
Você quer renomear todo um conjunto de arquivos para uma sequência numérica (1.pdf, 2.pdf, 3.pdf,…) en Linux? Isso pode ser feito com alguns scripts leves e esta postagem mostrará como fazer exatamente isso.
Nomes de arquivos numéricos
Em geral, quando digitalizamos um arquivo PDF com algum hardware (telefone celular, scanner de PDF dedicado), o nome do arquivo será algo como 2020_11_28_13_43_00.pdf. Muitos outros sistemas semiautomáticos produzem nomes de arquivos semelhantes com base na data e hora.
As vezes, o arquivo também pode conter o nome do aplicativo que está sendo usado, ou alguma outra informação como, como um exemplo, o DPI (pontos por polegada) tamanho de papel aplicável ou digitalizado.
Ao coletar arquivos PDF de diferentes fontes, as convenções de nomenclatura de arquivo podem diferir significativamente e pode ser bom padronizar em um nome de arquivo numérico (ou numérico em parte).
Isso também se aplica a outros domínios e conjuntos de arquivos. Como um exemplo, suas receitas ou coleção de fotos, amostras de dados geradas em sistemas de monitoramento automatizados, arquivos de log prontos para arquivar, um conjunto de arquivos SQL para o engenheiro de banco de dados e, em geral, quaisquer dados coletados de diferentes fontes com diferentes esquemas de nomenclatura.
Renomear arquivos em massa para nomes de arquivo numéricos
En Linux, é fácil renomear rapidamente um conjunto completo de arquivos com nomes totalmente diferentes, para uma sequência numérica. "Fácil" significa "fácil de executar" aqui: o problema de renomear arquivos para números numéricos é complexo para se codificar: o script embutido abaixo tirou de 3 uma 4 horas para investigar, criar e testar. Muitos outros comandos testados, todos eles tinham limitações que eu queria evitar.
Observe que nenhuma garantia é feita ou fornecida, e este código é fornecido “como é”. Faça sua própria pesquisa antes de correr. Tendo dito isto, Eu testei com sucesso em arquivos com alguns caracteres especiais, e também contra mais de 50k arquivos sem perder nenhum arquivo. Eu também verifiquei um arquivo chamado 'a'$'n''a.pdf' contendo uma nova linha.
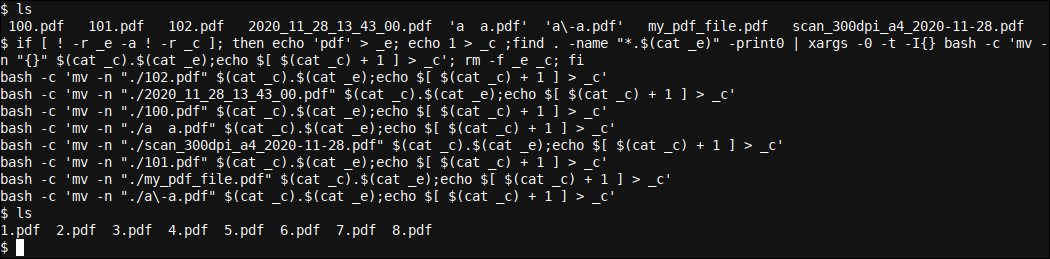
E se [ ! -r _e -a ! -r _c ]; então echo 'pdf' > _e; eco 1 > _c ;achar . -nome "*.$(cat _e)" -print0 | xargs -0 -eu{} bash -c 'mv -n "{}" $(cat _c).$(cat _e);eco $[ $(cat _c) + 1 ] > _c '; rm -f _e _c; ser
Vamos primeiro ver como isso funciona e depois vamos analisar o comando. Criamos um diretório com oito arquivos, todos com nomes muito diferentes, exceto que sua extensão corresponde e é .pdf. A seguir, nós executamos o comando anterior:

O resultado foi que 8 arquivos foram renomeados para 1.pdf, 2.pdf, 3.pdf, etc., mesmo que seus nomes estivessem bastante deslocados antes.
O comando assume que você não tem 1.pdf para x.pdf arquivos nomeados ainda. Se isso acontecer, você pode mover esses arquivos para um diretório separado, colocou o echo 1 para um número maior para começar a renomear os arquivos restantes em um determinado deslocamento, e depois mesclar os dois diretórios novamente.
