
Sous Linux curl La commande peut faire bien plus que télécharger des fichiers. Découvrir quoi curl il est capable de, et quand devriez-vous l'utiliser au lieu de wget.
boucle contre. wget: Quelle est la différence?
Les gens ont souvent du mal à identifier les forces relatives des wget et curl commandes. Les commandes ont un certain chevauchement fonctionnel. Chacun peut récupérer des fichiers à partir d'emplacements distants, mais c'est là que s'arrête la similitude.
wget c'est un outil fantastique pour télécharger du contenu et des fichiers. Vous pouvez télécharger des fichiers, pages Web et répertoires. Il contient des routines intelligentes pour parcourir des liens sur des pages Web et télécharger du contenu de manière récursive dans un portail Web entier.. C'est sans pareil en tant que gestionnaire de téléchargement en ligne de commande.
curl satisfaire un besoin complètement différent. Oui, peut récupérer des fichiers, mais vous ne pouvez pas parcourir de manière récursive un portail Web à la recherche de contenu à récupérer. Quoi curl ce qu'il fait vraiment, c'est vous permettre d'interagir avec des systèmes distants en faisant des demandes à ces systèmes et en récupérant et en affichant leurs réponses. Ces réponses peuvent être des fichiers et du contenu de site Web, mais ils peuvent également contenir des données fournies via un service Web ou une API à la suite de l' “question” fait par l’application curl.
ET curl pas limité aux sites Web. curl prend en charge plus de 20 protocoles, y compris HTTP, HTTPS, SCP, SFTP et FTP. Et éventuellement, en raison de sa gestion supérieure des tuyaux Linux, curl peut être plus facilement intégré à d'autres commandes et scripts.
L'auteur de curl a un site Web qui décrivez les différences que vous voyez Parmi curl et wget.
Pose de boucles
Des ordinateurs utilisés pour rechercher ce poste, Feutre 31 et Manjaro 18.1.0 Ils avaient curl déjà installé. curl il devait être installé sur Ubuntu 18.04 C'EST. Sous Ubuntu, exécutez cette commande pour l'installer:
sudo apt-get install curl

La version boucle
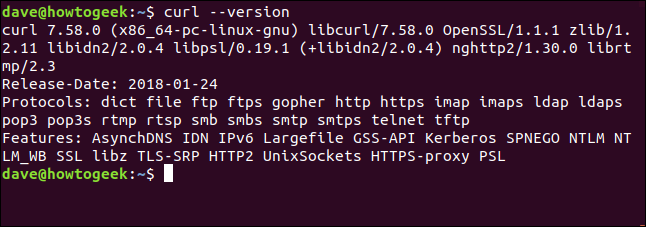
Les --version option fait curlsignaler votre version. Il répertorie également tous les protocoles qu'il prend en charge.
curl --version
Récupérer une page Web
Si nous visons curl Sur un site Internet, le récupérera pour nous.
boucle https://www.bbc.com

Mais son action par défaut est de le télécharger dans la fenêtre du terminal en tant que code source.
Faire attention: Si tu ne dis pas curl voulez quelque chose stocké sous forme de fichier, ce sera pour toujours le jeter dans la fenêtre du terminal. Si le fichier que vous récupérez est un fichier binaire, le résultat peut être imprévisible. Le shell peut essayer d'interpréter certaines des valeurs d'octets dans le fichier binaire comme des caractères de contrôle ou des séquences d'échappement.
Enregistrer les données dans un fichier
Disons à curl de rediriger la sortie vers un fichier:
boucle https://www.bbc.com > bbc.html

