
Utilisez des pipelines Linux pour chorégraphier la façon dont les utilitaires de ligne de commande collaborent. Simplifiez les processus complexes et augmentez votre productivité en tirant parti d'un ensemble de commandes indépendantes et en les transformant en une équipe à objectif unique. Nous vous montrons comment.
Les tuyaux sont partout
Les pipelines sont l'une des fonctionnalités de ligne de commande les plus utiles des systèmes d'exploitation Linux et Unix. Les tuyaux sont utilisés d'innombrables façons. Regardez n'importe quel article de ligne de commande Linux, sur n'importe quel site, pas seulement chez nous, et vous verrez les tuyaux apparaître la plupart du temps. J'ai parcouru certains des articles Linux de How-To Geek, et dans chacun d'eux des tuyaux sont utilisés, d'une façon ou d'une autre.
Les tuyaux Linux vous permettent d'effectuer des actions qui ne sont pas prises en charge par Linux coquille. Mais parce que la philosophie de conception de Linux est d'avoir beaucoup de petits utilitaires qui fonction dédiée très bienet sans fonctionnalité inutile, le mantra "faire une chose et la faire bien", vous pouvez connecter des chaînes de commande avec des tuyaux afin que la sortie d'une commande devienne l'entrée d'une autre. Chaque commande qui entre apporte son talent unique à l'équipe, et vous découvrirez bientôt que vous avez constitué une équipe gagnante.
Un exemple simple
Supposons que nous ayons un répertoire rempli de nombreux types de fichiers différents. Nous voulons savoir combien de fichiers d'un certain type se trouvent dans ce répertoire. Il y a d'autres façons de faire cela, mais le but de cet exercice est d'introduire des tuyaux, donc on va le faire avec des tuyaux.
Nous pouvons obtenir une liste des fichiers facilement en utilisant ls:
ls
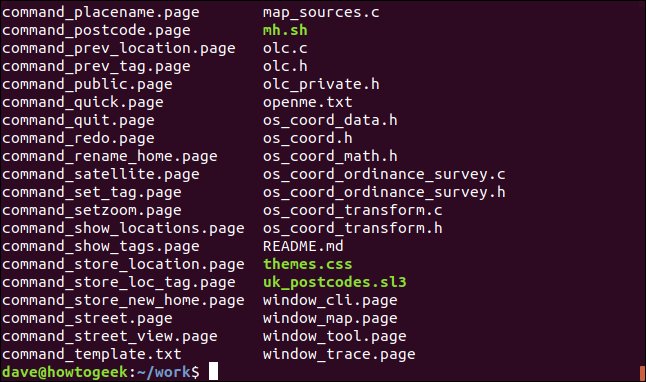
Pour séparer le type de fichier d'intérêt, nous utiliserons grep. Nous voulons trouver des fichiers contenant le mot “page” Nous voulons trouver des fichiers contenant le mot.
Nous voulons trouver des fichiers contenant le mot “|“Nous voulons trouver des fichiers contenant le mot ls Dans grep.
ls | grep "page"

grep imprimer des lignes qui correspond à votre modèle de recherche. Ensuite, Nous voulons trouver des fichiers contenant le mot “.page”.
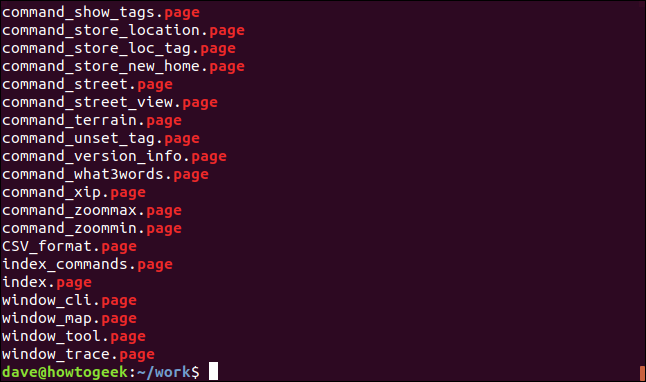
Même cet exemple trivial montre la fonctionnalité des tuyaux. La sortie de ls il n'a pas été envoyé à la fenêtre du terminal. A été envoyé aux grep comme données pour le grep commande de travailler. La sortie que nous voyons vient de grep, qui est la dernière commande de cette chaîne.
Élargir notre chaîne
Commençons à étendre notre chaîne de commande en pipeline. Pouvons Nous voulons trouver des fichiers contenant le mot “.page” en ajoutant le wc commander. Nous utiliserons le -l (nombre de lignes) option avec wc. Notez que nous avons également ajouté le -l (format long) option pour ls . Nous l'utiliserons sous peu.
ls - | grep "page" | wc -l

