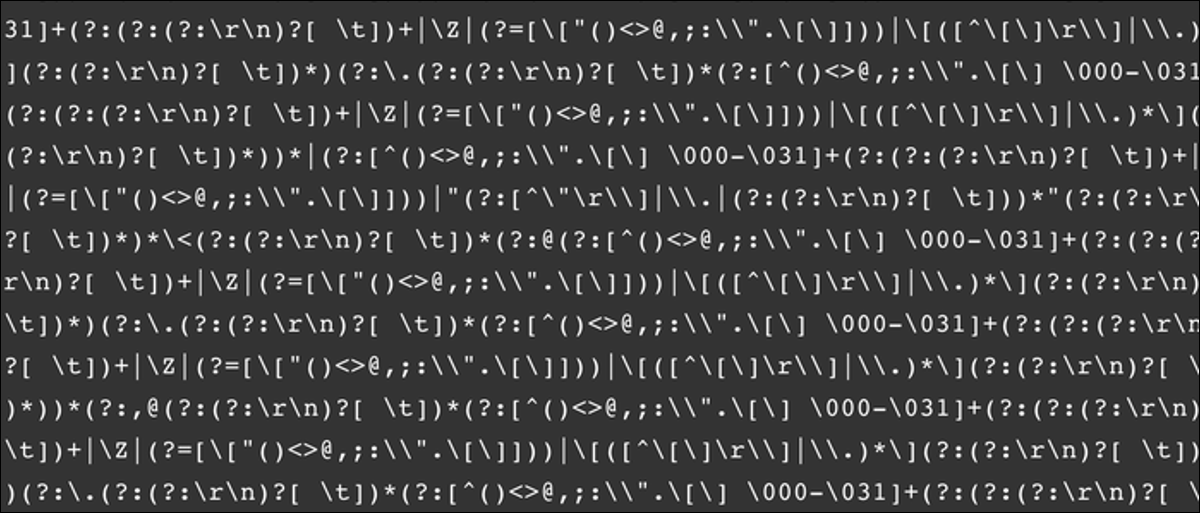
Regex, abréviation d'expression régulière, est souvent utilisé dans les langages de programmation pour faire correspondre les modèles dans les chaînes, rechercher et remplacer, validation d'entrée et reformatage du texte. Apprendre à utiliser correctement Regex peut rendre le travail avec du texte beaucoup plus facile.
Syntaxe des expressions régulières, expliqué
Regex est réputé pour avoir une syntaxe horrible, mais c'est beaucoup plus facile à écrire qu'à lire. Par exemple, voici une regex générale pour un validateur d’e-mails conforme à rfc 5322:
(?:[a-z0-9!#$%&'*+/=?^_`~-]+(?:.[a-z0-9!#$%&'*+/=?^_`~-]+)*|"(?:[x01-
x08x0bx0cx0e-x1fx21x23-x5bx5d-x7f]|[x01-x09x0bx0cx0e-x7f])*")
@(?:(?:[a-z0-9](?:[a-z0-9-]*[a-z0-9])?.)+[a-z0-9](?:[a-z0-9-]*[a-z0-9])?|[(?
:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?).){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-
9][0-9]?|[a-z0-9-]*[a-z0-9]:(?:[x01-x08x0bx0cx0e-x1fx21-x5ax53-x7f]|
[x01-x09x0bx0cx0e-x7f])+)])
S’il semble que quelqu’un se frappe le visage contre le clavier, vous n’êtes pas seul. Mais sous le capot, tout ce gâchis est en fait la planification d’un machine à états finis. Cette machine s’exécute pour chaque personnage, avancer et combiner selon les règles que vous avez définies. De nombreux outils en ligne rendront les diagrammes ferroviaires, montrant comment fonctionne votre machine Regex. Voici la même regex sous forme visuelle:
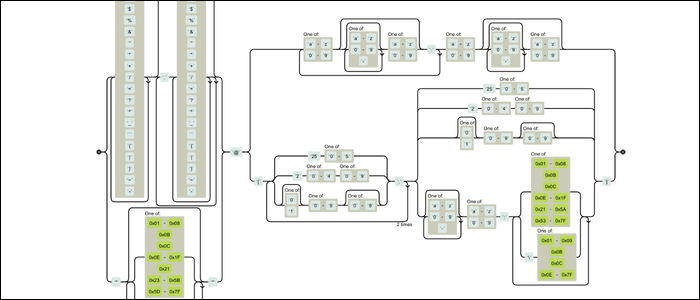
Toujours très confus, mais c'est beaucoup plus compréhensible. C'est une machine avec des pièces mobiles qui ont des règles qui définissent comment tout s'adapte. Vous pouvez voir comment quelqu'un a assemblé cela; ce n'est pas juste beaucoup de texte.