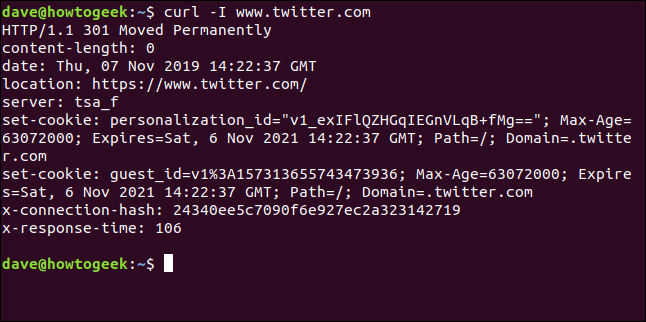
Cette fois, nous ne voyons pas les informations récupérées, envoyé directement aux archives par nos soins. Parce qu'il n'y a pas de sortie de fenêtre de terminal à afficher, curl génère un ensemble d'informations de progression.
Vous ne l'avez pas fait dans l'exemple ci-dessus car les informations de progression auraient été dispersées dans le code source de la page Web, Pour ce que curl supprimé automatiquement.
Dans cet exemple, curl détecte que la sortie est redirigée vers un fichier et qu'il est sûr de générer les informations de progression.
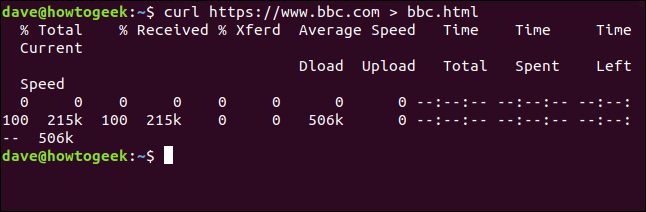
Les informations fournies sont:
- % Le total: Le montant total à récupérer.
- % Il a reçu: Le pourcentage et les valeurs réelles des données récupérées jusqu'à présent.
- % Xferd: Le pourcentage et l'expédition réelle, si les données sont en cours de chargement.
- Téléchargement à vitesse moyenne: Vitesse de téléchargement moyenne.
- Charge à vitesse moyenne: Vitesse de téléchargement moyenne.
- Temps total: La durée totale estimée du transfert.
- Temps utilisé: Le temps écoulé jusqu'à présent pour ce transfert.
- Temps restant: Le temps estimé restant pour que le transfert se termine.
- Vitesse actuelle: La vitesse de transfert actuelle pour ce transfert.
Parce que nous redirigeons la sortie de curl dans un fichier, maintenant nous avons un fichier appelé “bbc.html”.
En double-cliquant sur ce fichier, votre navigateur par défaut s'ouvrira pour afficher la page Web récupérée.
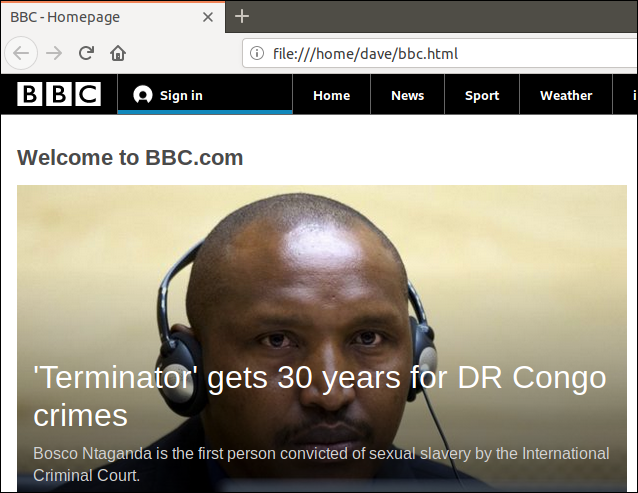
Veuillez noter que l'adresse dans la barre d'adresse du navigateur est un fichier local sur cet ordinateur, pas un portail Web distant.
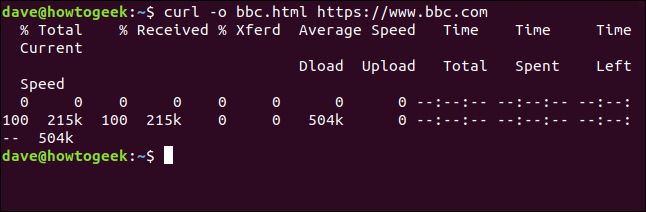
Nous ne devons pas réorienter la sortie pour créer un fichier. Nous pouvons créer un fichier en utilisant le -o (Sortir) option, et en disant curl pour créer le fichier. Ici, nous utilisons le -o et fournir le nom du fichier que nous aspirons à créer “bbc.html”.
curl -o bbc.html https://www.bbc.com
Utiliser une barre de progression pour surveiller les téléchargements
Pour que les informations de téléchargement textuelles soient remplacées par une simple barre de progression, utiliser el -# (barre de progression) option.
curl -x -o bbc.html https://www.bbc.com