grep ce n'est plus la dernière commande de la chaîne, donc on ne voit pas sa sortie. La sortie de grep se nourrit de wc commander. La sortie que nous voyons dans la fenêtre du terminal est wc. wc informe qu'il y a 69 fichiers ".page" dans le répertoire.
Répandons les choses à nouveau. Nous prendrons le wc commande en dehors de la ligne de commande et remplacez-la par awk. Il y a neuf colonnes dans la sortie de ls avec lui -l option (format long). nous utiliserons awk afin de colonnes d'impression cinq, trois et neuf. Ce sont la taille, le propriétaire et le nom du fichier.
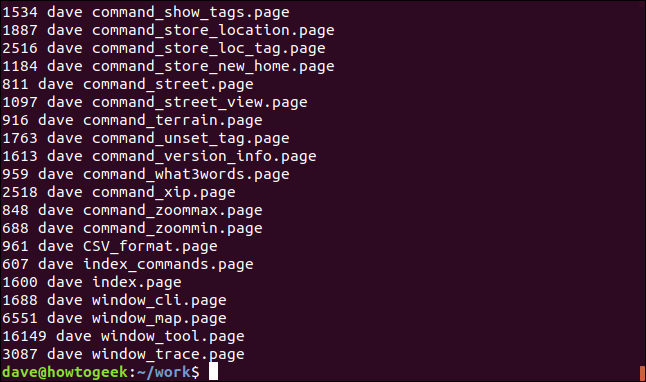
ls -l | grep "page" | ah '{imprimer $5 " " $3 " " $9}'

Nous obtenons une liste de ces colonnes, pour chacun des fichiers correspondants.
Nous allons maintenant passer cette sortie par le sort commander. Nous utiliserons le -n option (numérique) Quitter sort sachez que la première colonne doit être traités comme des nombres.
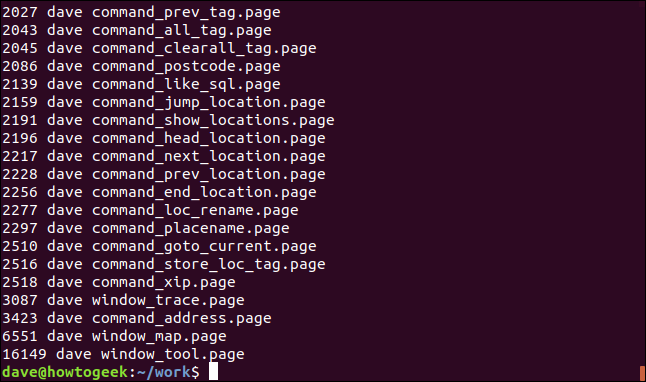
ls -l | grep "page" | ah '{imprimer $5 " " $3 " " $9}' | trier -n

La sortie est maintenant triée par taille de fichier, avec notre sélection personnalisée à trois colonnes.
Ajouter une autre commande
Nous terminerons en ajoutant le tail commander. Nous vous dirons de lister les cinq dernières lignes de départ seul.
ls -l | grep "page" | ah '{imprimer $5 " " $3 " " $9}' | trier -n | queue -5

Nous voulons trouver des fichiers contenant le mot “Nous voulons trouver des fichiers contenant le mot” .page “Nous voulons trouver des fichiers contenant le mot, Nous voulons trouver des fichiers contenant le mot”. Bien sûr, il n'y a pas de commande pour y parvenir, mais en utilisant des tuyaux, nous avons créé le nôtre. On pourrait ajouter ceci, ou toute autre commande longue, en tant qu'alias ou fonction shell pour enregistrer toutes les écritures.
Voici le résultat:
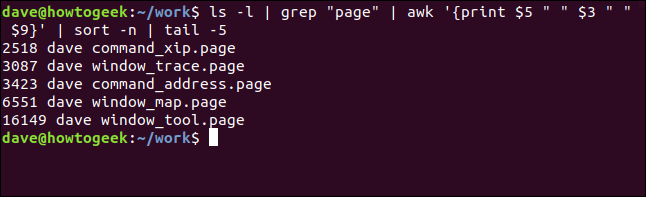
Nous pourrions inverser l'ordre des tailles en ajoutant le -r option (inverser) aile sort commander, et en utilisant head au lieu de tail choisir les lignes du haut de la sortie.

