
Ho una procedura in cui devo copiare tutte le immagini da una pagina web. Ero solito eseguire questa procedura con xmllint, che elaborerà un file XML o HTML e stamperà gli input specificati. Ma quando il mio provider host del server ha aggiornato i suoi sistemi, non includevano xmllint. Quindi ho dovuto trovare un altro modo per estrarre un elenco di immagini da una pagina HTML. Si scopre che puoi farlo in bash.
Potresti non pensare che Bash possa analizzare i file di dati, ma puoi farlo con il pensiero intelligente. bash, allo stesso modo delle altre shell UNIX precedenti, puoi analizzare le righe una per una da un file tramite la funzione integrata read dichiarazione.
Predefinito, il read l'istruzione esegue la scansione di una riga di dati e la divide in campi. In genere, read dividere i campi utilizzando spazi e tabulazioni, con nuove righe alla fine di ogni riga, ma puoi modificare questo comportamento impostando il separatore di campo interno (IFS) valore e il delimitatore di fine riga (-d).
Per analizzare un file HTML usando read , seleziona il IFS a un simbolo maggiore di (>) e il delimitatore a un simbolo inferiore a (<). Ogni volta che Bash esegue la scansione di una linea, scansione fino alla prossima volta < (l'inizio di un tag HTML) quindi dividere i dati in ciascuno > (la fine di un tag HTML). Questo codice di esempio accetta una riga di input e divide i dati in TAG e VALUE variabili:
IFS locale='>'
read -d '<' TAG VALUE
Esploriamo come funziona. Considera questo semplice file HTML:
<img src="https://www.systempeaker.com/8315/parsing-html-in-bash/logo.png" alt="Il mio logo" /> <P>un po' di testo</P>
La prima volta read esegue la scansione di questo file, si ferma al primo < simbolo. Da quando < è il primo carattere di questa voce di esempio, il che significa che Bash trova una stringa vuota. Il risultato TAG e VALUE anche le catene sono vuote. Ma va bene per il mio caso d'uso.
La prossima volta che Bash legge la voce, ottenere img src="https://www.systempeaker.com/8315/parsing-html-in-bash/logo.png"↲alt="My logo" />↲ con una nuova riga appena prima dell'alt, e si ferma prima < simbolo nella riga successiva. Dopo read divide la linea al > simbolo, cosa lascia TAG insieme a img src="https://www.systempeaker.com/8315/parsing-html-in-bash/logo.png"↲alt="My logo" / e VALUE con una nuova riga vuota.
La terza volta read analizza il file HTML, ottenere p>some text. Bash divide la stringa al > Con il risultato di TAG contenente p e VALUE insieme a some text .
Ora che hai capito come usare read, è facile analizzare un file HTML più lungo con Bash. Inizia con una funzione Bash chiamata xmlgetnext per analizzare i dati utilizzando read , poiché lo farà più e più volte nello script. Ho nominato il mio ruolo xmlgetnext per ricordarmi che questo è un sostituto di Linux xmllint Programma, ma avrei potuto chiamarlo altrettanto facilmente htmlgetnext .
xmlgetnext () {
IFS locale='>'
read -d '<' TAG VALUE
}
Ora chiamalo. xmlgetnext per analizzare il file HTML. Questo è il mio completo htmltags testo:
#!/bidone/sh # print a list of all html tags xmlgetnext () { IFS locale='>' read -d '<' TAG VALUE } gatto $1 | mentre xmlgetnext ; fare eco $TAG ; fatto
L'ultima riga è la chiave. Scorri il file usando xmlgetnext per analizzare l'HTML e stampare solo il TAG Biglietti. E per come echo funziona con separatori di campo standard, qualsiasi riga come img src="https://www.systempeaker.com/8315/parsing-html-in-bash/logo.png"↲alt="My logo" / contenente una nuova riga sono stampati su una singola riga, Che cosa img src="https://www.systempeaker.com/8315/parsing-html-in-bash/logo.png" alt="My logo" /.
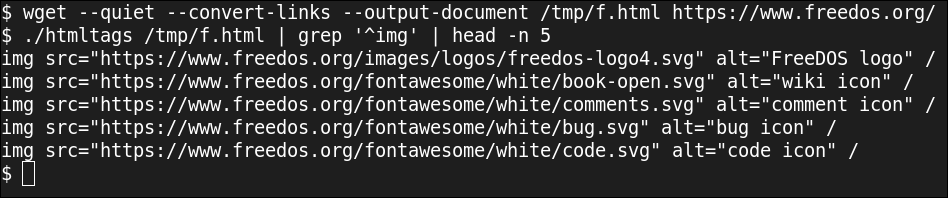
Per ottenere solo l'elenco delle immagini, Eseguo l'output di questo script tramite grep per stampare solo le righe che hanno a img etichetta all'inizio della riga.





