Le tri d'un fichier journal par une colonne spécifique est utile pour trouver rapidement des informations. Les enregistrements sont généralement stockés sous forme de texte brut, vous pouvez donc utiliser des outils de manipulation de texte en ligne de commande pour les traiter et les afficher de manière plus lisible.
Extraire les colonnes avec cut et awk
Les cut Oui awk Les utilitaires sont deux manières différentes d'extraire une colonne d'informations à partir de fichiers texte. Ils supposent tous les deux que vos fichiers journaux sont délimités par des espaces, par exemple:
colonne colonne colonne
Cela présente un barrage routier si les données dans les colonnes contiennent des blancs, comme les dates (“mercredi 12 de juin”). Temps cut vous pouvez voir cela comme trois colonnes distinctes, vous pouvez toujours extraire les trois en même temps, en supposant que la structure de votre fichier journal est cohérente.
cut c'est très simple à utiliser:
chat system.log | couper -d ' ' -f 1-6
Les cat commande lit le contenu de system.log et le canalise vers cut. Les -d flag spécifie le délimiteur, pour ce cas un espace vide. (La valeur par défaut est l'onglet, t.) Les -f indicateur spécifie les champs à générer. Cette commande imprimera spécifiquement les six premières colonnes de system.log. Si je voulais seulement imprimer la troisième colonne, j'utiliserais le -f 3 drapeau.
awk est plus puissant mais pas aussi concis. cut est utile pour extraire des colonnes, comme si vous vouliez obtenir une liste d'adresses IP à partir de vos journaux Apache. awk peut réorganiser des lignes entières, ce qui peut être utile pour trier un document entier par une colonne spécifique. awk est un langage de programmation complet, mais vous pouvez utiliser une simple commande pour imprimer des colonnes:
chat system.log | ah '{imprimer $1, $2}'
awk exécutez votre commande pour chaque ligne du fichier. Par défaut, diviser le fichier par des espaces et stocker chaque colonne dans des variables $1, $2, $3, etc. En utilisant le print $1 commander, peut imprimer la première colonne, mais il n'y a pas de moyen facile d'imprimer une plage de colonnes sans utiliser de boucles.
Un avantage de awk est que la commande peut faire référence à toute la ligne en même temps. Le contenu de la ligne est stocké dans la variable $0, que vous pouvez utiliser pour imprimer toute la ligne. Ensuite, pourrait, par exemple, imprimer la troisième colonne avant d'imprimer le reste de la ligne:
ah '{imprimer $3 " " $0}'
Les " " imprime un espace entre $3 Oui $0. Cette commande répète la colonne trois deux fois, mais vous pouvez le corriger en définissant le $3 variable à null:
ah '{imprimer $3; $3=""; imprimer " " $0}'
Les printf La commande n'imprime pas de nouvelle ligne. De la même manière, vous pouvez exclure des colonnes spécifiques de la sortie en les définissant toutes sur des chaînes vides avant l'impression $0:
ah '{$1=$2=$3=""; imprimer $0}'
Vous pouvez faire beaucoup plus avec awk, comprenant correspondance d'expressions régulières, mais l'extraction de colonne prête à l'emploi fonctionne bien pour ce cas d'utilisation.
Trier les colonnes avec sort et uniq
Les sort La commande peut être utilisée pour trier une liste de données en fonction d'une colonne spécifique. La syntaxe est:
trier -k 1
où il -k flag indique le numéro de la colonne. Vous dirigez l'entrée vers cette commande et crachez une liste ordonnée. Par défaut, sort utilise l'ordre alphabétique mais prend en charge plus d'options via les drapeaux, Quoi -n pour la classification numérique, -h pour trier les suffixes (1M> 1K), -M classer les abréviations par mois, Oui -V pour trier les numéros de version de fichier (fichier-1.2.3> fichier-1.2.1).
Les uniq La commande filtre les lignes en double, ne laissant que les seuls. Ne fonctionne que pour les lignes adjacentes (pour des raisons de performances), vous devriez donc toujours l'utiliser après sort pour supprimer les doublons dans tout le fichier. La syntaxe est simplement:
trier -k 1 | unique
Si vous ne souhaitez lister que les doublons, utiliser el -d drapeau.
uniq vous pouvez également compter le nombre de doublons avec le -c drapeau, ce qui le rend très bon pour le suivi de fréquence. Par exemple, si vous souhaitez obtenir une liste des principales adresses IP atteignant votre serveur Apache, vous pouvez exécuter la commande suivante dans votre access.log:
couper -d ' ' -f 1 | sorte | uniq -c | trier non | diriger
Cette chaîne de commande coupera la colonne d'adresse IP, regroupera les doublons, supprimera les doublons en comptant chaque occurrence, puis il triera en fonction de la colonne de comptage dans l'ordre numérique décroissant, vous laissant avec une liste qui ressemble à ceci:
21 192.168.1.1 12 10.0.0.1 5 1.1.1.1 2 8.0.0.8
Vous pouvez appliquer ces mêmes techniques à vos fichiers journaux, en même temps d'autres utilitaires tels que awk Oui sed, pour extraire des informations utiles. Ces commandes enchaînées sont longues, mais vous n'avez pas besoin de les écrire tout le temps, puisque vous pouvez toujours les stocker dans un script bash ou des alias via votre ~/.bashrc.
