
Logiciel d'accréditation de caractères optiques (OCR) la haute qualité a peut-être été chère dans le passé, mais maintenant c'est activé, gratuit, directement depuis la ligne de commande de votre terminal Linux. Cet article vous aidera à configurer et à démarrer avec l'OCR.
Qu'est-ce que l'OCR?
L'acronyme OCR signifie Accréditation des caractères optiques: un programme logiciel et un système grâce auxquels un ordinateur peut lire le texte dans les images. Imaginez prendre une photo de votre passage préféré de l'un des livres du Seigneur des Anneaux.
Voulez-vous le citer ailleurs, mais il n'a qu'une photo. Le logiciel OCR peut vous aider en analysant cette photo / image et trouver tout le texte qu'elle contient.
Après, le logiciel OCR analysera, pour chaque lettre découverte, les points graphiques vus dans l'image et les traduire / se transformera en texte réel qu'un ordinateur peut utiliser, par exemple, dans un traitement de texte.
Bien qu'il existe de nombreux programmes d'OCR disponibles, certains payants et d'autres gratuits, tous ne sont pas de la même qualité. Certains packages fourniront des résultats de moins bonne qualité, d'autres s'aligneront étroitement sur le texte vu sur la photo ou l'image.
En termes générales, livres standards (ou impressions de pages Web Internet) fonctionnera très bien et devrait produire des résultats de qualité raisonnable dans tous les cas, puisque les sources sont droites et uniformes et ne forment qu'un seul angle, tant que la photo ou le scan d'origine est d'une taille raisonnable. qualité.
Il est également bon de faire attention au fait que même les progiciels avancés peuvent avoir des problèmes avec des images de mauvaise qualité ou floues., et la plupart des packages peuvent avoir des problèmes avec différents styles d'écriture, etc. D'autres défis peuvent inclure du texte mélangé avec des images ou des photos, ou directions différentes (par exemple, gauche (texte à droite, de haut en bas ou en biais) dans la même page.
Cela rend la sélection, et éventuellement payer, un package OCR est une procédure peut-être longue, surtout si vous voulez tester et examiner chaque paquet.
Pour ceux qui utilisent Linux, il y a un excellent itinéraire alternatif. Un logiciel OCR de haute qualité et gratuit basé sur LSTM Neural Net avec prise en charge Unicode (UTF-8) et qu'il peut reconnaître plus de 100 langues par défaut. Il prend également en charge de nombreux formats de sortie tels que HTML, PDF et texte brut.
Sans plus de préambules; Bienvenue sur Tesseract OCR!
installation Tesseract OCR
Installer Tesseract OCR sur votre distribution Linux basée sur Debian / Apte (comme Ubuntu et Mint), Fabriquer:
sudo apt install tesseract-ocr libtesseract-dev tesseract-ocr-eng
Installer Tesseract OCR chez RHEL et Centos, faire ce qui suit:
sudo yum install epel-releasesudo yum install tesseract-devel leptonica-devel
Installer Tesseract OCR à Fedora, fais:
sudo yum install tesseract-devel leptonica-devel
Installer Tesseract OCR sur OSX, Faites ce qui suit:
brew install tesseract
Passons à l'OCR!
Nous utiliserons une image simple qui contient le texte suivant:

Pour convertir cette image, tout ce que vous avez à faire est d'ouvrir l'invite du terminal, changer de répertoire (en utilisant le cd your_directory_with_images commander) vers le répertoire contenant vos images (par exemple, si vous avez créé un répertoire d'images dans votre répertoire personnel (~/images) vous pouvez simplement utiliser cd ~/images) et OCR de fichiers:
tesseract -l eng input_for_ocr.png output_from_ocr
cat output_from_ocr.txt
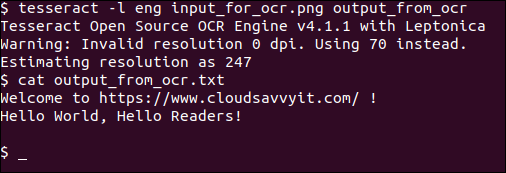
très simple et directe. Et comment pouvons-nous voir, le rendu est parfait.