Redémarrer un téléchargement interrompu
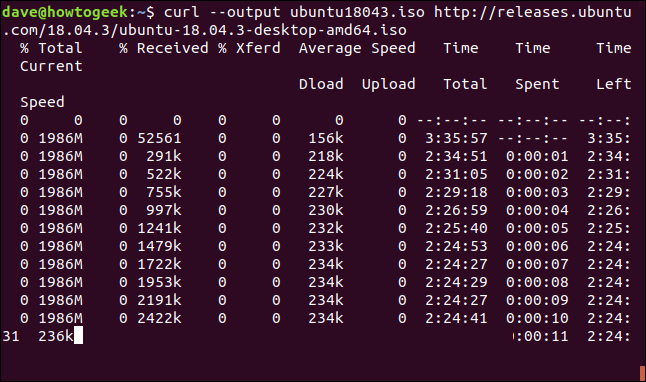
Il est facile de redémarrer un téléchargement terminé ou interrompu. Commençons par télécharger un fichier volumineux. Nous utiliserons la dernière version de support à long terme d'Ubuntu 18.04. Nous utilisons le --output option pour spécifier le nom du fichier dans lequel nous désirons l'enregistrer: “ubuntu180403.iso”.
curl --sortie ubuntu18043.iso http://releases.ubuntu.com/18.04.3/ubuntu-18.04.3-desktop-amd64.iso

Le téléchargement commence et progresse jusqu'à la fin.
Si nous interrompons de force la décharge avec Ctrl+C , on revient à l'invite de commande et le téléchargement est abandonné.
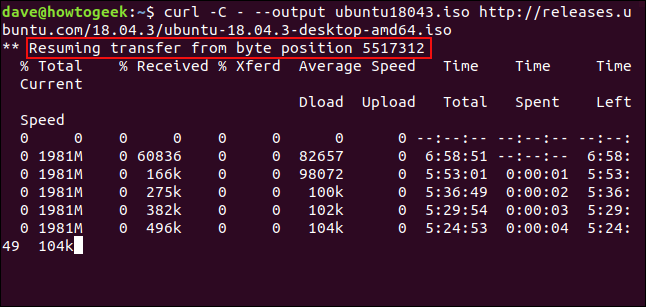
Pour redémarrer le téléchargement, utiliser el -C (continuer sur) option. Ce qui provoque curl pour redémarrer le téléchargement à un point spécifié ou compenser dans le fichier de destination. Si vous utilisez un tiret - comme le déplacement, curl examinera la partie déjà téléchargée du fichier et déterminera le décalage correct à utiliser pour lui-même.
boucle -C - --sortie ubuntu18043.iso http://releases.ubuntu.com/18.04.3/ubuntu-18.04.3-desktop-amd64.iso

Le téléchargement redémarre. curl signale le décalage auquel il redémarre.
Récupérer les en-têtes HTTP
Avec lui -I (diriger), ne peut récupérer que les en-têtes HTTP. C'est la même chose que d'envoyer le TÊTE HTTP Comando à un serveur Web.
curl -I www.twitter.com

