
En Linux, awk est une dynamo de manipulation de texte en ligne de commande, ainsi qu'un puissant langage de script. Voici une introduction à certaines de ses fonctionnalités les plus intéressantes.
EN RELATION: 10 commandes Linux de base pour les débutants
Comment awk a obtenu son nom
Les awk La commande a été nommée en utilisant les initiales des trois personnes qui ont écrit la version originale en 1977: Alfred Aho, Peter Weinberger, et Brian Kernighan. Ces trois hommes appartenaient au légendaire À&T Laboratoires Bell Panthéon Unix. Avec les contributions de beaucoup d'autres depuis lors, awk a continué d'évoluer.
C'est un langage de script complet, ainsi qu'une boîte à outils de manipulation de texte intégral pour la ligne de commande. Si ce post vous met en appétit, il peut regarde chaque détail sur awk et sa fonctionnalité.
Règles, modèles et actions
awk fonctionne dans des programmes qui contiennent des règles composées de modèles et d'actions. L'action s'exécute sur le texte qui correspond au modèle. Les motifs sont entourés d'accolades ({}). Ensemble, un modèle et une action forment une règle. La totalité awk Le programme est entre guillemets simples (').
Jetons un coup d'œil au type le plus simple de awk Programme. N'a pas de modèle, il correspond donc à toutes les lignes de texte saisies. Cela signifie que l'action s'exécute sur chaque ligne. Bien l'utiliser sur la sortie de Les who commander.
Voici la sortie standard de who:
qui
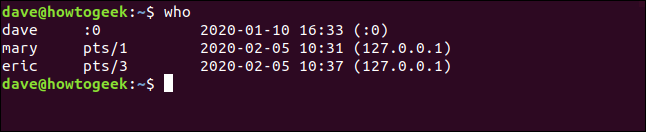
Nous n'avons peut-être pas besoin de toutes ces informations, mais plutôt, nous voulons seulement voir les noms dans les comptes. Nous pouvons canaliser la sortie de who Dans awket plus tard dire awk pour n'imprimer que le premier champ.
Par défaut, awk considère un champ comme une chaîne de caractères entourée d'espaces, le début d'une ligne ou la fin d'une ligne. Les champs sont identifiés par un signe dollar ($) et un nombre. Ensuite, $1 représente le premier champ, qu'allons-nous utiliser avec print action pour imprimer le premier champ.
Nous écrivons ce qui suit:
qui | ah '{imprimer $1}'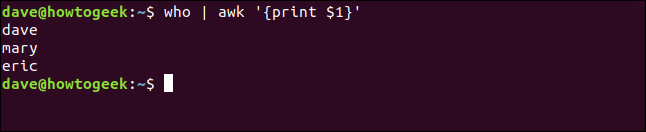
awk imprimer le premier champ et ignorer le reste de la ligne.
Nous pouvons imprimer autant de champs que nous voulons. Si nous ajoutons une virgule comme séparateur, awk imprimer un espace entre chaque champ.
Nous écrivons ce qui suit pour imprimer également l'heure à laquelle la personne s'est connectée (champ quatre):
qui | ah '{imprimer $1,$4}'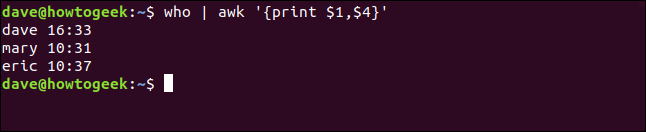
Il y a quelques identifiants de champs spéciaux. Ceux-ci représentent toute la ligne de texte et le dernier champ de la ligne de texte:
- $ 0: Représente toute la ligne de texte.
- $ 1: Représente le premier champ.
- $ 2: Représente le deuxième champ.
- $ 7: Représente le septième champ.
- $ 45: Représente le terrain 45.
- $ NF: Ça veut dire “nombre de champs” et représente le dernier champ.
Nous allons écrire ce qui suit pour faire apparaître un petit fichier texte contenant une courte citation attribuée à Dennis Ritchie:
chat dennis_ritchie.txt

Nous voulons awk pour imprimer le premier, deuxième et dernier champ du devis. Notez que, même lorsqu'il est enveloppé dans une fenêtre de terminal, c'est juste une ligne de texte.
On écrit la commande suivante:
ah '{imprimer $1,$2,$NF}' dennis_ritchie.txt
Nous ne le savons pas “simplicité”. est le champ numérique 18 dans la ligne de texte, et on s'en fout. Ce que nous savons, c'est que c'est le dernier champ et que nous pouvons utiliser $NF obtenir sa valeur. La période est considérée comme juste un autre caractère dans le corps du champ.
