
Sous Linux uniq la commande parcourt vos fichiers texte pour les lignes simples ou en double. Dans ce guide, nous couvrons sa polyvalence et ses fonctionnalités, ainsi que comment tirer le meilleur parti de cet utilitaire astucieux.
Trouver des lignes de texte correspondantes sous Linux
Les uniq la commande est Rapide, flexible et excellent dans ce qu'il fait. Cependant, comme beaucoup de commandes Linux, a quelques particularités, ce qui est juste, tant que tu les connais. Si vous franchissez le pas sans une petite connaissance de l'intérieur, vous risquez de vous gratter la tête devant les résultats. Nous signalerons ces bizarreries au fur et à mesure.
Les uniq La commande est parfaite pour ceux dans le domaine à usage unique, conçu pour faire une chose et le faire bien. C'est pourquoi il est également particulièrement adapté pour travailler avec des tuyaux et jouer son rôle dans les tuyaux de commande. L'un de ses collaborateurs les plus fréquents il est sort parce que uniq doit avoir une entrée soignée pour travailler.
Allumons-le!
EN RELATION: Comment utiliser Pipes sur Linux
Exécution d'uniq sans options
Nous avons un fichier texte qui contient les paroles de De Robert Johnson chanson Je pense que je vais épousseter mon balai. Voyons quoi uniq la fait.
Nous écrirons ce qui suit pour diriger la sortie vers less:
uniq poussière-mon-balai.txt | moins

Nous obtenons la chanson complète, y compris les lignes en double, au less:
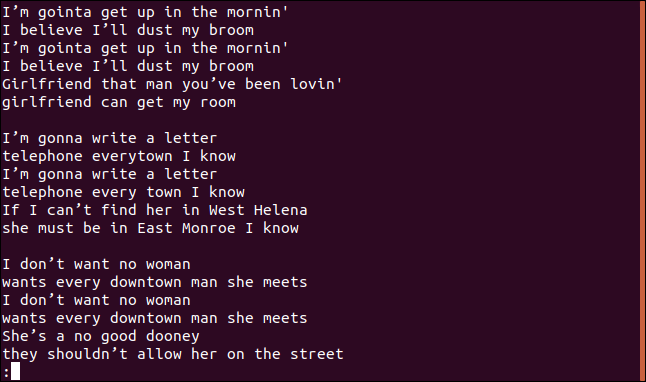
Cela ne semble être ni les lignes uniques ni les lignes en double.
C'est Correct, car c'est la première particularité. Si tu cours uniq aucune option, se comporte comme s'il avait utilisé le -u option (lignes uniques). Cela dit uniq pour n'imprimer que les seules lignes du fichier. La raison pour laquelle vous voyez des lignes en double est que, pour uniq considérer une ligne comme un doublon, doit être adjacent à son duplicata, qu'est-ce que c'est où sort entre.
Lorsque nous commandons le fichier, regrouper les lignes en double et uniq les traite comme des doublons. nous utiliserons sort dans le fichier, l'entonnoir a ordonné la sortie vers uniqpuis rediriger la sortie finale vers less.
Pour le faire, nous écrivons ce qui suit:
trier dust-my-broom.txt | unique | moins

Une liste ordonnée de lignes apparaît dans less.
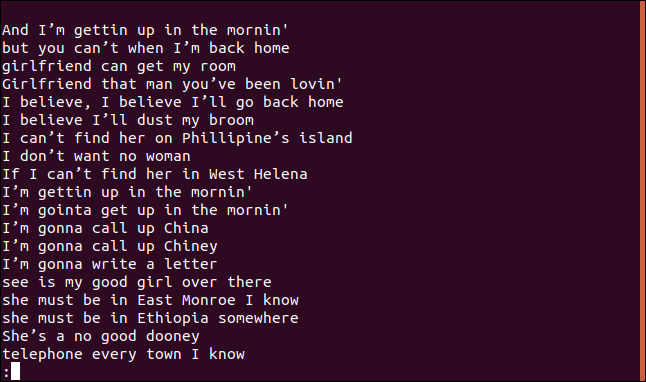
La ligne, “Je pense que je vais le dépoussiérer de mon balai”, apparaît définitivement dans la chanson plus d'une fois. En réalité, se répète deux fois dans les quatre premières lignes de la chanson.
Ensuite, Pourquoi apparaît-il dans une liste de lignes uniques? Parce que la première fois qu'une ligne apparaît dans le fichier, est unique; seules les entrées suivantes sont des doublons. Vous pouvez le considérer comme une liste de la première occurrence de chaque ligne unique.
Utilisons sort à nouveau et rediriger la sortie vers un nouveau fichier. De cette manière, nous n'avons pas à utiliser sort dans chaque commande.
On écrit la commande suivante:
trier dust-my-broom.txt > trié.txt

