Classificar um arquivo de registro por uma coluna específica é útil para encontrar informações rapidamente. Os registros são geralmente armazenados como texto simples, para que você possa usar ferramentas de manipulação de texto de linha de comando para processá-los e visualizá-los de uma forma mais legível.
Extraia colunas com corte e awk
a cut e awk Os utilitários são duas maneiras diferentes de extrair uma coluna de informações de arquivos de texto. Ambos assumem que seus arquivos de log são delimitados por espaços em branco, como um exemplo:
coluna coluna coluna
Isso representa um obstáculo se os dados nas colunas contiverem espaços em branco, como datas (“quarta-feira 12 de junho”). Clima cut você pode ver isso como três colunas separadas, você ainda pode extrair todos os três ao mesmo tempo, assumindo que sua estrutura de arquivo de log é consistente.
cut é muito simples de usar:
cat system.log | cut -d '' -f 1-6
a cat comando lê o conteúdo de system.log e canaliza para cut. a -d flag especifica o delimitador, para este caso, um espaço em branco. (O padrão é a guia, t.) o -f flag especifica quais campos gerar. Este comando imprimirá especificamente as primeiras seis colunas de system.log. Se eu só quisesse imprimir a terceira coluna, Eu usaria o -f 3 bandeira.
awk é mais poderoso, mas não tão conciso. cut é útil para extrair colunas, como se você quisesse obter uma lista de endereços IP de seus registros do Apache. awk pode reorganizar linhas inteiras, que pode ser útil para classificar um documento inteiro por uma coluna específica. awk é uma linguagem de programação completa, mas você pode usar um comando simples para imprimir colunas:
cat system.log | awk '{imprimir $1, $2}'awk execute seu comando para cada linha do arquivo. Por padrão, divida o arquivo por espaços em branco e armazene cada coluna em variáveis $1, $2, $3, e assim por diante. Usando o print $1 comando, pode imprimir a primeira coluna, mas não há uma maneira fácil de imprimir um intervalo de colunas sem usar loops.
Um benefício de awk é que o comando pode referir-se a toda a linha ao mesmo tempo. O conteúdo da linha é armazenado em variável $0, que você pode usar para imprimir a linha inteira. Então, poderia, como um exemplo, imprima a terceira coluna antes de imprimir o resto da linha:
awk '{imprimir $3 " " $0}'a " " imprime um espaço entre $3 e $0. Este comando repete a coluna três duas vezes, mas você pode consertá-lo definindo o $3 variável para nula:
awk '{printf $3; $3=""; imprimir " " $0}'a printf O comando não imprime uma nova linha. Da mesma forma, você pode excluir colunas específicas da saída definindo-as todas como strings vazias antes de imprimir $0:
awk '{$1= $ 2 = $ 3 =""; imprimir $0}'Você pode fazer muito mais com awk, Incluindo correspondência de expressão regular, mas a extração de coluna pronta para uso funciona bem para este caso de uso.
Classifique as colunas com classificar e uniq
a sort O comando pode ser usado para classificar uma lista de dados com base em uma coluna específica. A sintaxe é:
sort -k 1
onde ele -k bandeira denota o número da coluna. Você canaliza a entrada para este comando e expõe uma lista ordenada. Por padrão, sort usa ordem alfabética, mas suporta mais opções por meio de sinalizadores, O que -n para classificação numérica, -h para sufixos de classificação (1M> 1K), -M categorizar abreviações por meses, e -V para classificar os números da versão do arquivo (arquivo-1.2.3> arquivo-1.2.1).
a uniq O comando filtra as linhas duplicadas, deixando apenas os únicos. Só funciona para linhas adjacentes (por motivos de desempenho), então você deve sempre usá-lo depois sort para remover duplicatas em todo o arquivo. A sintaxe é simplesmente:
sort -k 1 | uniq
Se você quiser apenas listar as duplicatas, usar el -d bandeira.
uniq você também pode contar o número de duplicatas com o -c bandeira, o que o torna muito bom para rastreamento de frequência. Como um exemplo, se você deseja obter uma lista dos principais endereços IP que alcançam o seu servidor Apache, você pode executar o seguinte comando em seu access.log:
cut -d '' -f 1 | ordenar | uniq -c | tipo não | cabeça
Esta string de comando irá cortar a coluna de endereço IP, irá agrupar as duplicatas, irá remover duplicados enquanto conta cada ocorrência, então ele irá classificar de acordo com a coluna de contagem em ordem numérica decrescente, deixando você com uma lista parecida com esta:
21 192.168.1.1 12 10.0.0.1 5 1.1.1.1 2 8.0.0.8
Você pode aplicar essas mesmas técnicas aos seus arquivos de log, ao mesmo tempo, de outros utilitários, como awk e sed, para extrair informações úteis. Esses comandos encadeados são longos, mas você não precisa escrevê-los o tempo todo, uma vez que você sempre pode armazená-los em um script bash ou aliases por meio de seu ~/.bashrc.
