
Bash est un shell et un langage de codage idéal, vous permettant de créer des scripts d'automatisation haut de gamme. Dans cette deuxième partie de la série, nous verrons la densité d'encodage, commentaires en ligne et guillemets corrects des variables à l'aide de guillemets simples ou doubles.
Bases de l'automatisation Bash et scripts
Si vous ne l'avez pas déjà fait, et ça ne fait que commencer dans bash, lea nuestro post Bash Automation and Scripting Basics Part 1. Ceci est le deuxième article de notre série en trois parties sur l'automatisation bash et les bases des scripts. Dans le post d'aujourd'hui, nous verrons, entre autres sujets, Densité d'encodage Bash et sa connexion aux préférences du développeur. Nous verrons également les commentaires en ligne en lien avec cette.
Une fois que nous avons commencé à créer de petits scripts, nous explorons les variables et travaillons avec des chaînes de texte, on se rend vite compte qu'il peut y avoir une différence conceptuelle entre les guillemets simples et doubles. Il y a, et dans le deuxième sujet ci-dessous, nous allons plonger dans ce.
Densité et concision de l'encodage Bash
Le langage de codage Bash peut être très dense et concis, mais il peut aussi être spacieux et détaillé. Dépend fortement des préférences du développeur.
Par exemple, le code Bash suivant:
vrai || echo 'faux'
qui peut être lu comme Ne rien faire et le faire avec succès (code de sortie 0), et si cela échoue (peut lire l'idiome Bash || venez OU) affiche le texte 'faux’, peut aussi s'écrire comme:
si [ ! vrai ]; then
echo 'untrue'
fi
Ce qui rend le code un peu différent, mais ça fait pareil.
Ceci à son tour peut être lu comme Si c'est vrai ce n'est pas (sens pour lui ! idiome) vrai, puis il affiche le texte 'faux’.
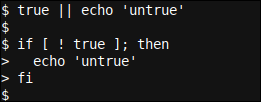
Les deux mini-scripts donnent la même sortie vide, Quoi certain ce n'est pas faux.
La multitude de commandes et d'outils disponibles (ou installable) à partir de et sur la ligne de commande étendre davantage le défilement réalisable entre les scripts hautement lisibles et le code dense, concis et difficile à comprendre.
Bien que les exemples ci-dessus soient courts et relativement faciles à comprendre, quand tu crées une longue file (une définition souvent utilisée par les développeurs Bash pour indiquer un extrait de code, composé de plusieurs commandes, écrit sur une ligne) en utilisant beaucoup de ces commandes , au lieu de mettre la même chose dans un script plus détaillé, la différence devient plus claire. À envisager:
V ="$(dormir 2 & fg; echo -n '1' | mais c'est|[0-9]|une|')" && écho "${V}" | mais c'est|[a-z]|2|g' || echo 'échec'

Il s'agit d'un script Bash à une seule ligne typique qui utilise les commandes sleep, fg, echo, et sed ainsi que divers idiomes et regex Bash pour simplement dormir 2 secondes, générer du texte et transformer ce texte en utilisant des expressions régulières. Le script vérifie aussi régulièrement les conditions / Résultats de la commande précédente via l'utilisation d'idiomes Bash || (si pas réussi, faire ce qui suit) et && (si réussi, faire ce qui suit)
j'ai traduit ça, avec fonctionnalité de correspondance floue, à un script plus complet, avec quelques modifs. Par exemple, nous changeons notre fg (amene le sleep commande placée en arrière plan retour au premier plan, et attendez qu'il se termine comme des processus normaux sans arrière-plan) afin de wait à quoi s'attend le PID du sommeil (commencé par eval et capturé en utilisant l'idiome Bash $!) pour terminer.
#!/bin/bash CMD="dormir 2" eval ${CMD} & attendre $! EXIT_CODE=${?} V ="$(echo -e "${CMD}n1" | mais c'est|[0-9]|une|')" si [ ${EXIT_CODE} -Eq 0 ]; then echo "${V}" | mais c'est|[a-z]|2|g' EXIT_CODE=${?} si [ ${EXIT_CODE} -ne 0 ]; then echo 'fail' fi fi
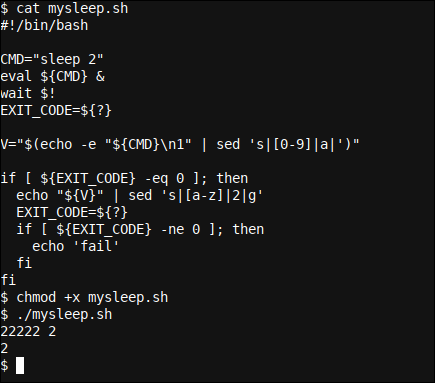
Quelle différence! et c'est juste une développeur l'écrivant dans leur chemin. Le code Bash écrit par d'autres a tendance à être quelque peu difficile à lire, et que la difficulté augmente rapidement avec la densité et la concision. Même comme ça, un développeur Bash de niveau expert comprendra rapidement même le code très dense et concis écrit par d'autres, à quelques exceptions près, par exemple, expressions régulières.