Premier: utiliser un débogueur regex
Avant de commencer, sauf si votre Regex est spécifiquement court ou si vous êtes spécifiquement compétent, vous devez utiliser un débogueur en ligne pour l'écrire et le tester. Facilite grandement la compréhension de la syntaxe. Nous suggestons Regex101 et RegExr, offrant une référence et des tests de syntaxe intégrés.
Comment fonctionne Regex?
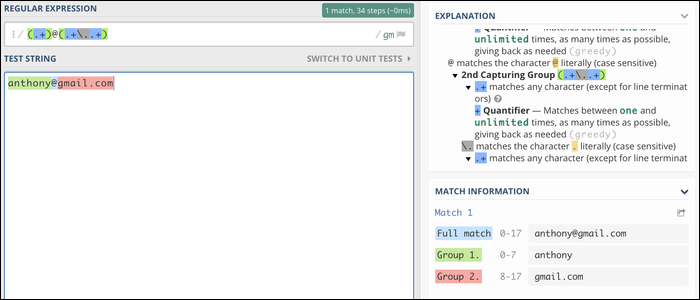
Pour l'instant, concentrons-nous sur quelque chose de beaucoup plus simple. Ceci est un schéma de Regulex pour une expression régulière de correspondance électronique très courte (et certainement pas conforme RFC 5322):

Le moteur Regex démarre à gauche et parcourt les lignes, correspondance des caractères au fur et à mesure. Le groupe # 1 correspond à n'importe quel caractère sauf un saut de ligne, et il continuera à faire correspondre les caractères jusqu'à ce que le prochain bloc trouve une correspondance. Pour ce cas, s'arrête quand il tourne un @ symbole, ce qui signifie que le Groupe # 1 capture le nom de l'adresse e-mail et tout ce qui suit correspond au domaine.
L'expression régulière qui définit le groupe # 1 dans notre exemple de courrier électronique, c'est:
(.+)
Les parenthèses définissent un groupe de capture, qui indique au moteur Regex d'inclure le contenu de la correspondance de ce groupe dans une variable spéciale. Lorsque vous exécutez une expression régulière sur une chaîne, le résultat par défaut est la correspondance complète (pour ce cas, tous les e-mails). Mais il renvoie également chaque groupe de capture, ce qui rend cette expression régulière utile pour extraire les noms des e-mails.
Le point est le symbole de “Tout caractère à l’exception de la nouvelle ligne”. Cela correspond à tout sur une seule ligne, donc si vous avez passé cet e-mail Regex une adresse comme:
%$#^&%*#%$#^@gmail.com
Correspondrait %$#^&%*#%$#^ comme nom, même si c'est ridicule.
Le signe plus (+) est une structure de contrôle qui signifie “faire correspondre le caractère ou le groupe précédent une ou plusieurs fois”. Assurez-vous que tous les noms correspondent, et pas seulement le premier personnage. C'est ce qui crée la boucle trouvée dans le schéma de chemin de fer.
Le reste de Regex est assez simple à comprendre:
(.+)@(.+..+)
Le premier groupe s'arrête lorsqu'il atteint le @ symbole. Plus tard, le groupe suivant commence, qui correspond à nouveau à un certain nombre de caractères jusqu'à ce qu'il rencontre un caractère point.
Parce que des caractères tels que des points, les parenthèses et les barres obliques sont utilisées dans le cadre de la syntaxe dans Regrex, chaque fois que vous voulez faire correspondre ces caractères, doit s'échapper correctement avec une barre oblique inverse. Dans cet exemple, pour correspondre à la période, on a écrit . et l’analyseur le traite comme un symbole qui signifie “faire correspondre un point”.
Correspondance de caractères
Si vous avez des caractères incontrôlés dans votre Regex, le moteur Regex supposera que ces caractères formeront un bloc correspondant. Par exemple, Regex:
il + ça
Correspondra au mot “Bonjour” avec n’importe quel numéro e. Il est nécessaire de s'échapper de tout autre caractère pour qu'il fonctionne correctement.