Filtrando dados com grep e awk
grep é um comando muito simples; fornece uma definição de pesquisa e passa a entrada para você, e cuspir todas as linhas que contenham esse termo de pesquisa. Como um exemplo, se você quiser procurar por erros 404 no registro de acesso do Apache, você pode fazer o seguinte:
cat access.log | grep "404"
que cuspiria uma lista de entradas de registro que correspondem ao texto fornecido.
Apesar disto, grep você não pode limitar sua pesquisa a uma coluna específica, então este comando irá falhar se tiver o texto “404” em qualquer outro lugar do arquivo. Se você quiser apenas olhar a coluna do código de status HTTP, deve usar awk:
cat access.log | awk '{E se ($9 == "404") imprimir $0;}'Com awk, também tem a vantagem de poder realizar pesquisas negativas. Como um exemplo, você pode pesquisar todas as entradas de registro que não o fiz retornar com código de status 200 (OK):
cat access.log | awk '{E se ($9 != "200") imprimir $0;}'enquanto tem acesso a todas as funções programáticas awk fornece.
Opções de GUI para logs da web
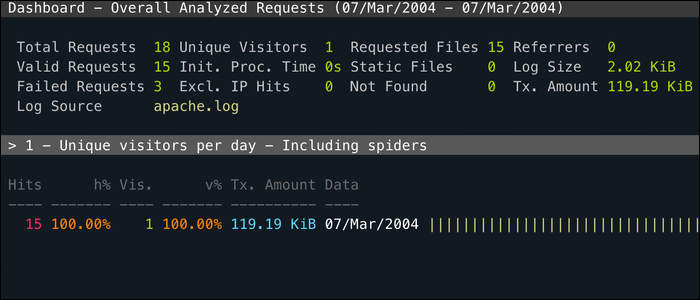
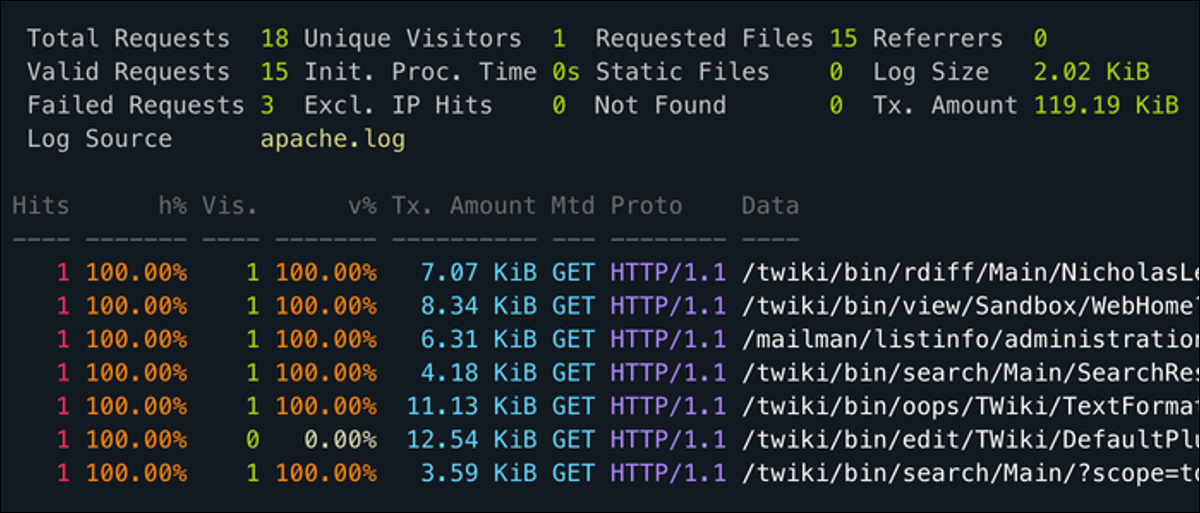
GoAccess é um utilitário CLI para monitorar o log de acesso do seu servidor web em tempo real e classificar por cada campo útil. Funciona inteiramente em seu terminal, então você pode usá-lo via SSH, mas também tem uma interface da web muito mais intuitiva.
apachetop é outro utilitário específico para apache, que pode ser usado para filtrar e classificar por colunas em seu registro de acesso. Ele roda em tempo real diretamente no seu access.log.