Ajouter des séparateurs de champs de sortie
Vous pouvez aussi dire awk pour imprimer un caractère particulier entre les champs au lieu du caractère espace par défaut. La sortie par défaut du date la commande est un peu particulière parce que le temps est juste au milieu. Malgré cela, nous pouvons écrire ce qui suit et utiliser awk pour extraire les champs que nous voulons:
Date
Date | ah '{imprimer $2,$3,$6}'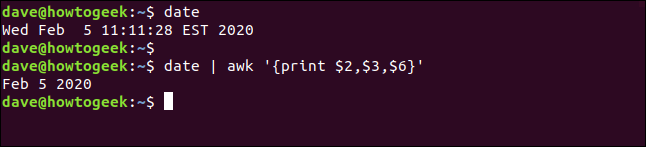
Nous utiliserons le OFS (séparateur de champ de sortie) variable pour placer un séparateur entre le mois, le jour et l'année. Notez que nous mettons la commande entre guillemets simples ci-dessous ('), pas de clés ({}):
Date | awk 'OFS="https://www.systempeaker.com/" {imprimer$2,$3,$6}'Date | awk 'OFS="-" {imprimer$2,$3,$6}'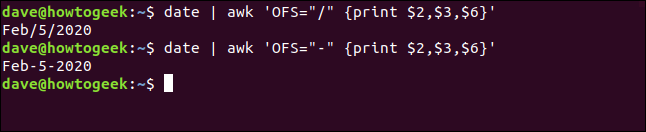
Les règles BEGIN et END
UNE BEGIN La règle s'exécute une fois avant le début du traitement de texte. En réalité, court avant awk même lire n'importe quel texte. Un END La règle s'exécute une fois tous les traitements terminés. Vous pouvez avoir plusieurs BEGIN et END Règles, et ils fonctionneront dans l'ordre.
Pour notre exemple de BEGIN régner, nous imprimerons le devis complet du dennis_ritchie.txt fichier que nous avons utilisé précédemment avec un titre en haut.
Pour le faire, nous écrivons cette commande:
awk' COMMENCER {imprimer "Dennis Ritchie"} {imprimer $0}' dennis_ritchie.txt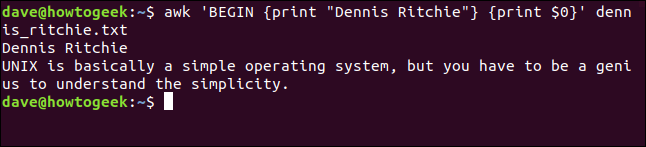
Noter la BEGIN La règle a son propre ensemble d'actions enfermées dans son propre ensemble d'accolades ({}).
Nous pouvons utiliser cette même technique avec la commande que nous avons utilisée précédemment pour diriger la sortie de who Dans awk. Pour le faire, nous écrivons ce qui suit:
qui | awk' COMMENCER {imprimer "sessions actives"} {imprimer $1,$4}'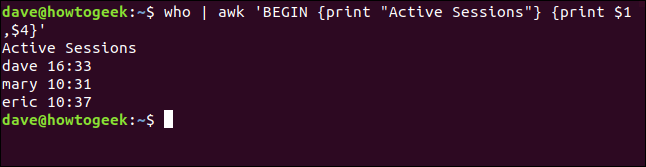
Séparateurs de champs de saisie
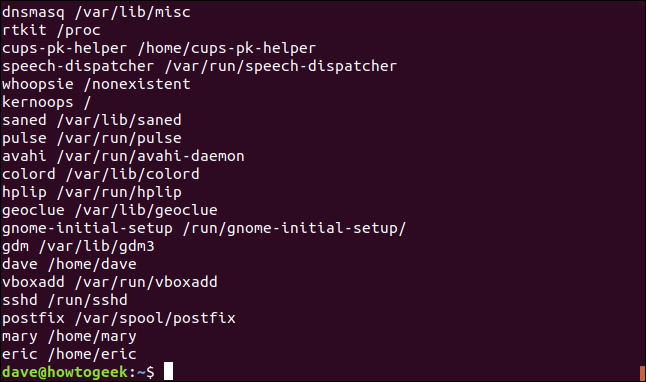
Si tu fais semblant awk pour travailler avec du texte qui n'utilise pas d'espace pour séparer les champs, devrait vous dire quel caractère le texte utilise comme séparateur de champ. Par exemple, les /etc/passwd le fichier utilise un deux-points (:) séparer les champs.
Nous utiliserons ce fichier et le -F (chaîne de séparation) possibilité de dire awk utiliser le côlon:) comme séparateur. Nous écrivons ce qui suit pour compter awk pour imprimer le nom du compte utilisateur et le dossier de départ:
awk -F: '{imprimer $1,$6}' /etc/passwd
La sortie contient le nom du compte utilisateur (ou le nom de l'application ou du démon) et le dossier home (ou l'emplacement de l'application).