Filtrage des données avec grep et awk
grep c'est une commande très simple; vous donne une définition de recherche et vous transmet l'entrée, et cracher chaque ligne qui contient ce terme de recherche. Par exemple, si vous voulez rechercher des erreurs 404 dans le journal d'accès Apache, vous pouvez faire ce qui suit:
chat access.log | grep "404"
qui cracherait une liste d'entrées de registre qui correspondent au texte donné.
Malgré cela, grep vous ne pouvez pas limiter votre recherche à une colonne spécifique, donc cette commande échouera si vous avez le texte “404” n’importe où ailleurs dans le fichier. Si vous voulez juste regarder la colonne du code d'état HTTP, doit utiliser awk:
chat access.log | ah '{si ($9 == "404") imprimer $0;}'
Avec awk, il a aussi l'avantage de pouvoir effectuer des recherches négatives. Par exemple, vous pouvez rechercher toutes les entrées de registre qui je ne l'ai pas fait retour avec code d'état 200 (d'accord):
chat access.log | ah '{si ($9 != "200") imprimer $0;}'
tout en ayant accès à toutes les fonctions programmatiques awk fournit.
Options de l'interface graphique pour les journaux Web
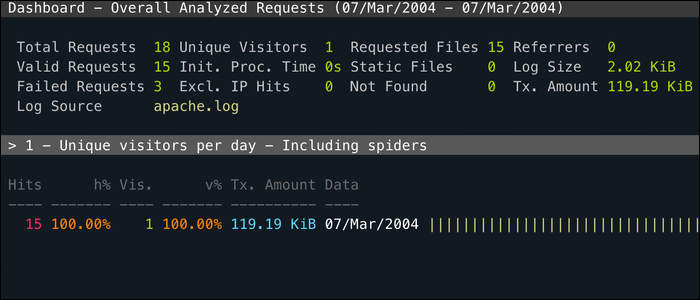
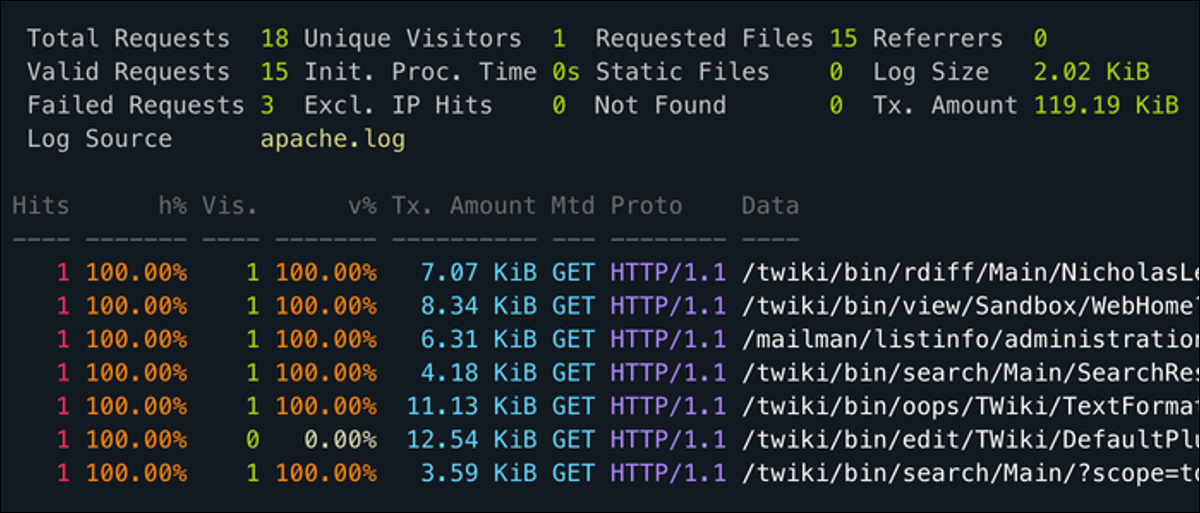
GoAccès est un utilitaire CLI pour surveiller le journal d'accès de votre serveur Web en temps réel et classer par chaque champ utile. Fonctionne entièrement sur votre terminal, donc vous pouvez l'utiliser via SSH, mais il a aussi une interface web beaucoup plus intuitive.
apachetop est un autre utilitaire spécifique pour Apache, qui peut être utilisé pour filtrer et trier par colonnes dans votre journal d'accès. Il s'exécute en temps réel directement dans votre access.log.