Pour plus d'informations sur l'écriture d'expressions régulières, jetez un oeil à Comment modifier du texte à l'aide de regex avec sed Stream Editor.
A partir de ces exemples, il est clair que votre kilométrage variera dans le temps. Malgré cela, en général, la facilité d'utilisation du programmeur est recommandée (écrire du code très lisible) chaque fois que vous commencez à développer des scripts bash.
Si vous devez créer un code dense et concis, peut fournir de nombreux commentaires en ligne. Une ligne précédée d'un # est considéré comme une ligne de commentaire / observation, et le symbole # peut même être utilisé vers la fin d'une ligne après n'importe quelle commande exécutable, pour poster un commentaire suffixe expliquant la commande, instruction conditionnelle, etc. Par exemple:
# Ce code va dormir une seconde, twice sleep 1 # First sleep sleep 1 # Deuxième sommeil
Guillemets simples ou guillemets doubles?
En bas, texte entre guillemets simples (') sont pris comme texte littéral par l'interpréteur Bash, tandis que le texte entre guillemets doubles (") est interprété (analysé) par l'interprète de Bash. Bien que la différence dans la façon dont les choses fonctionnent peut ne pas être immédiatement claire à partir de cette définition, L'exemple suivant nous montre ce qui se passe lorsque nous échangeons ' pour " et vice versa:
écho ' $(écho "Bonjour le monde") '
echo " $(echo 'Bonjour le monde') "

Dans le premier exemple, le texte $(echo "Hello world") est considéré comme un texte littéral, donc la sortie est simplement $(echo "Hello world") . Malgré cela, pour le deuxième exemple, la sortie est Hello world .
L'interpréteur Bash a analysé le texte entre guillemets doubles pour voir s'il trouvait des langages Bash spéciaux sur lesquels agir. Un tel idiome a été trouvé dans $( ... ) qui démarre simplement une sous-couche et exécute tout ce qui est présent entre le ( ... ) expressions idiomatiques. Considérez-le comme une coquille dans une coquille, un sous-shell, qui exécute tout ce qui lui arrive comme une commande absolument nouvelle. La sortie de toute commande ou commandes de ce type est renvoyée au shell de niveau supérieur et insérée à l'endroit exact où le sous-shell a été démarré.
Pour cela, notre sous-couche a couru echo 'Hello world' dont la sortie est Hello world. Une fois cela fait, la sous-couche est terminée et le texte Hello world a été inséré à la place du $( ... ) appel de sous-couche (pense comme tout $( ... ) le code est remplacé par toute sortie générée par la sous-couche.
Le résultat, pour la coque supérieure, est la commande suivante: echo " Hello world ", dont la sortie est Hello world comme nous l'avons vu.
Notez que nous changeons les guillemets doubles à l'intérieur de la sous-couche en guillemets simples. Ce n'est pas nécessaire! On s'attendrait à voir une erreur d'analyse lorsqu'une commande prend la syntaxe de echo " ... " ... " ... ", dans le sens où les deuxièmes guillemets se termineraient par le premier, suivi d'autres tests et, pour cela, provoquerait une erreur. Malgré cela, Ce n'est pas le cas.
Et ce n'est pas parce que Bash est flexible avec plusieurs chaînes de citations (vous acceptez echo 'test'"More test"'test' Heureusement, par exemple), mais parce que la sous-couche est une coque elle-même et, pour cela, les guillemets doubles peuvent être utilisés, de nouveau, dans la sous-couche. Essayons ceci avec un exemple supplémentaire:
écho "$(écho "$(écho "plus de guillemets")")"
![]()
Cela fonctionnera bien et produira la sortie more double quotes. Les deux sous-couches imbriquées (s'exécutant dans le shell principal à partir duquel vous l'exécutez) J'accepte, à la fois, guillemets doubles et aucune erreur n'est générée, même si plusieurs guillemets doubles sont imbriqués dans la commande générale à une seule ligne. Cela montre une partie de la puissance de programmation de Bash.
En résumé
Après avoir exploré la densité d'encodage, nous réalisons la valeur d'écrire un code hautement lisible. Cependant, si nous devons faire un code dense et concis, nous pouvons ajouter de nombreux commentaires en ligne en utilisant # pour une lisibilité aisée. Nous examinons les guillemets simples et doubles et comment leur fonctionnalité diffère considérablement.
Nous analysons également brièvement les commentaires en ligne dans les scripts, ainsi que la fonctionnalité de la sous-couche lorsqu'elle est exécutée à partir d'une chaîne entre guillemets. En conclusion, nous avons vu comment une sous-couche peut utiliser un autre jeu de guillemets sans affecter de quelque façon que ce soit les guillemets utilisés à un niveau supérieur.
En Bash Automatisation et bases de scripts (Partie 3), nous discutons du débogage de script et plus. apprécier!





