
Software de credenciamento óptico de caracteres (OCR) alta qualidade pode ter sido cara no passado, mas agora está habilitado, sem cargo, diretamente da linha de comando do seu terminal Linux. Esta postagem o ajudará a configurar e começar a usar OCR.
O que é OCR?
A sigla OCR significa Acreditação de caráter óptico: um programa de software e um sistema através do qual um computador pode ler o texto dentro das imagens. Imagine tirar uma foto de sua passagem favorita de um dos livros do Senhor dos Anéis.
Você gostaria de citar em outro lugar, mas tudo que ele tem é uma foto. O software OCR pode ajudá-lo a analisar essa foto / imagem e encontrando todo o texto dentro dela.
Depois de, o software OCR irá analisar, para cada carta descoberta, os pontos gráficos vistos na imagem e traduzi-los / vai se transformar em texto real que um computador pode usar, como um exemplo, em um processador de texto.
Embora existam muitos programas de OCR disponíveis, alguns pagos e alguns gratuitos, nem todos são da mesma qualidade. Alguns pacotes fornecerão resultados de qualidade inferior, outros irão se alinhar de perto com o texto visto na foto ou imagem.
Em termos gerais, livros padrão (ou impressões de páginas da web da Internet) funcionará muito bem e deve produzir resultados de qualidade razoável em todos os casos, uma vez que as fontes são retas e uniformes e estão em apenas um ângulo, contanto que a foto ou digitalização original seja de um tamanho razoável. qualidade.
Também é bom observar que mesmo pacotes de software avançados podem ter problemas com imagens de baixa qualidade ou borradas., e a maioria dos pacotes pode ter problemas com diferentes estilos de escrita, etc. Outros desafios podem incluir texto misturado com imagens ou fotos, ou direções diferentes (como um exemplo, deixou (texto à direita, de cima para baixo ou em ângulo) dentro da mesma página.
Isso torna a seleção, e potencialmente pagar, um pacote de OCR pode ser um procedimento longo, especialmente se você quiser testar e examinar cada pacote.
Para quem usa Linux, existe uma ótima rota alternativa. Um software de OCR gratuito de alta qualidade baseado em LSTM Neural Net com suporte Unicode (UTF-8) e que pode reconhecer mais do que 100 idiomas por padrão. Ele também suporta muitos formatos de saída, como HTML, PDF e texto simples.
Sem mais preâmbulos; Bem-vindo ao Tesseract OCR!
Instalando Tesseract OCR
Instalar Tesseract OCR em sua distribuição Linux baseada em Debian / Apt (como Ubuntu e Mint), faço:
sudo apt install tesseract-ocr libtesseract-dev tesseract-ocr-eng
Instalar Tesseract OCR no RHEL e Centos, faça o seguinte:
sudo yum install epel-releasesudo yum install tesseract-devel leptonica-devel
Instalar Tesseract OCR no Fedora, faço:
sudo yum install tesseract-devel leptonica-devel
Instalar Tesseract OCR no OSX, Faça o seguinte:
brew install tesseract
Vamos para o OCR!
Usaremos uma imagem simples que contém o seguinte texto:

Para converter esta imagem, tudo o que você precisa fazer é abrir o terminal prompt, mudar o diretório (usando o cd your_directory_with_images comando) para o diretório que contém suas imagens (como um exemplo, se você criou um diretório de imagens em seu diretório doméstico (~/images) você pode simplesmente usar cd ~/images) e OCR dos arquivos:
tesseract -l eng input_for_ocr.png output_from_ocr
cat output_from_ocr.txt
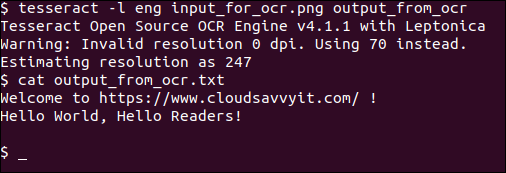
Muito simples e simples. E como podemos ver, a saída é perfeita.
Nós especificamos o idioma inglês usando o -l eng opção. Você pode consultar o manual do tesseract (man tesseract) para qualquer outro código de idioma disponível.
Também especificamos a imagem de entrada (input_for_ocr.png) bem como o arquivo de saída output_from_ocr sem qualquer extensão de arquivo, que usará o texto simples padrão .txt formato.
Também podemos alterar o formato de saída para PDF usando um comando um pouco mais longo que simplesmente especifica o formato de saída no final:
tesseract -l eng input_for_ocr.png output_from_ocr pdf

Adicionando o pdf sufixo, o formato de saída usado foi PDF. Quando abrimos o arquivo PDF (output_from_ocr.pdf), podemos ver que o texto pode ser escolhido e copiado / colar como foi feito com a palavra Leitores! aqui:
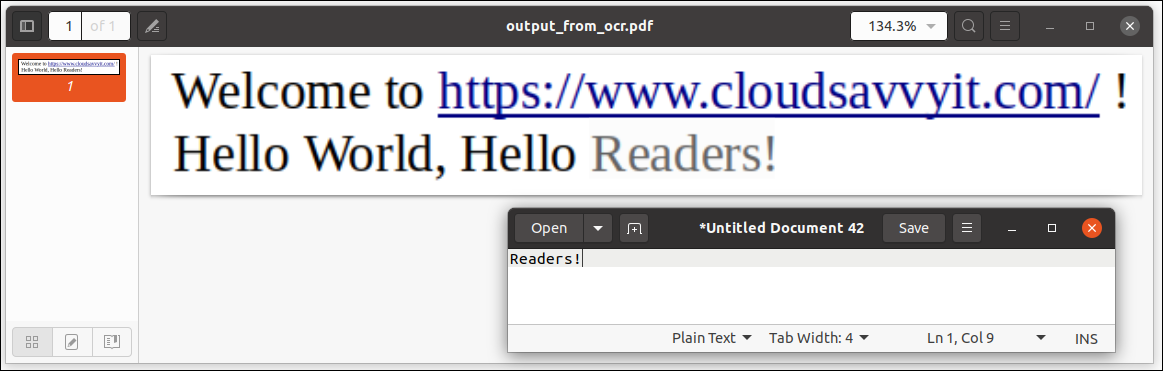
Em outras palavras, O arquivo PDF contém dados selecionáveis e baseados em texto, nenhuma informação gráfica (e, portanto, não selecionável). Excelente!
E se eu quiser fazer o OCR de um arquivo PDF?
As vezes, você pode receber um arquivo PDF que, embora o formato PDF suporte texto real dentro das páginas, contém apenas imagens com texto. Isso pode ser frustrante, já que copiar e colar não estará disponível. Você também pode fazer o OCR dessas páginas, com um pouco de solução.
Você deve primeiro converter seu arquivo PDF em imagens, uma imagem por página, e, posteriormente, OCR das páginas individuais em texto. Um pouco mais de trabalho, mas ainda economiza muito tempo em vez de redigitar o texto manualmente.
Para saber os passos simples para converter um arquivo PDF em imagens, ou até mesmo para criar um script e automatizar a conversão de vários arquivos PDF, você pode ler nossa postagem Converter PDF em imagens da linha de comando do Linux.
Final
Neste post, nós exploramos Tesseract, o mecanismo de OCR de linha de comando de alta qualidade para Linux. Vimos como poderíamos facilmente converter imagens em texto usando um comando simples.
Também analisamos a conversão de imagens em arquivos PDF baseados em texto, e mencionamos uma postagem em que você pode encontrar informações sobre como pré-converter arquivos PDF baseados em imagens em imagens para que possam ser posteriormente convertidos em texto usando o método OCR mostrado aqui.
Desfrutar!