Sempre tome cuidado para não sobrescrever nenhum arquivo, e é sempre uma boa ideia fazer um backup rápido antes de atualizar qualquer coisa.
Vamos ver o comando em detalhes. Você pode ajudar a ver o que está acontecendo adicionando o -t opção a xargs que nos permite ver o que acontece nos bastidores:
Para iniciar, o comando usa dois pequenos arquivos temporários (chamado _mim e _C) como armazenamento temporário. No início do eyeliner, Faz um verificação de segurança usando um if declaração para garantir que ambos _mim e _C arquivos não estão presentes. Se houver um arquivo com esse nome, o script não vai continuar.
Sobre o uso de pequenos arquivos temporários versus variáveis, eu posso dizer isso, embora o uso de variáveis teria sido ideal (salvar um pouco de E / Disco S), havia dois problemas que eu estava enfrentando.
A primeira é que se você EXPORTAR uma variável no início do liner e posteriormente usar essa mesma variável mais tarde, se outro script usa a mesma variável (incluindo este script que roda mais de uma vez simultaneamente na mesma máquina), então aquele script, Oeste, pode ser afetado. É melhor evitar essa interferência ao tentar renomear muitos arquivos!!
O segundo foi aquele xargs em combinação com bash -c parece ter uma limitação na manipulação de variáveis dentro do bash -c linha de comando. Mesmo uma extensa pesquisa online não forneceu uma solução viável para isso.. Por isso, acabei usando um pequeno arquivo _C que mantém o progresso.
_mim É a extensão que procuraremos e usaremos, e _C é um contador que aumentará automaticamente a cada mudança de nome. a echo $[ $(cat _c) + 1 ] > _c o código cuida disso, mostrando o arquivo com cat, adicionando um número e reescrevendo-o.
O comando também usa o melhor método possível para lidar com caracteres especiais de nome de arquivo usando terminação nula em vez de terminação de nova linha padrão, Em outras palavras, a � personagem. Isso é garantido pelo -print0 opção a find, e para ele -0 opção para xargs.
O comando de pesquisa irá procurar por qualquer arquivo com a extensão especificada no _mim Arquivo (criado por echo 'pdf' > _e comando. Você pode variar esta extensão para qualquer outra extensão que desejar, mas não o prefixe com um ponto. O ponto já está incluído no último *.$(cat _e) -name especificador para find.
Depois de encontrar, localizou todos os arquivos e os enviou: � terminou para xargs, xargs irá renomear os arquivos um por um usando o arquivo contador (_C) e a mesma extensão de arquivo (_mim). Para obter o conteúdo dos dois arquivos, Um simples cat o comando é usado, executando de dentro de uma subcamada.
a mv comando de movimento usa -n para evitar sobrescrever quaisquer arquivos já presentes. Por fim, limpamos os dois arquivos temporários, excluindo-os.
Embora o custo de usar dois arquivos de estado e ramificação de subcamada possa ser limitado, isso adiciona alguma sobrecarga ao script, especialmente ao lidar com um grande número de arquivos.
Existem todos os tipos de outras soluções para este mesmo problema online, e muitos tentaram e não conseguiram criar uma solução totalmente funcional. Muitas soluções esqueceram todos os tipos de casos laterais, Como usar ls indeterminado --color=never, que pode levar à análise de códigos hexadecimais ao usar o código de cores da lista de diretórios.
Apesar disto, outras soluções ignoraram o manuseio de arquivos com espaços, novas linhas e personagens especiais, como ” corretamente. Para isto, A combinação find ... -print0 ... | xargs -0 ... geralmente é indicado e ideal (e ambos os circunstâncias e xargs manuais aludem a este fato fortemente).
Embora eu não considere minha implementação a resposta perfeita ou final, parece ser um avanço significativo para muitas das outras soluções que existem, ao usar find e � correntes acabadas, protegendo nome de arquivo máximo e suporte de análise, enquanto toma algumas outras sutilezas, como especificar um deslocamento iniciale seja totalmente Nativo de Bash.
Desfrutar!





