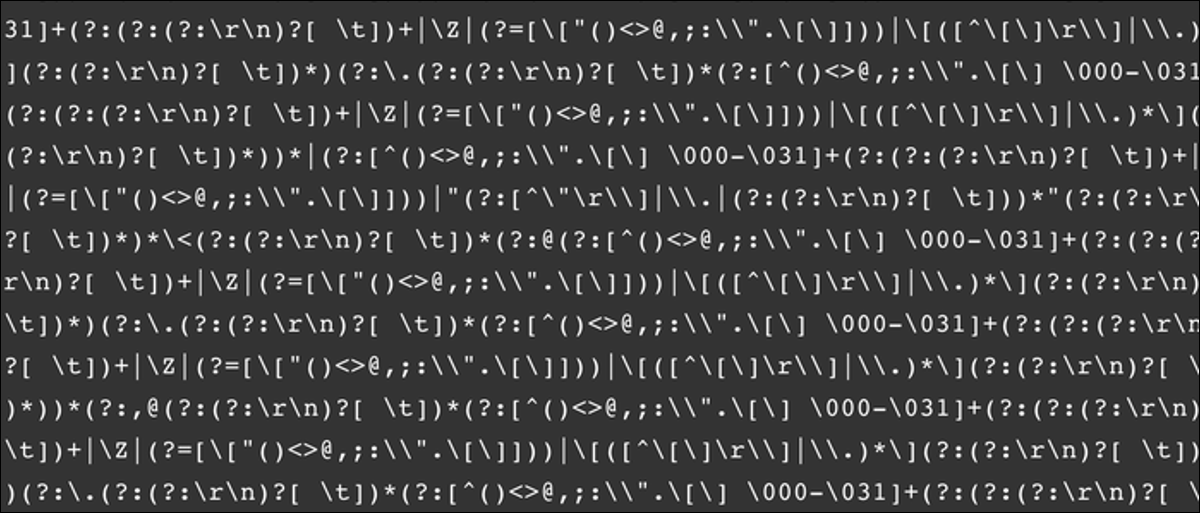
Regex, abreviatura de expressão regular, é frequentemente usado em linguagens de programação para combinar padrões em strings, procure e substitua, validação de entrada e reformatação de texto. Aprender como usar Regex corretamente pode tornar o trabalho com texto muito mais fácil.
Sintaxe de expressão regular, explicada
Regex tem a reputação de ter uma sintaxe horrível, mas é muito mais fácil escrever do que ler. Como um exemplo, aqui está um regex geral para um validador de e-mail compatível com RFC 5322:
(?:[a-z0-9!#$%&'*+/=?^_`~-]+(?:.[a-z0-9!#$%&'*+/=?^_`~-]+)*|"(?:[x01-
x08x0bx0cx0e-x1fx21x23-x5bx5d-x7f]|[x01-x09x0bx0cx0e-x7f])*")
@(?:(?:[a-z0-9](?:[a-z0-9-]*[a-z0-9])?.)+[a-z0-9](?:[a-z0-9-]*[a-z0-9])?|[(?
:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?).){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-
9][0-9]?|[a-z0-9-]*[a-z0-9]:(?:[x01-x08x0bx0cx0e-x1fx21-x5ax53-x7f]|
[x01-x09x0bx0cx0e-x7f])+)])
Se parece que alguém bateu a cara contra o teclado, não está sozinho. Mas sob o capô, toda essa bagunça é, na verdade, agendar um máquina de estados finitos. Esta máquina funciona para cada personagem, avançando e combinando de acordo com as regras que você definiu. Muitas ferramentas online renderizam diagramas ferroviários, mostrando como sua máquina Regex funciona. Aqui está o mesmo regex na forma visual:
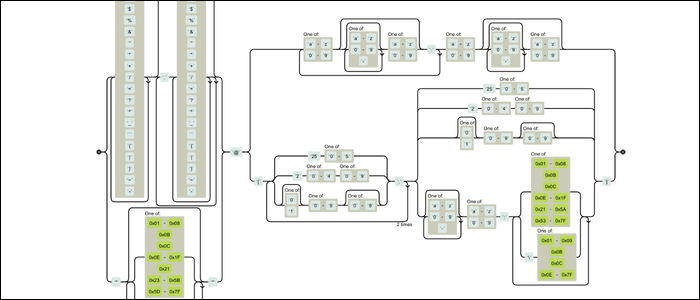
Ainda muito confuso, mas é muito mais compreensível. É uma máquina com peças móveis que possuem regras que definem como tudo se encaixa. Você pode ver como alguém montou isso; não é apenas um monte de texto.