Ajout de motifs
Si la seule chose qui nous intéresse, ce sont les comptes utilisateurs habituels, nous pouvons inclure un motif avec notre action d'impression pour filtrer toutes les autres entrées. Dû au fait que Identifiant d'utilisateur Si les nombres sont égaux ou supérieurs à 1.000, nous pouvons baser notre filtre sur cette information.
Nous écrivons ce qui suit pour exécuter notre action d'impression uniquement lorsque le troisième champ ($3) contient une valeur de 1000 ou plus:
awk -F: '$3 >= 1000 {imprimer $1,$6}' /etc/passwd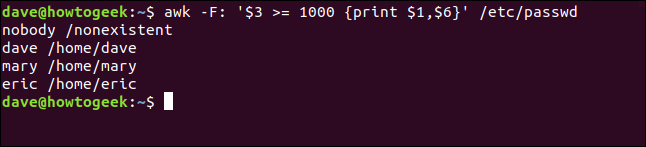
Le motif doit précéder immédiatement l'action à laquelle il est lié.
Nous pouvons utiliser le BEGIN règle pour donner un titre à notre petit rapport. Nous écrivons ce qui suit, en utilisant le (n) notation pour insérer un caractère de nouvelle ligne dans la chaîne de titre:
awk -F: 'COMMENCER {imprimer "Comptes d'utilisateursn -------------"} $3 >= 1000 {imprimer $1,$6}' /etc/passwd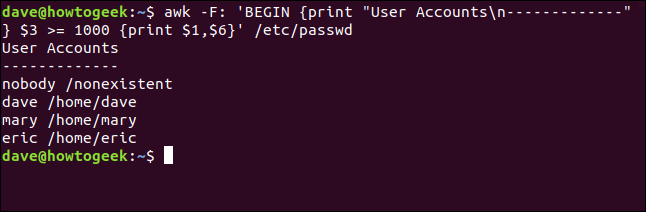
Les patrons sont terminés expressions régulières, et ils sont l'une des gloires de awk.
Disons que nous voulons voir les identifiants uniques universels (UUID) des systèmes de fichiers montés. Si nous cherchons dans le /etc/fstab fichier pour les occurrences de chaîne “UUID”, vous devez nous retourner ces informations.
Nous utilisons le motif de recherche "/UUID/" dans notre commande:
awk '/UUID/ {imprimer $0}' /etc/fstab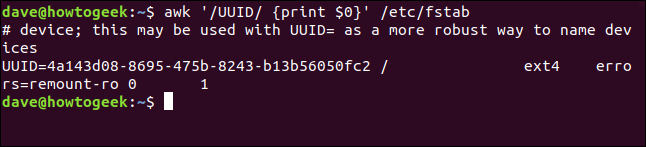
Trouvez toutes les occurrences de "UUID" et imprimez ces lignes. En réalité, nous aurions obtenu le même résultat sans le print action car l'action par défaut imprime toute la ligne de texte. Malgré cela, pour plus de clarté, il est souvent utile d'être explicite. Lors de la révision d'un script ou de son archive, tu seras content que nous ayons laissé des indices pour toi.
La première ligne trouvée était une ligne de commentaire et, même lorsque la chaîne “UUID” est au milieu, awk je l'ai encore trouvé. Nous pouvons modifier la regex et dire awk pour traiter uniquement les lignes commençant par “UUID”. Pour le faire, nous écrivons ce qui suit qui inclut le jeton de début de ligne (^):
awk '/^UUID/ {imprimer $0}' /etc/fstab
Ça c'est mieux! Maintenant, nous ne voyons que des instructions de montage authentiques. Pour affiner davantage la sortie, nous écrivons ce qui suit et restreignons l'affichage au premier champ:
awk '/^UUID/ {imprimer $1}' /etc/fstab
Si nous avions plusieurs systèmes de fichiers montés sur cette machine, nous obtiendrions une table ordonnée de ses UUID.
Fonctions intégrées
awk ont de nombreuses fonctions que vous pouvez appeler et utiliser dans vos propres programmes, à la fois depuis la ligne de commande et dans les scripts. Si tu fais une petite recherche, vous le trouverez très fructueux.
