
J'ai une procédure où je dois copier toutes les images d'une page Web. J'avais l'habitude d'exécuter cette procédure avec xmllint, qui traitera un fichier XML ou HTML et imprimera les entrées que vous spécifiez. Mais lorsque mon fournisseur d'hébergement de serveur a mis à jour ses systèmes, ils n'ont pas inclus xmllint. J'ai donc dû trouver un autre moyen d'extraire une liste d'images d'une page HTML. Il s'avère que vous pouvez le faire en bash.
Vous ne pensez peut-être pas que Bash peut analyser les fichiers de données, mais vous pouvez le faire avec une réflexion intelligente. Frapper, de la même manière que les autres shells UNIX précédents, vous pouvez analyser les lignes une par une à partir d'un fichier via la fonction intégrée read déclaration.
Par défaut, les read l'instruction scanne une ligne de données et la divise en champs. Généralement, read diviser les champs à l'aide d'espaces et de tabulations, avec de nouvelles lignes à la fin de chaque ligne, mais vous pouvez modifier ce comportement en définissant le séparateur de champ interne (IFS) valeur et le délimiteur de fin de ligne (-d).
Pour analyser un fichier HTML en utilisant read , sélectionnez le IFS à un symbole supérieur à (>) et le délimiteur d’un symbole inférieur à (<). Chaque fois que Bash scanne une ligne, numériser jusqu’à la prochaine fois < (le début d’une balise HTML) puis divisez ces données en chacun > (la fin d’une balise HTML). Cet exemple de code prend une ligne d’entrée et divise les données en TAG Oui VALUE variables:
IFS local='>'
read -d '<' VALEUR DE LA BALISE
Explorons comment cela fonctionne. Considérez ce fichier HTML simple:
<img src="https://www.systempeaker.com/8315/parsing-html-in-bash/logo.png" alt="Mon logo" /> <p>un peu de texte</p>
La première fois read analyse ce fichier, s'arrête au premier < symbole. Puisque < est le premier caractère de cet exemple d'entrée, ce qui signifie que Bash trouve une chaîne vide. La résultante TAG Oui VALUE les chaînes sont aussi vides. Mais c'est bien pour mon cas d'utilisation.
La prochaine fois que Bash lit l'entrée, avoir img src="https://www.systempeaker.com/8315/parsing-html-in-bash/logo.png"↲alt="My logo" />↲ avec une nouvelle ligne juste avant l'alt, et s'arrête avant < symbole dans la ligne suivante. Après read divise la ligne au > symbole, ce qui laisse TAG avec img src="https://www.systempeaker.com/8315/parsing-html-in-bash/logo.png"↲alt="My logo" / Oui VALUE avec une nouvelle ligne vide.
La troisième fois read analyser le fichier HTML, avoir p>some text. Bash divise la chaîne au > Résultant en TAG contenant p Oui VALUE avec some text .
Maintenant que vous comprenez comment utiliser read, il est facile d’analyser un fichier HTML plus long avec Bash. Commencer avec une fonction Bash appelée xmlgetnext pour analyser les données à l’aide de read , puisqu’il le fera encore et encore dans le script. J’ai nommé mon rôle xmlgetnext pour me rappeler qu’il s’agit d’un remplacement pour Linux xmllint Programme, mais j’aurais pu l’appeler tout aussi facilement htmlgetnext .
xmlgetnext () {
IFS local='>'
read -d '<' VALEUR DE LA BALISE
}
Maintenant, appelez cela. xmlgetnext pour analyser le fichier HTML. Ceci est mon complet htmltags texte:
#!/poubelle/sh # print a list of all html tags xmlgetnext () { IFS local='>' read -d '<' VALEUR DE LA BALISE } chat $1 | tandis que xmlgetnext ; faire écho $TAG ; terminé
La dernière ligne est la clé. Parcourez le fichier en utilisant xmlgetnext pour analyser le HTML et imprimer uniquement le TAG billets. Et pour comment echo fonctionne avec des séparateurs de champs standard, n'importe quelle ligne comme img src="https://www.systempeaker.com/8315/parsing-html-in-bash/logo.png"↲alt="My logo" / contenant une nouvelle ligne sont imprimés sur une seule ligne, Quoi img src="https://www.systempeaker.com/8315/parsing-html-in-bash/logo.png" alt="My logo" /.
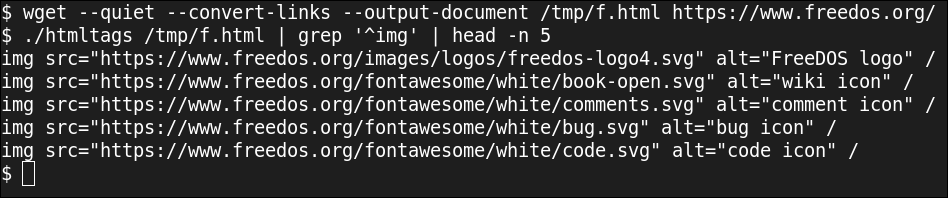
Pour obtenir uniquement la liste des images, Je lance la sortie de ce script via grep pour imprimer uniquement les lignes qui ont un img étiquette en début de ligne.