Maintenant, nous avons un dossier pré-classé avec lequel travailler.
Compter les doublons
Vous pouvez utiliser le -c (compter) pour imprimer le nombre de fois où chaque ligne apparaît dans un fichier.
Tapez la commande suivante:
uniq -c trié.txt | moins

Chaque ligne commence par le nombre de fois où cette ligne apparaît dans le fichier. Cependant, vous remarquerez que la première ligne est vide. Cela vous indique qu'il y a cinq lignes vides dans le fichier.
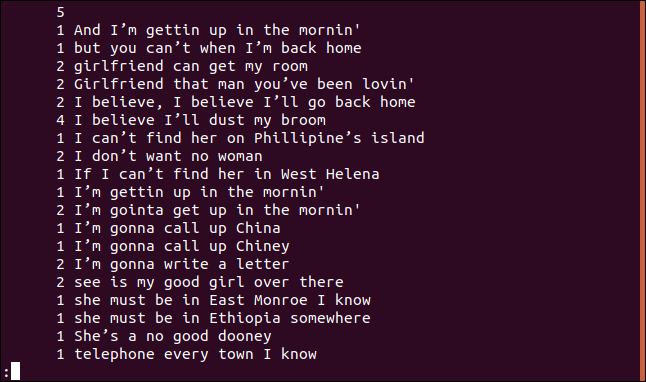
Si vous souhaitez que la sortie soit triée par ordre numérique, peut alimenter la sortie de uniq Dans sort. Dans notre exemple, nous utiliserons le -r (revers) et -n (ordre numérique) et canaliser les résultats vers less.
Nous écrivons ce qui suit:
uniq -c trié.txt | trier -rn | moins

La liste est classée par ordre décroissant selon la fréquence d'apparition de chaque ligne.
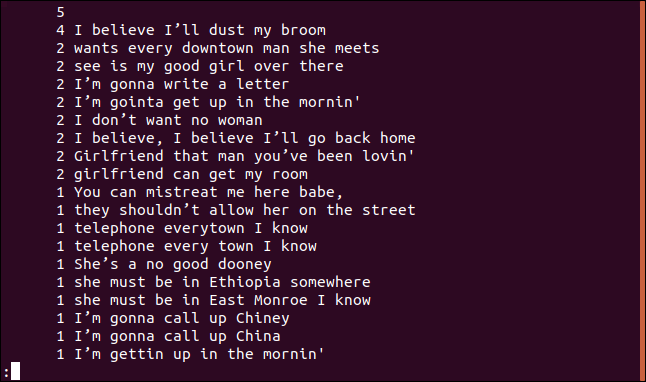
Lister uniquement les lignes en double
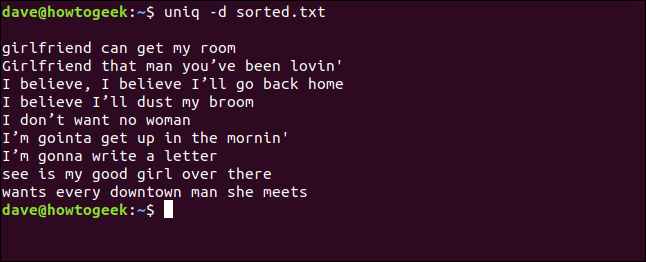
Si vous voulez voir uniquement les lignes qui se répètent dans un fichier, vous pouvez utiliser le -d option (répété). Peu importe combien de fois une ligne est dupliquée dans un fichier, n'apparaît qu'une seule fois.
Pour utiliser cette option, nous écrivons ce qui suit:
uniq -d trié.txt