Regex a également des classes de caractères, qui agit comme une abréviation pour un ensemble de caractères. Ceux-ci peuvent varier en fonction de la mise en œuvre de Regex, mais ces quelques-uns sont standard:
.– correspond à tout sauf à la nouvelle ligne.w– correspond à n’importe quel caractère de “mot”, y compris les chiffres et les traits de soulignement.d– correspondre aux chiffres.b– correspond aux caractères d'espacement (En d'autres termes, espacer, tabulation, nouvelle ligne).
Ces trois ont des homologues en majuscule qui inversent leur fonction. Par exemple, D correspond à autre chose qu'un nombre.
Regex a également un jeu de caractères. Par exemple:
[abc]
Correspondra à n'importe qui a, b, O c. Cela agit comme un bloc et les crochets ne sont que des structures de contrôle. Alternativement, vous pouvez spécifier une plage de caractères:
[a-c]
Ou nier l'ensemble, qui correspondra à n'importe quel caractère qui n'est pas dans l'ensemble:
[^a-c]
Quantificateurs
Les quantificateurs sont une partie importante de Regex. Ils vous permettent de faire correspondre des chaînes dont vous ne connaissez pas le exactement format, mais tu as une bonne idée.
Les + L'opérateur dans l'exemple d'e-mail est un quantificateur, plus précisément le quantificateur “un ou plusieurs”. Si nous ne savons pas combien de temps une certaine chaîne est, mais on sait qu'il est composé de caractères alphanumériques (et il n'est pas vide), nous pouvons écrire:
w+
En même temps de +, Il y a aussi:
- Les
*opérateur, qui correspond “zéro ou plus”. Essentiellement le même que+, sauf que vous avez la possibilité de ne pas trouver de correspondance. - Les
?opérateur, qui correspond “zéro ou un”. A pour effet de rendre un personnage facultatif; Soit c'est là, soit ce n'est pas, et il ne correspondra pas plus d'une fois. - Quantificateurs numériques. Ceux-ci peuvent être un seul nombre comme
{3}, qu’est-ce que cela signifie “exactement 3 fois” ou une gamme telle que{3-6}. Vous pouvez sauter le deuxième numéro pour le rendre illimité. Par exemple,{3,}ça veut dire “3 ou plus de fois”. avec curiosité, je ne peux pas sauter le premier numéro, donc si vous voulez “3 fois ou moins”, vous devrez utiliser une gamme.
Quantificateurs gourmands et paresseux
Sous la capuche, les * et + les opérateurs sont avare. Correspond autant que possible et renvoie ce qui est nécessaire pour démarrer le prochain bloc. Cela peut être un énorme obstacle..
Voici un exemple: disons que vous essayez de faire correspondre HTML ou autre chose avec des accolades fermantes. Votre texte d'entrée est:
<div>Bonjour le monde</div>
Et vous voulez faire correspondre tout à l'intérieur des parenthèses. Vous pouvez écrire quelque chose comme:
<.*>
C'est la bonne idée, mais il échoue pour une raison cruciale: el moteur Regex coïncident “div>Hello World</div>“Pour la séquence .*, puis sauvegarde jusqu'à ce que le bloc suivant corresponde, pour ce cas, avec un crochet fermant (>). J’espère qu’il reculera juste pour correspondre “div", Et puis répétez à nouveau pour faire correspondre le div de fermeture. Mais le backtracker part de la fin de la chaîne et s'arrêtera à la fin du support, qui finit par faire correspondre tout à l'intérieur des parenthèses.
La réponse est de rendre notre quantificateur paresseux, ce qui signifie qu'il correspondra le moins de caractères possible. Sous la capuche, cela ne correspondra en fait qu'à un seul caractère, puis il s'étendra pour remplir l'espace jusqu'à la prochaine correspondance de bloc, ce qui le rend beaucoup plus efficace dans les grandes opérations Regex.
Rendre un quantificateur paresseux se fait en ajoutant un point d'interrogation directement après le quantificateur. C'est un peu déroutant car ? est déjà un quantificateur (et c'est en fait gourmand par défaut). Pour notre exemple HTML, la regex est corrigée avec ce simple ajout:
<.*?>
L'opérateur paresseux peut être ajouté à n'importe quel quantificateur, inclus +?, {0,3}?, e inclus ??. Même si le dernier n'a aucun effet; parce que vous faites correspondre zéro ou un caractère de toute façon, pas de place pour s'agrandir.