Cette commande ne récupère que des informations; ne télécharge pas les pages Web ou les fichiers.
Télécharger à partir de plusieurs URL
À l'aide de xargs nous pouvons télécharger plusieurs URL tout de suite. Peut-être voulons-nous télécharger une série de pages Web qui constituent un seul article ou tutoriel.
copier ces URL dans un éditeur et les enregistrer dans un fichier appelé “URLs-à-télécharger.txt”. On peut utiliser xargs pour traiter le contenu de chaque ligne du fichier texte en tant que paramètre qui alimentera curl, Successivement.
https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#0 https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#1 https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#2 https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#3 https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#4 https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#5
C’est la commande que nous devons utiliser pour avoir xargs transmettre ces URL à curl un à la fois:
xargs -n 1 boucle -O < URLs-à-télécharger.txt
Notez que cette commande utilise le -O (fichier distant) commande output, qui utilise un “O” lettre capitale. Cette option provoque curl pour enregistrer le fichier récupéré avec le même nom que le fichier sur le serveur distant.
Les -n 1 option dit xargs traiter chaque ligne du fichier texte comme un seul paramètre.
Lorsque vous exécutez la commande, vous verrez plusieurs téléchargements commencer et se terminer, l'un après l'autre.
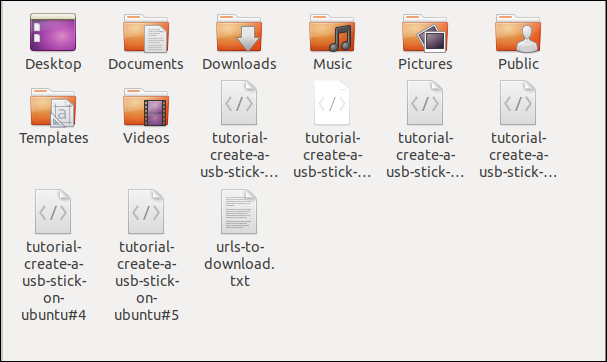
L'enregistrement dans l'explorateur de fichiers montre que plusieurs fichiers ont été téléchargés. Chacun porte le nom qu'il avait sur le serveur distant.
EN RELATION: Comment utiliser la commande xargs sous Linux
Téléchargement de fichiers depuis un serveur FTP
À l'aide de curl avec un Protocole de transfer de fichier (FTP) c'est facile, même si vous devez vous authentifier avec un nom d'utilisateur et un mot de passe. Pour transmettre un nom d'utilisateur et un mot de passe avec curl Utilisez le -u (Nom d'utilisateur) et écris le nom d'utilisateur, deux points ":" et le mot de passe. Ne pas mettre d'espace avant ou après le côlon.
Il s'agit d'un serveur FTP gratuit hébergé par Rebex. Le site FTP de test a un nom d’utilisateur prédéfini de “manifestation” et le mot de passe est “le mot de passe”. N’utilisez pas ce type de nom d’utilisateur et de mot de passe faibles sur un serveur FTP de production ou “réel”.
démo curl -u:mot de passe ftp://test.rebex.net

curl il se rend compte que nous le pointons vers un serveur FTP et renvoie une liste des fichiers présents sur le serveur.

le seul fichier sur ce serveur est un fichier “Lisez-moi.txt”, de 403 octets de long. Récupérons-le. Utilisez la même commande que tout à l'heure, avec le nom du fichier en pièce jointe:
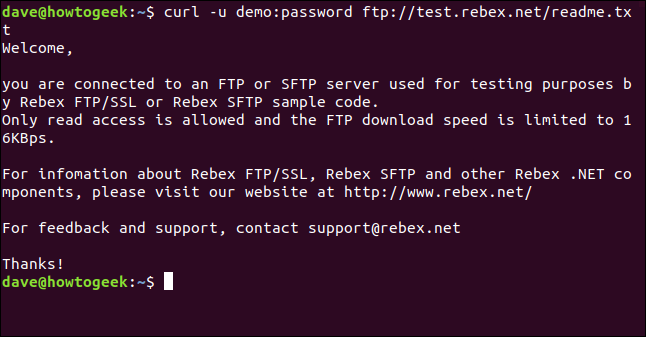
démo curl -u:mot de passe ftp://test.rebex.net/readme.txt

Le fichier est récupéré et curl affiche son contenu dans la fenêtre du terminal.
Dans presque tous les cas, il sera plus pratique d'enregistrer le fichier récupéré sur le disque, au lieu de l'afficher dans la fenêtre du terminal. Encore une fois, nous pouvons utiliser le -O (fichier distant) commande exit pour enregistrer le fichier sur le disque, avec le même nom de fichier que vous avez sur le serveur distant.
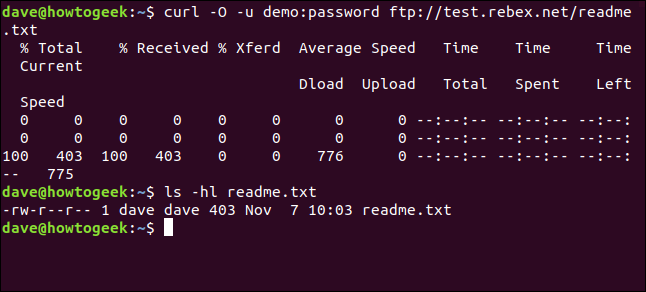
démo curl -O -u:mot de passe ftp://test.rebex.net/readme.txt