Les lignes en double sont répertoriées pour nous. Vous remarquerez la ligne vide en haut, ce qui signifie que le fichier contient des lignes vides en double; ce n'est pas un espace laissé par uniq pour compenser cosmétiquement la liste.
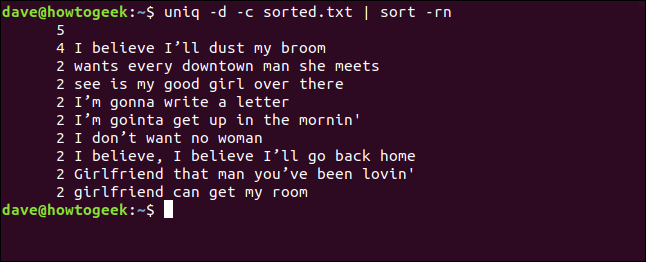
Nous pouvons également combiner les -d (répété) et -c (raconter) options et rediriger la sortie à travers sort. Cela nous donne une liste ordonnée de lignes qui apparaissent au moins deux fois.
Tapez ce qui suit pour utiliser cette option:
uniq -d -c trié.txt | trier -rn
Liste de toutes les lignes en double
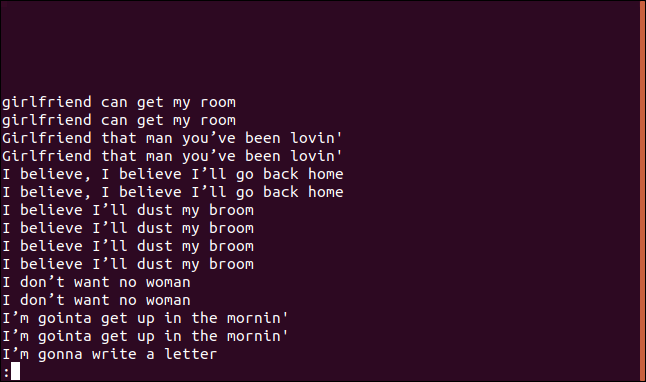
Si vous voulez voir une liste de chaque ligne en double, ainsi qu'une entrée pour chaque apparition d'une ligne dans le fichier, vous pouvez utiliser le -D (toutes les lignes en double) option.
Pour utiliser cette option, écris ce qui suit:
uniq -D trié.txt | moins

La liste contient une entrée pour chaque ligne en double.
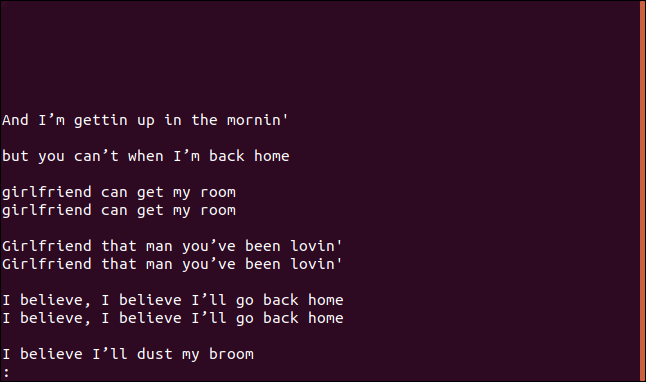
Si vous utilisez le --group option, imprime chaque ligne en double avec une ligne vide avant (prepend) ou après chaque groupe (append), ou les deux avant et après (both) chaque groupe.
Nous utilisons append comme notre modificateur, donc on écrit ce qui suit:
uniq --group=append trié.txt | moins

Les groupes sont séparés par des lignes vierges pour une lecture facile.
Vérification d'un certain nombre de caractères
Par défaut, uniq vérifier toute la longueur de chaque ligne. Cependant, si vous souhaitez restreindre les contrôles à un certain nombre de caractères, vous pouvez utiliser le -w (vérifier les caractères) option.
Dans cet exemple, nous allons répéter la dernière commande, mais nous limiterons les comparaisons aux trois premiers caractères. Pour le faire, on écrit la commande suivante:
uniq -w 3 --groupe=ajouter trié.txt | moins

Les résultats et les regroupements que nous recevons sont assez différents.
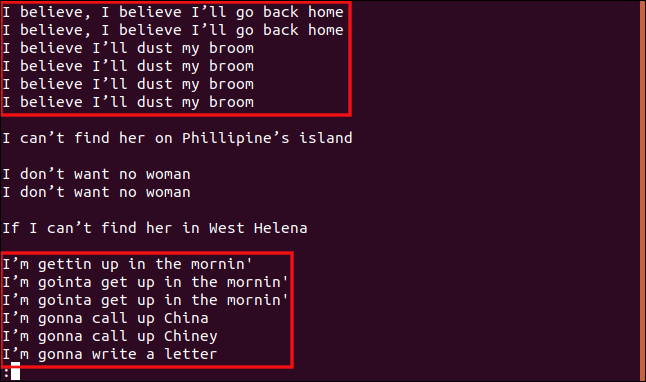
Toutes les lignes commençant par “I b” sont regroupées parce que ces parties des lignes sont identiques, ils sont donc considérés comme des doublons.
De la même manière, toutes les lignes qui commencent par “Je suis” sont traités comme des doublons, même si le reste du texte est différent.
Ignorer un certain nombre de caractères
Dans certains cas, il peut être avantageux d'omettre un certain nombre de caractères au début de chaque ligne, comme quand les lignes d'un fichier sont numérotées. Ou dis ce dont tu as besoin uniq pour sauter un horodatage et commencer à vérifier les lignes pour le caractère six au lieu du premier caractère.
Ci-dessous une version de notre fichier trié avec des lignes numérotées.