Primeiro: usar um depurador regex
Antes de começar, a menos que seu Regex seja especificamente curto ou você seja especificamente competente, você deve usar um depurador online ao escrevê-lo e testá-lo. Torna muito mais fácil entender a sintaxe. Nós sugerimos Regex101 e RegExr, oferecendo referência de sintaxe integrada e teste.
Como funciona o Regex?
Por agora, vamos nos concentrar em algo muito mais simples. Este é um diagrama de Regulex para uma expressão regular de correspondência de e-mail muito curta (e definitivamente não é compatível com RFC 5322):

O motor Regex começa à esquerda e percorre as linhas, personagens combinando conforme você avança. O grupo # 1 corresponde a qualquer caractere exceto uma quebra de linha, e continuará a combinar caracteres até que o próximo bloco encontre uma correspondência. Para este caso, para quando vira um @ símbolo, o que significa que o Grupo # 1 captura o nome do endereço de e-mail e tudo o que segue corresponde ao domínio.
A expressão regular que define o Grupo # 1 em nosso exemplo de e-mail é:
(.+)
Os parênteses definem um grupo de captura, que diz ao motor Regex para incluir o conteúdo da correspondência deste grupo em uma variável especial. Quando você executa uma expressão regular em uma string, o resultado padrão é a correspondência completa (para este caso, todo e-mail). Mas também retorna cada grupo de captura, o que torna este regex útil para extrair nomes de e-mails.
O ponto é o símbolo de “Qualquer personagem, exceto nova linha”. Isso corresponde a tudo em uma linha, então se você passou este e-mail Regex um endereço como:
%$#^&%*#%$#^@gmail.com
Corresponderia %$#^&%*#%$#^ como o nome, mesmo que isso seja ridículo.
O símbolo de mais (+) é uma estrutura de controle que significa “corresponder ao personagem anterior ou grupo uma ou mais vezes”. Certifique-se de que todos os nomes correspondem, e não apenas o primeiro personagem. Isso é o que cria o loop encontrado no diagrama da ferrovia.
O resto do Regex é muito simples de descobrir:
(.+)@(.+..+)
O primeiro grupo para quando atinge o @ símbolo. Mais tarde, o próximo grupo começa, que novamente corresponde a alguns caracteres até encontrar um caractere de período.
Porque caracteres como pontos, parênteses e barras são usados como parte da sintaxe no Regrex, sempre que você quiser combinar esses personagens, deve escapar corretamente com uma barra invertida. Neste exemplo, para combinar com o período, nós escrevemos . e o analisador trata-o como um símbolo que significa “combinar um ponto”.
Correspondência de caracteres
Se você tiver caracteres não controlados em seu Regex, o mecanismo Regex assumirá que esses caracteres formarão um bloco correspondente. Como um exemplo, Regex:
ele + isso
Vai combinar com a palavra “Olá” com qualquer número e. É necessário escapar de qualquer outro caractere para que funcione corretamente.
Regex também tem classes de personagens, que agem como uma abreviatura para um conjunto de caracteres. Eles podem variar dependendo da implementação do Regex, mas esses poucos são padrão:
.– corresponde a qualquer coisa, exceto nova linha.w– corresponde a qualquer personagem de “palavra”, incluindo dígitos e sublinhados.d– coincidir com os números.b– corresponde a caracteres de espaço em branco (Em outras palavras, espaço, tabulação, nova linha).
