Sempre que um procedimento é criado em um sistema Linux, é atribuído um novo número que o identifica em relação a outros aplicativos. Este é o ID do procedimento, o PID, e é usado em todo o sistema para gerenciar processos em execução.
Como os processos funcionam no Linux
O primeiro procedimento que o Linux executa é chamado systemd, recebendo PID 0. Todos os outros processos são gerados como filhos de systemd. Os primeiros geralmente serão coisas do Linux de baixo nível com as quais você não precisa se preocupar, mas mais abaixo na árvore, o sistema começará a lançar processos de nível de usuário como MySQL e Nginx.
Cada procedimento também possui um PPID, que armazena o PID do pai pelo qual o procedimento foi criado. Também existe um processo TTY, que armazena o ID do terminal que você usou para iniciar o procedimento, y UID, que armazena o ID do usuário que o criou. Qualquer procedimento que geralmente não tenha um TTY é chamado diabo, uma definição usada para denotar processos do sistema que são executados em segundo plano e não têm um terminal de controle.
Sempre que um procedimento é fechado, que o PID está habilitado para uso por outro procedimento. Cada procedimento também é fechado com um código de saída, que geralmente é usado para indicar se ocorreu ou não um erro. O código de saída 0 é uma saída limpa, qualquer coisa maior é um erro específico.
Em uma nota mais técnica, PIDs são uma parte importante dos namespaces do Linux. Os namespaces ocultam certas partes do sistema de processos em execução em diferentes namespaces, o que capacita ferramentas de conteinerização como Docker. Com namespaces, a árvore PID é cortada em um determinado galho, e apenas essa filial é entregue ao procedimento em contêineres. Este ramo é reiniciado a partir do PID 1, para que o contêiner pareça estar sendo executado em uma nova instalação do Linux.
Processos de visualização
Para uma lista completa de processos, pode executar o ps comando:
sudo ps -e
O que irá gerar uma lista muito longa de todos os processos em execução, o que certamente é um pouco difícil de navegar.
Você pode filtrar os resultados canalizando a saída para grep, O que ps não tem uma função de pesquisa embutida:
sudo ps -e | grep "nome do processo"
Mesmo que você deva ser avisado que, estranhamente, isto também irá corresponder ao recém-criado grep processo, O que ps mostrar argumentos de comando, que incluem sua string correspondente, que evidentemente se combina. Se você só precisa do PID de um determinado nome de procedimento, a pgrep O comando apenas retorna o PID e nada mais.
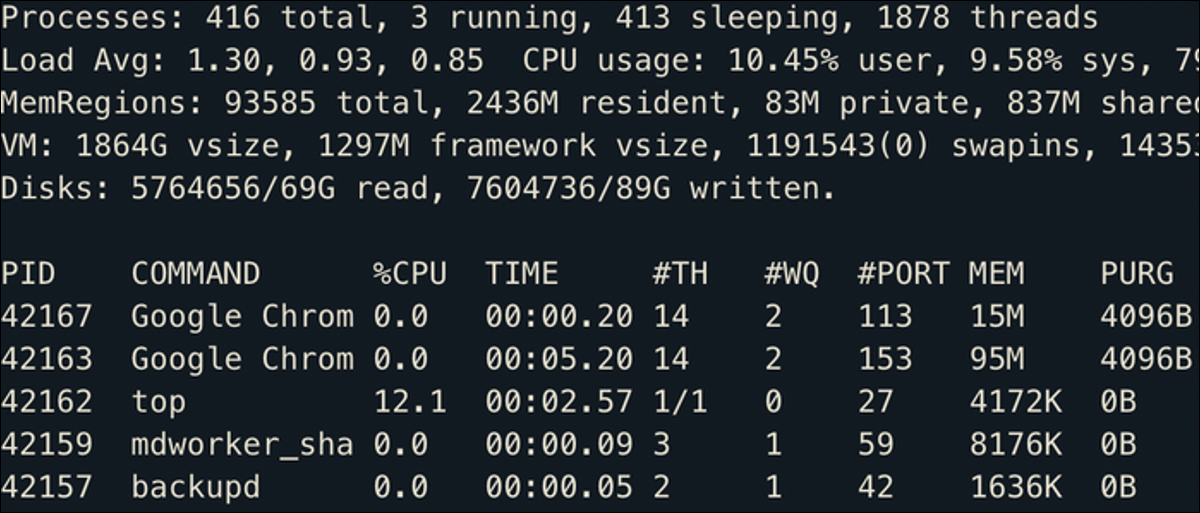