Cette fois, Nous voulons trouver des fichiers contenant le mot “.page” Nous voulons trouver des fichiers contenant le mot:
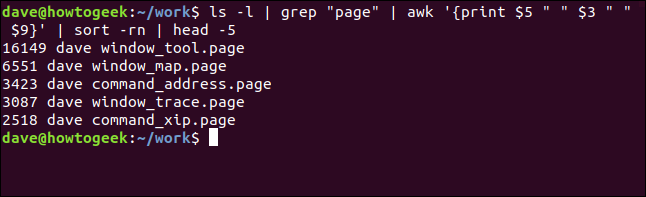
Quelques exemples récents
Voici deux exemples intéressants d'articles récents sur les geeks.
Quelques commandes, comme lui xargscommander, sont conçus avoir une entrée canalisée vers eux. Voici un moyen que nous pouvons avoir wc compte le mots, caractères et lignes dans plusieurs fichiers, canalisation ls Dans xargs qui alimente ensuite la liste des noms de fichiers à wc comme s'ils avaient été transmis à wc comme paramètres de ligne de commande.
ls *.page | xargs wc

Le nombre total de mots, les caractères et les lignes sont répertoriés en bas de la fenêtre du terminal.
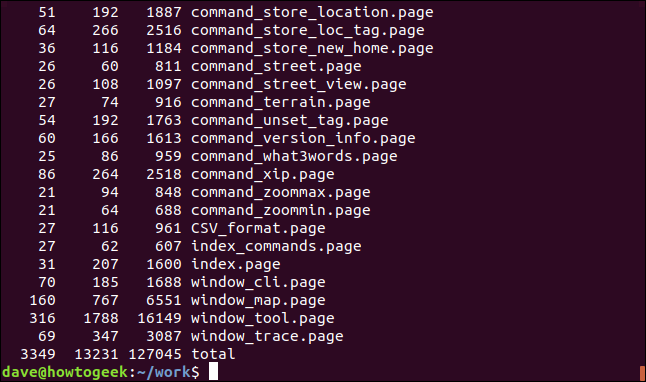
C'est un moyen d'obtenir une liste ordonnée des extensions de fichiers uniques dans le répertoire actuel, avec un compte de chaque type.
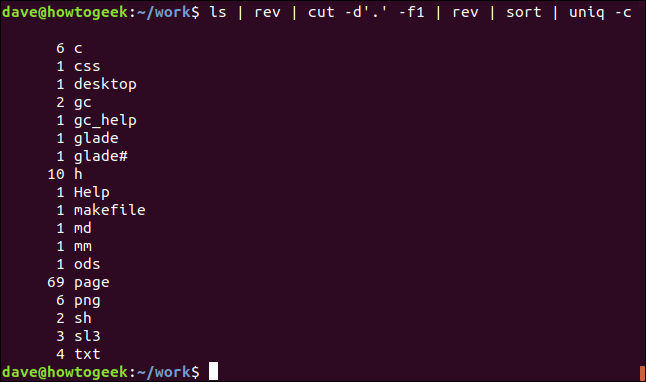
ls | tour | couper -d'.' -f1 | tour | sorte | uniq -c

Il se passe beaucoup de choses ici.
La sortie affiche la liste des extensions de fichiers, trié par ordre alphabétique avec un nombre de chaque type unique.
Tubes nommés
Il existe un autre type de tuyau à notre disposition, appelés tubes nommés. Les tuyaux des exemples précédents sont créés à la volée par le shell lors du traitement de la ligne de commande. Les tuyaux sont créés, utilisé puis jeté. Ils sont passagers et ne laissent aucune trace d'eux-mêmes. Ils n'existent que pendant l'exécution de la commande qui les utilise.
Les canaux nommés apparaissent comme des objets persistants sur le système de fichiers, afin que vous puissiez les voir en utilisant ls. Ils sont persistants car ils survivront à un redémarrage de l'ordinateur, bien que toutes les données non lues qu'ils contiennent à ce moment-là seront supprimées.
Les canaux nommés ont été beaucoup utilisés à la fois pour permettre à différents processus d'envoyer et de recevoir des données, mais je ne les ai pas vus utilisés de cette façon depuis longtemps. Sans doute, il y a des gens qui les utilisent encore à bon escient, mais je n'en ai pas trouvé récemment. Mais par souci d'intégrité, ou juste pour satisfaire votre curiosité, voici comment vous pouvez les utiliser.
Les canaux nommés sont créés avec le mkfifo commander. Cette commande va créer un tube nommé appelé “geek-pipe” Nous voulons trouver des fichiers contenant le mot.
mkfifo geek-pipe

Nous pouvons voir les détails du tuyau nommé si nous utilisons le ls commande avec le -l (format long) option:
ls -l geek-pipe