Nous spécifions la langue anglaise en utilisant le -l eng option. Vous pouvez consulter le manuel de tesseract (man tesseract) pour tout autre code de langue disponible.
Nous spécifions également l'image d'entrée (input_for_ocr.png) ainsi que le fichier de sortie output_from_ocr sans aucune extension de fichier, qui utilisera le texte brut par défaut .txt format.
Nous pouvons également changer le format de sortie en PDF en utilisant une commande légèrement plus longue qui spécifie simplement le format de sortie à la fin:
tesseract -l fra input_for_ocr.png output_from_ocr pdf

Ajout du pdf suffixe, le format de sortie utilisé était PDF. Lorsque nous ouvrons le fichier PDF (sortie_de_ocr.pdf), on voit que le texte peut être choisi et copié / coller comme on l'a fait avec le mot Lecteurs! ici:
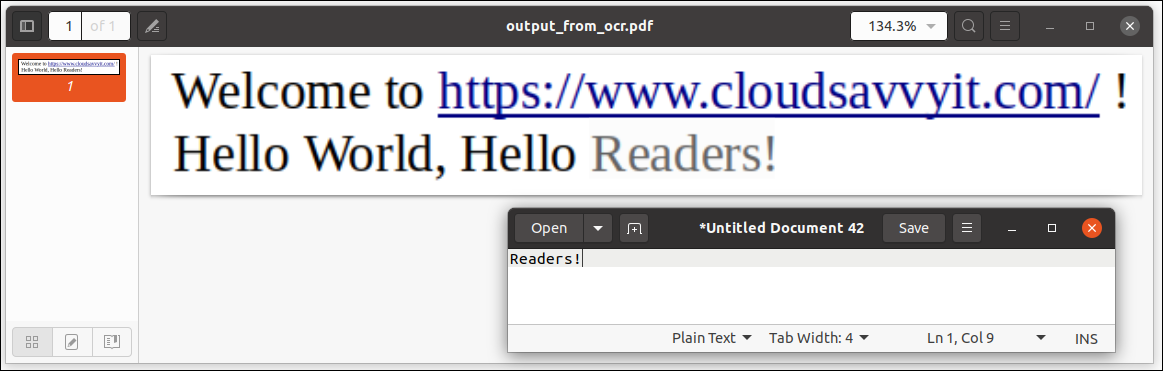
En d'autres termes, Le fichier PDF contient des données sélectionnables et basées sur du texte, aucune information graphique (et donc non sélectionnable). Excellent!
Que faire si je veux OCR un fichier PDF?
Parfois, vous pouvez recevoir un fichier PDF qui, même si le format PDF prend en charge le texte réel dans les pages, contient uniquement des images avec du texte. Cela peut être frustrant, puisque le copier-coller ne sera pas disponible. Vous pouvez également OCR ces pages, avec une petite solution.
Vous voudrez d'abord convertir votre fichier PDF en images, une image par page, et plus tard OCR les pages individuelles dans le texte. Encore un peu de boulot, mais encore gagner beaucoup de temps au lieu de retaper le texte manuellement.
Connaître les étapes simples pour convertir un fichier PDF en images, ou même pour créer un script et automatiser la conversion de plusieurs fichiers PDF, vous pouvez lire notre article Convertir un PDF en images à partir de la ligne de commande Linux.
Fin
Dans ce billet, nous explorons Tesseract, le moteur OCR de ligne de commande sans frais de haute qualité pour Linux. Nous avons vu comment nous pouvions facilement convertir des images en texte à l'aide d'une simple commande.
Nous analysons également la conversion d'images en fichiers PDF textuels, et nous avons mentionné un article où vous pouvez trouver des informations sur la façon de pré-convertir des fichiers PDF basés sur des images en images afin qu'ils puissent ensuite être convertis en texte à l'aide de la méthode OCR illustrée ici.
Prendre plaisir!





