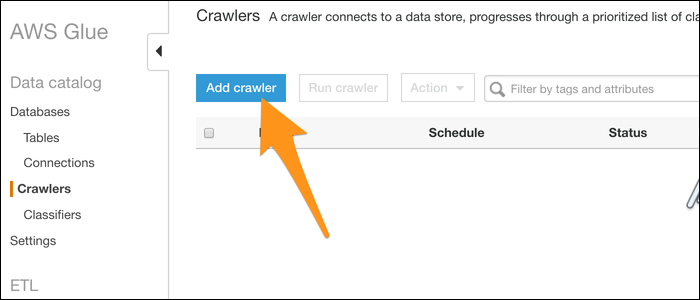
Nomeie seu rastreador e escolha importar dados de um data warehouse. Selecione S3 (embora o DynamoDB seja outra alternativa) e digite o caminho para uma pasta que contém seus arquivos. Se você tiver apenas um arquivo que deseja converter, coloque em sua própria pasta.
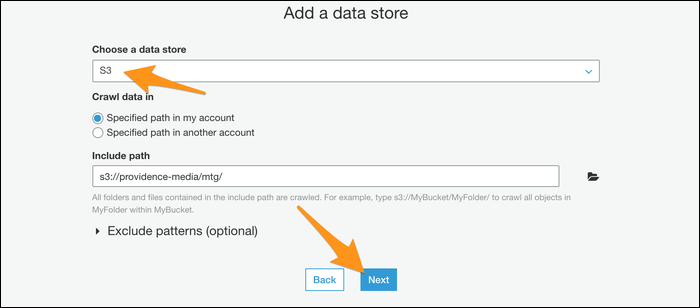
A seguir, você será solicitado a criar uma função IAM para o seu rastreador operar. Crie a função e escolha-a na lista. Pode ser necessário pressionar o botão de atualização próximo a ele para que apareça.
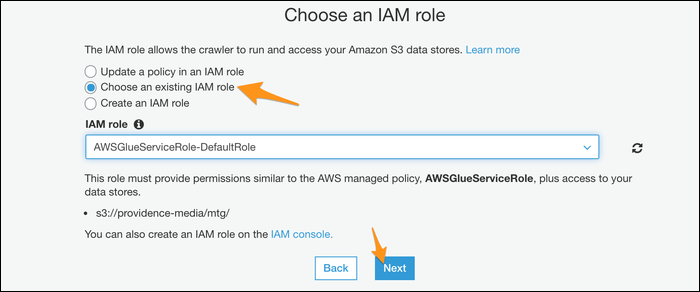
Escolha um banco de dados para a saída do rastreador; Se você já usou Atenas antes, você pode usar seu banco de dados personalizado, mas se não, o padrão deve funcionar bem.
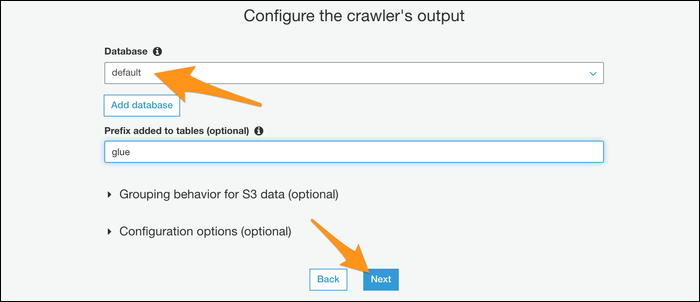
Se você deseja automatizar o procedimento, você pode dar ao seu rastreador uma programação para ser executado regularmente. Sim, não é assim, escolha o modo manual e execute-o você mesmo no console.
Uma vez criado, vá em frente e execute o rastreador para importar os dados para o banco de dados que você escolheu. Se tudo funcionasse, você deve ver o seu arquivo importado com o esquema adequado. Os tipos de dados para cada coluna são atribuídos automaticamente com base na entrada de origem.