Démontrer la technique générale d'appel d'une fonction, nous verrons des chiffres. Par exemple, ce qui suit imprime la racine carrée de 625:
awk' COMMENCER { imprimer sqrt(625)}'Cette commande imprime l'arc tangente de 0 (zéro) et -1 (qui s'avère être la constante mathématique, pi):
awk' COMMENCER {imprimer atan2(0, -1)}'Dans la commande suivante, nous modifions le résultat de la atan2() fonction avant impression:
awk' COMMENCER {imprimer atan2(0, -1)*100}'Les fonctions peuvent accepter des expressions comme paramètres. Par exemple, voici une façon compliquée de demander la racine carrée de 25:
awk' COMMENCER { imprimer sqrt((2+3)*5)}'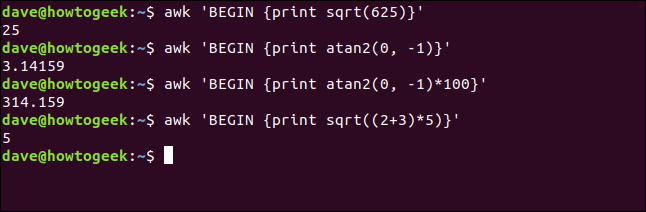
scripts awk
Si votre ligne de commande se complique ou si vous développez une routine que vous savez que vous voudrez réutiliser, vous pouvez transférer votre awk commande dans un script.
Dans notre exemple de script, nous ferons tout ce qui suit:
- Dites au shell quel exécutable utiliser pour exécuter le script.
- Mettre en place
awkUtilisez leFSvariable de séparation de champs pour lire le texte d'entrée avec des champs séparés par des deux-points (:). - Utilisez le
OFSséparateur de champ de sortie à compterawkutiliser un côlon:) pour séparer les champs dans la sortie. - Placer un compteur à 0 (zéro).
- Définissez le deuxième champ de chaque ligne de texte sur une valeur vide (c’est toujours un “X”, il n'est donc pas nécessaire que nous le voyions).
- Imprimer la ligne avec le deuxième champ modifié.
- Augmenter le compteur.
- Imprimer la valeur du compteur.
Notre script est montré ci-dessous.

Les BEGIN la règle effectue les étapes préparatoires, Pendant ce temps, il END La règle indique la valeur du compteur. La règle du milieu (qui n'a pas de nom ou de modèle, il correspond donc à toutes les lignes) modifie le deuxième champ, imprime la ligne et incrémente le compteur.
La première ligne du script indique au shell quel exécutable utiliser (awk, dans notre exemple) pour exécuter le script. Il passe également le -f (nom de fichier) option pour awk, qui vous informe que le texte que vous allez traiter proviendra d’un fichier. Nous transmettrons le nom du fichier au script lorsque nous l’exécuterons.
Nous avons inclus le script suivant sous forme de texte afin que vous puissiez couper et coller:
#!/usr/bin/awk -f BEGIN { # set the input and output field separators FS=":" OFS=":" # zero the accounts counter accounts=0 } { # définir le champ 2 to nothing $2="" # print the entire line print $0 # count another account accounts++ } FINIR { # print the results print accounts " comptes.n" }
Enregistrez-le dans un fichier appelé omit.awk. Pour rendre le script exécutablemoi, nous écrivons ce qui suit en utilisant chmod:
chmod +x omit.awk

Maintenant, nous l’exécuterons et passerons le /etc/passwd fichier à script. Voici le fichier awk traitées par nous, utilisation des règles du script:
./omit.awk /etc/passwd

Le fichier est traité et chaque ligne est affichée, comme il est montré dans ce qui suit.
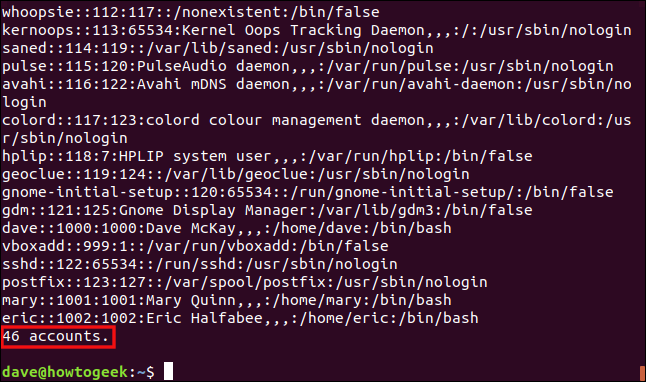
Entrées supprimées “X” dans le deuxième champ, mais notez que les séparateurs de champs sont toujours présents. Les lignes sont comptées et le total est donné en bas de la sortie.
maladroit ne veut pas dire maladroit
awk ne veut pas dire inconfortable; est synonyme d'élégance. Il a été décrit comme un filtre de traitement et un rédacteur de rapport. Plus précisément, sont-ils tous les deux ou, plutôt, un outil que vous pouvez utiliser pour les deux tâches. En quelques lignes, awk réalise ce dont un codage étendu dans une langue traditionnelle a besoin.
Ce pouvoir est exploité par le concept simple de règles contenant des modèles., qui sélectionnent le texte à traiter et les actions qui définissent le traitement.