Um visualizador muito mais útil é o top comando, que atua como um gerenciador de tarefas do seu terminal. Mostra todos os processos classificados por uso de CPU, bem como algumas estatísticas gerais do sistema:
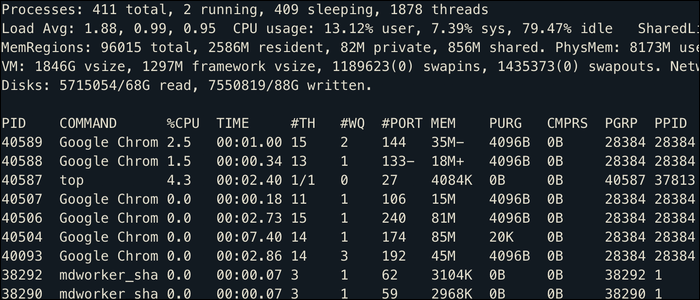
Se você estiver executando um desktop Linux, isso também mostra os aplicativos em execução no momento, mesmo que a maioria dos aplicativos seja multi-threaded, portanto, o Google Chrome preenche esta lista em execução em vários processos com diferentes PIDs.
Parar processos
Sendo realista, não fará muito com o procedimento real além de desligá-lo, já que você não terá que gerenciar a criação do procedimento. (Gerenciado automaticamente quando você executa um comando ou script). O comando para fazer isso é chamado de forma sucinta kill, que pega um determinado PID e fecha esse procedimento:
sudo matar 40589
Além disso, você pode matar todos os processos com um determinado nome usando o killall comando. Como um exemplo, para liberar um pouco de RAM em seu sistema, pode executar:
sudo killall chrome
Evidentemente, esta não é a melhor maneira de fechar aplicativos de desktop, mas a maioria dos processos não vai gerar muito barulho se forem fechados desta forma.
Apesar disto, se o procedimento for um serviço Linux, você vai querer usar o service comando para interagir com ele. Como um exemplo, recarregando o nginx:
recarregar serviço nginx
Ou desligue:
serviço nginx parar
Arquivos PID
Um ID de procedimento identifica exclusivamente um procedimento enquanto esse procedimento está em execução. Se você tiver que reiniciar o Nginx, é possível que um novo ID de procedimento seja atribuído a ele.
É aqui que os arquivos PID entram em jogo; eles são uma forma de comunicação entre processos, essencialmente um arquivo que armazena o PID atual de um determinado procedimento. Outro procedimento pode ler este arquivo e inerentemente saber, como um exemplo, qual é o PID do MySQL. Quando o MySQL inicia, escreva o seu próprio PID neste arquivo para todo o sistema ver.
Em geral, Os arquivos PID são armazenados em /var/run/, mesmo que isso seja apenas uma prática comum e não um requisito, semelhante a como os arquivos de log são armazenados em /var/log/.
A maioria dos processos com arquivos PID também terá um rodando ao mesmo tempo, o que é feito com a ajuda de arquivos de bloqueio. Arquivos de bloqueio são uma forma de determinar um sinalizador que permite apenas um procedimento iniciar ao mesmo tempo. Quando um procedimento como o Nginx é iniciado, verifica se o arquivo de bloqueio existe e, sim, não é assim, vai começar normalmente. Mas se já estiver lá, O Nginx gerará um erro e se recusará a iniciar.