Regroupement et recherches
Les groupes dans Regex ont de nombreux objectifs. A un niveau basique, faire correspondre plusieurs tuiles dans un bloc. Par exemple, vous pouvez créer un groupe puis utiliser un quantificateur sur l'ensemble du groupe:
ba(au)+
Ce groupe le “au” répété pour correspondre à la phrase banana, et banananana, etc. Sans le groupe, le moteur Regex correspondrait simplement au caractère final encore et encore.
Ce type de groupe avec deux parenthèses simples s'appelle un groupe de capture et l'inclura dans la sortie:
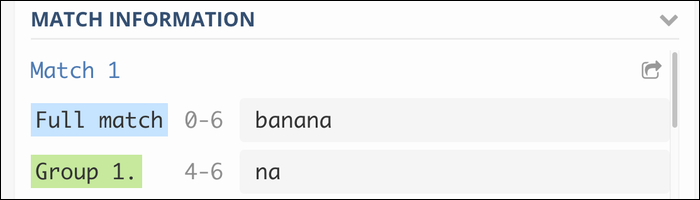
Si vous voulez éviter cela et regrouper simplement les jetons à des fins d'exécution, vous pouvez utiliser un groupe qui ne capture pas:
ba(?:au)
Le point d'interrogation (un personnage réservé) définit un groupe non standard et le caractère suivant définit de quel type de groupe il s'agit. Commencer les groupes avec un point d'interrogation est idéal, parce que sinon, si je voulais faire correspondre les points-virgules dans un groupe, J'aurais besoin de leur échapper sans raison valable. Mais toi pour toujours doivent échapper aux points d'interrogation dans Regex.
Vous pouvez également nommer vos groupes, pour plus de commodité, quand je travaille avec la sortie:
(?'grouper')
Vous pouvez les référencer dans votre Regex, ce qui les fait fonctionner de manière équivalente aux variables. Vous pouvez faire référence à des groupes sans nom avec le jeton 1, mais cela ne va que jusqu'à 7, après quoi vous devrez commencer à nommer des groupes. La syntaxe pour faire référence à des groupes nommés est:
k{grouper}
Il s'agit des résultats du groupe nommé, qui peut être dynamique. Essentiellement, vérifier si le groupe se produit plusieurs fois mais ne se soucie pas de la position. Par exemple, cela peut être utilisé pour faire correspondre tout le texte entre trois mots identiques:
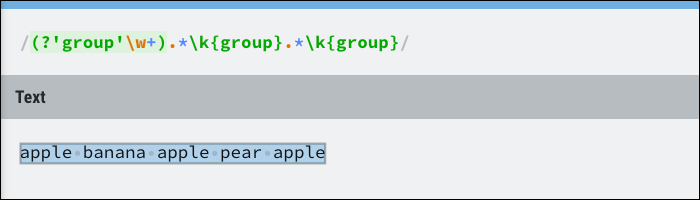
La classe de groupe est l'endroit où vous trouverez la plupart de la structure de contrôle Regex, y compris l'anticipation. Les anticipations garantissent qu'une expression doit correspondre mais ne l'incluent pas dans le résultat. D'une certaine façon, est équivalent à une instruction if et ne correspondra pas si elle renvoie false.
La syntaxe pour une prévision positive est (?=). Voici un exemple:
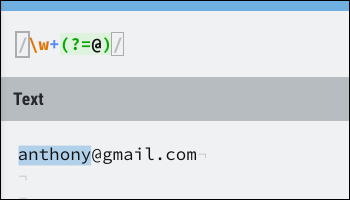
Cela correspond très bien à la partie nom d'une adresse e-mail, arrêt de l'exécution sur division @. Les recherches anticipées ne consomment aucun caractère, donc si vous voulez continuer à courir après qu'une anticipation soit réussie, vous pouvez toujours faire correspondre le caractère utilisé dans l'anticipation.
Parallèlement aux perspectives positives, Il y a aussi:
(?!)– Perspectives négatives, qui assurent une expression. non rencontre.(?<=)– Regard derrière les positivos, qui ne sont pas pris en charge partout en raison de certaines limitations techniques. Ceux-ci sont placés avant l'expression que vous souhaitez faire correspondre et doivent avoir une largeur fixe (En d'autres termes, pas de quantificateurs sauf{number}. Dans cet exemple, Vous pourriez utiliser(?<=@)w+.w+pour correspondre à la partie domaine de l'e-mail.(?<!)– Le négatif regarde en arrière, qui sont égaux aux regards positifs en arrière, mais nié.