Le fichier est récupéré et enregistré sur le disque. On peut utiliser ls pour vérifier les détails du fichier. A le même nom que le fichier sur le serveur FTP et a la même longueur, 403 octets.
ls -hl readme.txt
EN RELATION: Comment utiliser la commande FTP sous Linux
Envoi de paramètres aux serveurs distants
Certains serveurs distants accepteront des paramètres dans les requêtes qui leur seront envoyées. Les paramètres peuvent être utilisés pour formater les données renvoyées, par exemple, ou ils peuvent être utilisés pour choisir les données exactes que l'utilisateur souhaite récupérer. Il est souvent possible d'interagir avec le web. interfaces de programmation d'applications (API) à l'aide de curl.
A titre d'exemple simple, les ipifier Le portail web dispose d'une API consultable pour établir votre adresse IP externe.
boucle https://api.ipify.org
Ajout du format paramètre à commander, avec la valeur de “json” nous pouvons réorganiser notre adresse IP externe, mais cette fois les données renvoyées seront encodées dans le Format JSON.
boucle https://api.ipify.org?format=json

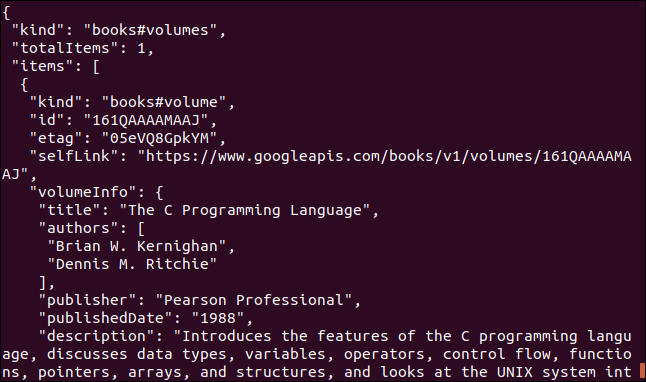
Voici un autre exemple qui utilise une API Google. Renvoie un objet JSON qui décrit un livre. Le paramètre que vous devez fournir est le Numéro international normalisé du livre (ISBN) numéro d'un livre. Vous pouvez les trouver sur la couverture arrière de la plupart des livres, généralement sous un code barre. Le paramètre que nous allons utiliser ici est “0131103628”.
boucle https://www.googleapis.com/books/v1/volumes?q=isbn:0131103628

Les données renvoyées sont complètes:
Parfois boucler, un veces wget
Si vous souhaitez télécharger du contenu à partir d'un portail Web et que l'arborescence du portail Web recherche récursivement ce contenu, voudrais utiliser wget.
Si vous vouliez interagir avec un serveur distant ou une API, et éventuellement télécharger des fichiers ou des pages web, voudrais utiliser curl. Surtout si le protocole était l'un des nombreux non pris en charge par wget.
setTimeout(fonction(){
!fonction(F,b,e,v,m,t,s)
{si(f.fbq)revenir;n=f.fbq=fonction(){n.callMethod?
n.callMethod.apply(m,arguments):n.queue.push(arguments)};
si(!f._fbq)f._fbq=n;n.push=n;n.chargé=!0;n.version=’2.0′;
n.queue=[];t=b.createElement(e);t.async=!0;
t.src=v;s=b.getElementsByTagName(e)[0];
s.parentNode.insertAvant(t,s) } (window, document,'scénario',
'https://connect.facebook.net/en_US/fbevents.js’);
fbq('init', « 335401813750447 »);
fbq('Piste', « Page View »);
},3000);