Esses três têm contrapartes em maiúsculas que invertem sua função. Como um exemplo, D corresponde a qualquer coisa diferente de um número.
Regex também tem um conjunto de caracteres. Como um exemplo:
[abc]
Vai combinar com qualquer um a, b, o c. Isso funciona como um bloco e os colchetes são apenas estruturas de controle. alternativamente, você pode especificar um intervalo de caracteres:
[a-c]
Ou negar o set, que corresponderá a qualquer caractere que não esteja no conjunto:
[^ a-c]
Quantificadores
Quantificadores são uma parte importante do Regex. Eles permitem que você combine cadeias onde você não conhece o exatamente formato, mas você tem uma boa ideia.
a + O operador no exemplo de e-mail é um quantificador, especificamente o quantificador “um ou mais”. Se não sabemos quanto tempo uma determinada cadeia é, mas sabemos que é feito de caracteres alfanuméricos (e não está vazio), nós podemos escrever:
w +
Ao mesmo tempo de +, Também há:
- a
*operador, que corresponde “zero ou mais”. Essencialmente o mesmo que+, exceto que você tem a opção de não encontrar uma correspondência. - a
?operador, que corresponde “zero ou um”. Tem o efeito de tornar um caractere opcional; Ou está aí ou não está, e não vai combinar mais de uma vez. - Quantificadores numéricos. Podem ser um único número, como
{3}, que significa “exatamente 3 vezes” ou uma faixa como{3-6}. Você pode pular o segundo número para torná-lo ilimitado. Como um exemplo,{3,}Isso significa “3 ou mais vezes”. curiosamente, não pode pular o primeiro número, por isso, se você quiser “3 vezes ou menos”, você terá que usar um intervalo.
Quantificadores gananciosos e preguiçosos
Sob o capô, a * e + os operadores são avarento. Corresponde o máximo possível e retorna o que é necessário para iniciar o próximo bloco. Isso pode ser um grande obstáculo..
Aqui está um exemplo: digamos que você está tentando combinar HTML ou qualquer outra coisa com colchetes de fechamento. Seu texto de entrada é:
<div>Olá Mundo</div>
E você quer combinar tudo dentro dos colchetes. Você pode escrever algo como:
<.*>
Esta é a ideia correta, mas falha por um motivo crucial: el motor Regex coincide “div>Hello World</div>“Para a sequência .*, e então faz o backup até que o próximo bloco corresponda, para este caso, com um colchete de fechamento (>). Espero que ele vai recuar apenas para combinar “div“, E, em seguida, repita novamente para corresponder ao div de fechamento. Mas o backtracker corre do final da corrente e irá parar no suporte final, que acaba combinando com tudo dentro dos colchetes.
A resposta é tornar nosso quantificador preguiçoso, o que significa que corresponderá ao mínimo de caracteres possível. Sob o capô, isso vai realmente corresponder a apenas um caractere, e então se expandirá para preencher o espaço até a próxima correspondência de bloco, o que o torna muito mais eficiente em grandes operações Regex.
Tornar um quantificador preguiçoso é feito adicionando um ponto de interrogação diretamente após o quantificador. Isso é um pouco confuso porque ? já é um quantificador (e é realmente ganancioso por padrão). Para nosso exemplo de HTML, o regex é corrigido com esta simples adição:
<.*?>
O operador preguiçoso pode ser adicionado a qualquer quantificador, incluído +?, {0,3}?, e inclusivo ??. Mesmo que o último não tenha efeito; porque você está combinando zero ou um caractere de qualquer maneira, sem espaço para expandir.