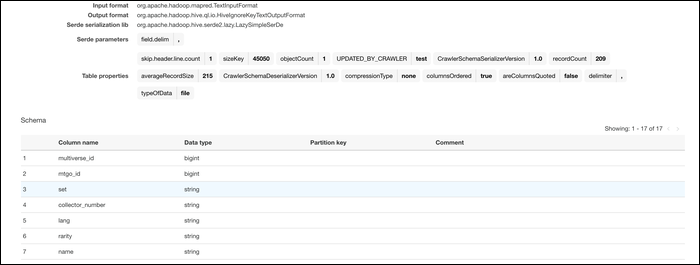
Assim que seus dados estiverem no sistema AWS, pode convertê-los. Do Glue Console, mudar para guia “Funciona” e criar um novo emprego. Dê um nome a ele, adicione sua função do IAM e selecione “Um script de iniciativa gerado pelo AWS Glue” como o que é trabalho executado.
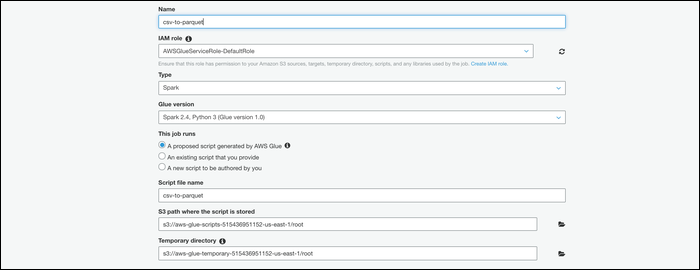
Selecione sua mesa na próxima tela, depois escolha “Esquema de mudança” para especificar que este trabalho realiza uma conversão.

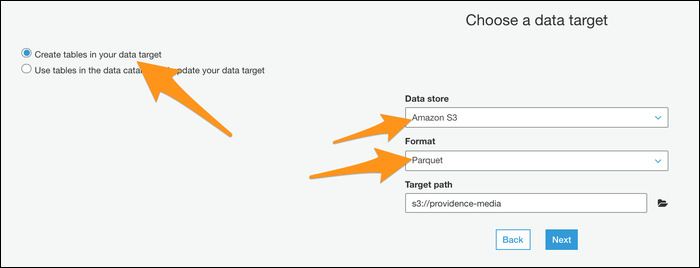
A seguir, deve escolher “Crie tabelas no seu destino de dados”, especifique Parquet como o formato e insira um novo caminho de destino. Certifique-se de que este seja um local vazio, sem quaisquer outros arquivos.
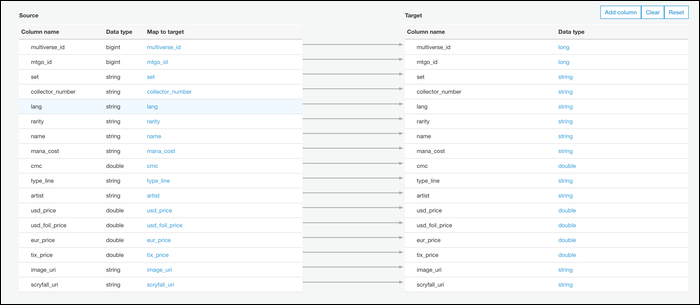
A seguir, você pode editar seu esquema de arquivo. O padrão é um mapeamento um para um de colunas CSV para colunas Parquet, que é provavelmente o que você quer, mas você pode modificá-lo se precisar.
Crie o trabalho e você será levado a uma página que permite editar o script Python que você executar. O script padrão deve funcionar bem, então pressione “Guarda” e volte para a aba de trabalhos.
Em nossos testes, o script sempre falhava, a menos que a função IAM tivesse permissão específica para gravar no local para o qual especificamos a saída. Você pode ter que editar manualmente as permissões do Console de gerenciamento IAM se você encontrar o mesmo problema.
Caso contrário, Clique em “Corre” e seu script deve começar. O procedimento pode levar um ou dois minutos, mas você deve ver o status no painel de informações. Quando acabar, você verá um novo arquivo criado no S3.
Este trabalho pode ser configurado para ser executado fora dos gatilhos definidos pelo rastreador que importa os dados, então todo o procedimento pode ser automatizado do início ao fim. Se você estiver importando logs do servidor para S3 desta forma, este pode ser um método simples para convertê-los em um formato mais utilizável.