Nous voulons trouver des fichiers contenant le mot “p”, ce qui veut dire que c'est un tuyau. Nous voulons trouver des fichiers contenant le mot “ré”, cela signifierait que l'objet du système de fichiers est un répertoire, Nous voulons trouver des fichiers contenant le mot “-” Nous voulons trouver des fichiers contenant le mot.
Utiliser un tube nommé
Utilisons notre pipe. Les tubes sans nom que nous avons utilisés dans nos exemples précédents ont transmis les données immédiatement de la commande d'envoi à la commande de réception. Les données envoyées via un pipeline nommé resteront dans le pipeline jusqu'à ce qu'elles soient lues. Les données sont en fait stockées en mémoire, donc la taille du tuyau nommé ne variera pas en ls répertorié s'il contient des données ou non.
Nous utiliserons deux fenêtres de terminal pour cet exemple. je vais utiliser la balise:
# Terminal 1
dans une fenêtre de terminal et
# Terminal 2
dans l'autre, afin que vous puissiez les différencier. Nous voulons trouver des fichiers contenant le mot “#” Nous voulons trouver des fichiers contenant le mot.
Prenons l'intégralité de notre exemple précédent et redirigons-le vers le tube nommé. Nous utilisons donc des canaux nommés et non nommés dans une commande:
ls | tour | couper -d'.' -f1 | tour | sorte | uniq -c > geek-pipe

Il ne semble pas qu'il se passe grand-chose. Cependant, vous remarquerez peut-être qu'il ne revient pas à l'invite de commande, donc quelque chose se passe.
Dans l'autre fenêtre de terminal, lancer cette commande:
chat < geek-pipe

Nous redirigeons le contenu du tube nommé vers cat, pour que cat affichera ce contenu dans la deuxième fenêtre de terminal. Voici le résultat:
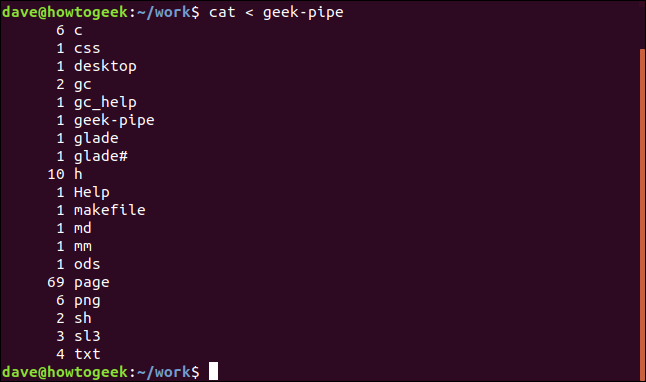
Et vous verrez que vous êtes revenu à l'invite de commande dans la première fenêtre de terminal.

Ensuite, que s'est-il passé?
- Nous redirigeons certains résultats vers le tube nommé.
- La première fenêtre de terminal n'est pas revenue à l'invite de commande.
- Les données sont restées dans le pipeline jusqu'à ce qu'elles soient lues à partir du pipeline au deuxième terminal.
- Nous revenons à l'invite de commande dans la première fenêtre de terminal.
Vous pensez peut-être que vous pourriez exécuter la commande dans la première fenêtre de terminal en tant que tâche d'arrière-plan en ajoutant un & jusqu'à la fin de la commande. Et tu aurais raison. Dans ce cas, nous serions revenus à l'invite de commande immédiatement.
Le point de non L'utilisation du traitement en arrière-plan visait à souligner qu'un canal nommé est un processus de verrouillage. Mettre quelque chose dans un tube nommé n'ouvre qu'une extrémité du tube. L'autre extrémité ne s'ouvre pas tant que le lecteur n'a pas extrait les données. Le noyau suspend le processus dans la première fenêtre de terminal jusqu'à ce que les données soient lues à l'autre extrémité du tuyau.
Le pouvoir des tuyaux
Aujourd'hui, Les pipes nommées sont quelque chose d'un acte de nouveauté.
Les vieux tuyaux Linux, d'un autre côté, ils sont l'un des outils les plus utiles que vous pouvez avoir dans votre boîte à outils de fenêtre de terminal. La ligne de commande Linux commence à prendre vie pour vous, et vous obtenez une toute nouvelle mise sous tension lorsque vous pouvez orchestrer une collection de commandes pour produire une performance cohérente.
Suggestion d'adieu: il est préférable d'écrire vos commandes en pipeline en ajoutant une commande à la fois et en faisant fonctionner cette partie, puis la tuyauterie dans la commande suivante.
setTimeout(fonction(){
!fonction(F,b,e,v,m,t,s)
{si(f.fbq)revenir;n=f.fbq=fonction(){n.callMethod?
n.callMethod.apply(m,arguments):n.queue.push(arguments)};
si(!f._fbq)f._fbq=n;n.push=n;n.chargé=!0;n.version=’2.0′;
n.queue=[];t=b.createElement(e);t.async=!0;
t.src=v;s=b.getElementsByTagName(e)[0];
s.parentNode.insertAvant(t,s) } (window, document,'scénario',
'https://connect.facebook.net/en_US/fbevents.js’);
fbq('init', « 335401813750447 »);
fbq('Piste', « Page View »);
},3000);