Agrupamento e Lookarounds
Os grupos no Regex têm muitos propósitos. Em um nível básico, combinar várias peças em um bloco. Como um exemplo, você pode criar um grupo e então usar um quantificador em todo o grupo:
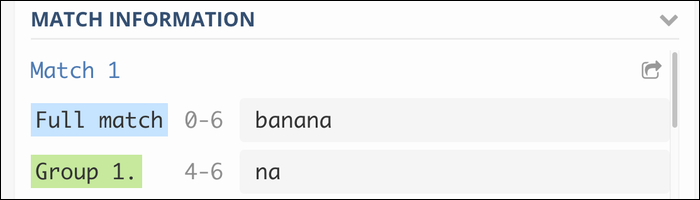
BA(sobre)+
Isso agrupa o “sobre” repetido para combinar com a frase banana, e banananana, e assim por diante. Sem o grupo, o motor Regex iria apenas corresponder ao caractere final uma e outra vez.
Este tipo de grupo com dois parênteses simples é chamado de grupo de captura e irá incluí-lo na saída:
Se você quiser evitar isso e apenas agrupar os tokens para fins de execução, você pode usar um grupo que não captura:
BA(?:sobre)
O ponto de interrogação (um personagem reservado) define um grupo fora do padrão e o próximo caractere define que tipo de grupo é. Começar grupos com um ponto de interrogação é ideal, porque caso contrário, se eu quisesse combinar ponto e vírgula em um grupo, Eu precisaria escapar deles sem um bom motivo. Mas você para sempre tem que escapar dos pontos de interrogação no Regex.
Você também pode nomear seus grupos, Por conveniência, quando trabalho com a saída:
(?'grupo')
Você pode referenciá-los em seu Regex, o que os faz funcionar de forma equivalente às variáveis. Você pode se referir a grupos não nomeados com o token 1, mas isso só vai até 7, depois disso, você precisará começar a nomear grupos. A sintaxe para se referir a grupos nomeados é:
k{grupo}
Isso se refere aos resultados do grupo nomeado, que pode ser dinâmico. Essencialmente, verifique se o grupo ocorre várias vezes, mas não se preocupa com a posição. Como um exemplo, isso pode ser usado para combinar todo o texto entre três palavras idênticas:
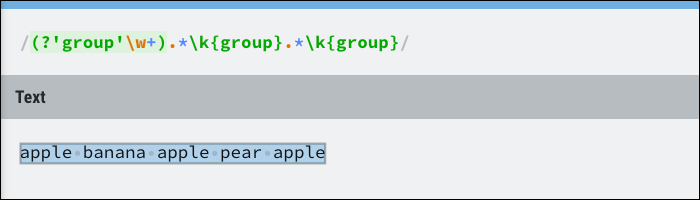
A classe de grupo é onde você encontrará a maior parte da estrutura de controle Regex, incluindo lookahead. Lookaheads garantem que uma expressão deve corresponder, mas não a inclui no resultado. De certo modo, é equivalente a uma instrução if e não corresponderá se retornar falso.
A sintaxe para um lookahead positivo é (?=). Aqui está um exemplo:
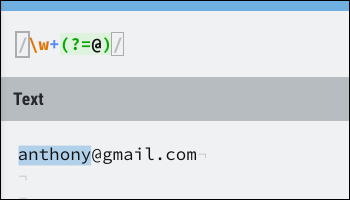
Corresponde perfeitamente à parte do nome de um endereço de e-mail, parando a execução na divisão @. As pesquisas antecipadas não consomem nenhum caractere, então, se você quiser continuar correndo depois que um lookahead for bem-sucedido, você ainda pode corresponder ao caractere usado na antecipação.
Ao mesmo tempo, das previsões positivas, Também há:
(?!)– Lookaheads negativos, que garantem uma expressão. não partida.(?<=)– Olhe atrás de positivos, que não são suportados em todos os lugares devido a algumas limitações técnicas. Eles são colocados antes da expressão que você deseja encontrar e devem ter uma largura fixa (Em outras palavras, sem quantificadores exceto{number}. Neste exemplo, Você poderia usar(?<=@)w+.w+para coincidir com a parte do domínio do e-mail.(?<!)– Negativo olha para trás, que são iguais aos olhares positivos para trás, mas negado.