Différences entre les moteurs Regex
Toutes les expressions régulières ne sont pas identiques. La plupart des moteurs Regex ne suivent aucune norme spécifique, et certains changent un peu les choses pour s'adapter à leur langue. Certaines fonctionnalités qui fonctionnent dans une langue peuvent ne pas fonctionner dans une autre.
Par exemple, les versions de sed compilé pour macOS et FreeBSD ne prend pas en charge l'utilisation t pour représenter un caractère de tabulation. Vous devez copier manuellement un caractère de tabulation et le coller dans le terminal pour utiliser une tabulation sur la ligne de commande sed.
La plupart de ce tutoriel est compatible PCRE, le moteur Regex par défaut utilisé pour PHP. Mais le moteur JavaScript Regex est différent: ne prend pas en charge les groupes de capture nommés avec des guillemets (veux des parenthèses) et ne peut pas faire de récursivité, entre autres choses. Même PCRE n'est pas entièrement compatible avec les différentes versions, et a beaucoup de différences regex de Perl.
Il y a trop de différences mineures pour les énumérer ici, donc tu peux utiliser ce tableau de référence comparer les différences entre les différents moteurs Regex. En même temps, Les débogueurs Regex comme Regex101 vous permet de changer les moteurs Regex, donc assurez-vous de déboguer en utilisant le bon moteur.
Comment exécuter Regex
Nous avons discuté de la partie correspondante de regex, qui constitue l'essentiel de ce que fait une expression régulière. Mais quand vous voulez vraiment exécuter votre Regex, vous devrez le convertir en une regex complète.
Cela prend généralement le format:
/correspondance/g
Tout à l'intérieur des barres obliques est notre match. Les g c'est un modificateur de mode. Pour ce cas, indique au moteur de ne pas s'arrêter de fonctionner une fois la première correspondance trouvée. Pour rechercher et remplacer Regex, vous devrez souvent le formater comme:
/trouver/remplacer/g
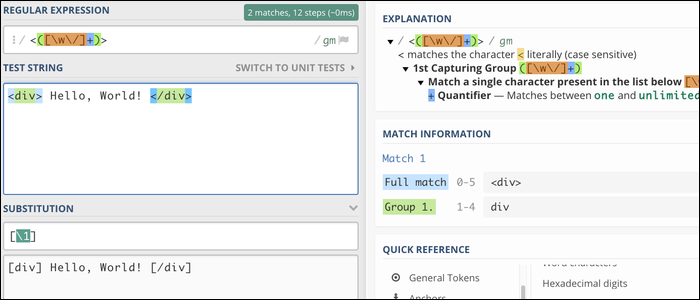
Cela remplace tout le fichier. Vous pouvez utiliser des références de groupe de capture lors du remplacement, ce qui rend Regex très efficace pour formater du texte. Par exemple, cette expression régulière correspondra à n'importe quelle balise HTML et remplacera les crochets standard par des crochets:
/<(.+?)>/[1]/g
Quand ça marche, le moteur correspondra <div> et </div>, qui vous permet de remplacer ce texte (et seulement ce texte). Comme tu peux le voir, le code HTML interne n'est pas affecté:
Cela rend Regex très utile pour rechercher et remplacer du texte. L'utilitaire de ligne de commande pour ce faire est sed, qui utilise le format de base de:
sed '/trouver/remplacer/g' fichier > déposer
Ceci est exécuté dans un fichier et envoyé à STDOUT. Vous devrez le connecter à vous-même (comme montré ici) pour remplacer le fichier sur le disque.
Regex est également compatible avec de nombreux éditeurs de texte et peut vraiment accélérer votre flux de travail en effectuant des opérations par lots.. Pousser, Atome, et contre la morueTous ont une fonctionnalité de recherche et de remplacement Regex intégrée.
De toute façon, Regex peut également être utilisé par programmation et, en général, est intégré dans de nombreuses langues. L'implémentation exacte dépendra de la langue, vous devriez donc consulter la documentation de votre langue.
Par exemple, et JavaScript, regex peut être créé littéralement ou dynamiquement à l'aide d'un objet RegExp global:
var re = nouveau RegExp('abc')
Cela peut être utilisé directement en appelant .exec() méthode d'objet regex nouvellement créée, ou en utilisant le .replace(), .match(), et .matchAll() méthodes sur les chaînes.