Si nous voulons uniq pour commencer vos contrôles de comparaison sur le personnage trois, nous pouvons utiliser le -s (sauter des caractères) écrivant ce qui suit:
uniq -s 3 -d -c numéroté.txt

Les lignes sont détectées comme des doublons et sont comptées correctement. Notez que les numéros de ligne affichés sont ceux de la première occurrence de chaque doublon.
Vous pouvez également omettre des champs (une chaîne de caractères et quelques espaces) au lieu de caractères. Nous utiliserons le -f (des champs) possibilité de compter uniq quels champs ignorer.
Nous écrivons ce qui suit pour compter uniq ignorer le premier champ:
uniq -f 1 -d -c numérotés.txt
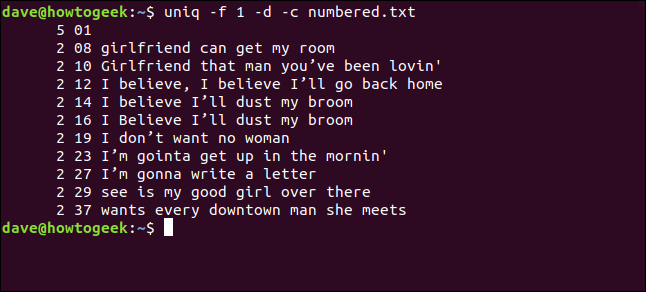
Nous obtenons les mêmes résultats que lorsque nous avons dit uniq omettre trois caractères au début de chaque ligne.
Ignorer l'affaire
Par défaut, uniq est sensible à la casse. Si la même lettre apparaît en majuscule et en minuscule, uniq considérer que les lignes sont différentes.
Par exemple, voir la sortie de la commande suivante:
uniq -d -c trié.txt | trier -rn

Les lignes “Je pense que je vais le dépoussiérer de mon balai” et “Je pense que je vais le dépoussiérer de mon balai” ne sont pas traités comme des doublons en raison de la différence de cas dans le “B” au “croire”.
Si nous incluons le -i (ignorer les majuscules et les minuscules), cependant, ces lignes seront traitées comme des doublons. Nous écrivons ce qui suit:
uniq -d -c -i trié.txt | trier -rn
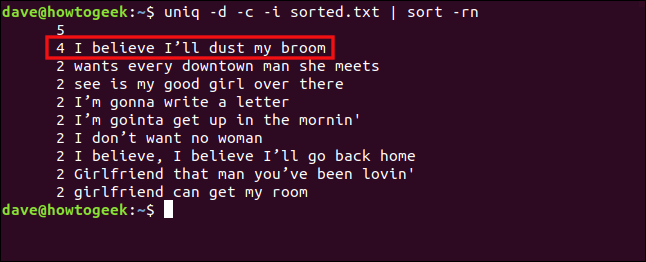
Les lignes sont désormais traitées comme des doublons et regroupées.
Linux vous offre une multitude d'utilitaires spéciaux. Comme beaucoup d'entre eux, uniq ce n'est pas un outil que vous utiliserez tous les jours.
C'est pourquoi une grande partie de devenir un expert Linux consiste à se rappeler quel outil résoudra votre problème actuel et où vous pouvez le retrouver.. Cependant, si vous pratiquez, tu seras bien parti.
Ou bien, vous pouvez toujours rechercher How-To Geek; nous avons probablement un article à ce sujet.
setTimeout(fonction(){
!fonction(F,b,e,v,m,t,s)
{si(f.fbq)revenir;n=f.fbq=fonction(){n.callMethod?
n.callMethod.apply(m,arguments):n.queue.push(arguments)};
si(!f._fbq)f._fbq=n;n.push=n;n.chargé=!0;n.version=’2.0′;
n.queue=[];t=b.createElement(e);t.async=!0;
t.src=v;s=b.getElementsByTagName(e)[0];
s.parentNode.insertAvant(t,s) } (window, document,'scénario',
'https://connect.facebook.net/en_US/fbevents.js’);
fbq('init', « 335401813750447 »);
fbq('Piste', « Page View »);
},3000);