Diferenças entre motores Regex
Nem todas as expressões regulares são iguais. A maioria dos motores Regex não segue nenhum padrão específico, e alguns mudam um pouco as coisas para se adequar ao seu idioma. Alguns recursos que funcionam em um idioma podem não funcionar em outro.
Como um exemplo, as versões de sed compilado para macOS e FreeBSD não suporta o uso t para representar um caractere de tabulação. Você deve copiar manualmente um caractere de tabulação e colá-lo no terminal para usar uma guia na linha de comando sed.
A maior parte deste tutorial é compatível com PCRE, o motor Regex padrão usado para PHP. Mas o motor JavaScript Regex é diferente: não suporta grupos de captura nomeados com aspas (quer colchetes) e não pode fazer recursão, entre outras coisas. Mesmo PCRE não é totalmente compatível com diferentes versões, e tem muitas diferenças regex de Perl.
Existem muitas pequenas diferenças para listar aqui, então você pode usar esta tabela de referência para comparar as diferenças entre vários motores Regex. Ao mesmo tempo, Depuradores Regex como Regex101 permite que você mude motores Regex, portanto, certifique-se de depurar usando o mecanismo correto.
Como executar o Regex
Estamos discutindo a parte correspondente do regex, que compõe a maior parte do que uma expressão regular faz. Mas quando você realmente deseja executar seu Regex, você precisará convertê-lo para um regex completo.
Isso geralmente assume o formato:
/combinar / g
Tudo dentro das barras é nosso par. a g é um modificador de modo. Para este caso, diz ao motor para não parar de funcionar após a primeira correspondência ser encontrada. Para encontrar e substituir Regex, você frequentemente terá que formatá-lo como:
/localizar / substituir / g
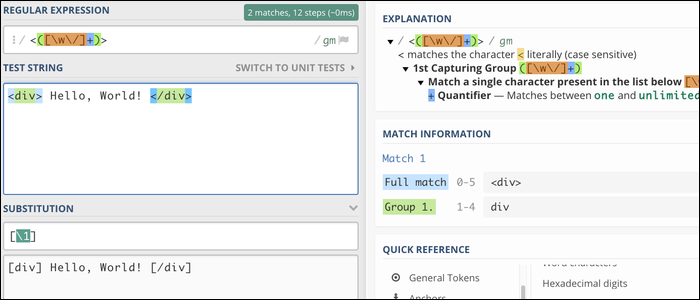
Isso substitui todo o arquivo. Você pode usar referências de grupo de captura ao substituir, o que torna o Regex muito bom na formatação de texto. Como um exemplo, esta regex irá corresponder a qualquer tag HTML e substituir os colchetes padrão por colchetes:
/<(.+?)>/[1]/g
Quando isso funcionar, o motor vai combinar <div> e </div>, que permite a você substituir este texto (e apenas este texto). Como você pode ver, HTML interno não é afetado:
Isso torna o Regex muito útil para localizar e substituir texto. O utilitário de linha de comando para fazer isso é sed, que usa o formato básico de:
arquivo sed '/ find / replace / g' > Arquivo
Isso é executado em um arquivo e enviado para STDOUT. Você precisará conectá-lo a você mesmo (como mostrado aqui) para substituir o arquivo no disco.
Regex também é compatível com muitos editores de texto e pode realmente acelerar seu fluxo de trabalho executando operações em lote.. Empurre, Átomo, e VS CodTodos têm a funcionalidade Regex de localizar e substituir incorporada.
De qualquer forma, Regex também pode ser usado por meio de programação e, em geral, é construído em muitas linguagens. A implementação exata dependerá da linguagem, então você deve consultar a documentação para o seu idioma.
Como um exemplo, e JavaScript, O regex pode ser criado literal ou dinamicamente usando o objeto RegExp global:
var re = novo RegExp('abc')
Isso pode ser usado diretamente chamando .exec() método de objeto regex recém-criado, ou usando o .replace(), .match(), e .matchAll() métodos em strings.





