
Bash è una shell e un linguaggio di programmazione ideali, che ti consente di creare script di automazione di fascia alta. In questa seconda parte della serie, vedremo la densità di codifica, commenti in linea e virgolette corrette delle variabili utilizzando virgolette singole o doppie.
Nozioni di base sull'automazione e sugli script di Bash
Se non l'hai già fatto, e sta appena iniziando in bash, lea nuestro post Bash Automation and Scripting Basics Part 1. Questo è il secondo post della nostra serie in tre parti sull'automazione di bash e le basi dello scripting. Nel post di oggi vedremo, tra gli altri argomenti, Densità di codifica Bash e sua connessione alle preferenze dello sviluppatore. Vedremo anche i commenti online in relazione a questo.
Una volta che abbiamo iniziato a creare piccoli script, esploriamo le variabili e lavoriamo con le stringhe di testo, ci rendiamo subito conto che potrebbe esserci una differenza concettuale tra virgolette singole e doppie. C'è, e nel secondo argomento qui sotto ci tufferemo in questo.
Densità e concisione della codifica Bash
Il linguaggio di codifica Bash può essere molto denso e conciso, ma può anche essere spazioso e dettagliato. Depende en gran medida de las preferencias del desarrollador.
Come esempio, el siguiente código Bash:
vero || echo 'untrue'
Que se puede leer como No haga nada y hágalo con éxito (codice di uscita 0), y si eso falla (puede leer el modismo Bash || como OR) muestra el texto ‘falso’, además se puede escribir como:
Se [ ! vero ]; then
echo 'untrue'
fi
Lo que hace que el código sea un poco distinto, pero simplemente hace lo mismo.
Esto a su vez se puede leer como Si es verdad no es (significado por el ! idiom) vero, después muestra el texto ‘falso’.
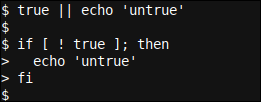
Entrambi i mini-script producono lo stesso output vuoto, Che cosa certo Non è impostore.
La moltitudine di comandi e strumenti disponibili (o installabile) da e sulla riga di comando estendi ulteriormente lo scorrimento funzionale tra script altamente leggibili e codice denso, conciso e difficile da capire.
Sebbene gli esempi precedenti siano brevi e relativamente facili da capire, quando crei una lunga fila (una definizione spesso usata dagli sviluppatori Bash per indicare uno snippet di codice, composto da diversi comandi, scritto in una riga) usando molti di quei comandi , invece di mettere lo stesso in uno script più dettagliato, la differenza diventa più chiara. Considerare:
V ="$(dormire 2 & fg; echo -n '1' | ma 's|[0-9]|un|')" && eco "${V}" | ma 's|[a-z]|2|G' || eco 'fallire'

Questo è un tipico script Bash a riga singola che usa i comandi sleep, fg, echo, e sed così come vari idiomi Bash e regex per dormire semplicemente 2 secondi, genera testo e trasforma questo testo usando espressioni regolari. Lo script controlla regolarmente anche le condizioni / Risultati del comando precedente attraverso l'uso di idiomi Bash || (se non ha successo, Fare quanto segue) e && (in caso di successo, Fare quanto segue)
l'ho tradotto, con funzionalità di corrispondenza fuzzy, a uno script più completo, con qualche modifica. Come esempio, cambiamo il nostro fg (porta il sleep comando messo in secondo piano torna in primo piano, e attendi che finisca come normali processi senza sfondo) per wait cosa si aspetterà il PID del sonno? (iniziato da eval y capturado usando el modismo Bash $!) finire.
#!/bin/bash CMD="dormire 2" eval ${CMD} & aspettare $! EXIT_CODE=${?} V ="$(eco -e "${CMD}n1" | ma 's|[0-9]|un|')" Se [ ${EXIT_CODE} -Eq 0 ]; then echo "${V}" | ma 's|[a-z]|2|g' EXIT_CODE=${?} Se [ ${EXIT_CODE} -Nato 0 ]; then echo 'fail' fi fi
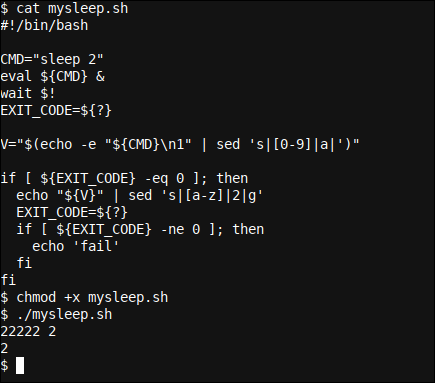
Che differenza! Y esto es solo uno desarrollador escribiéndolo en su camino. El código Bash escrito por otros tiende a ser algo difícil de leer, y esa dificultad aumenta rápidamente con la densidad y la concisión. Comunque, un desarrollador de nivel experto en Bash comprenderá rápidamente inclusive el código muy denso y conciso escrito por otros, con qualche eccezione, come esempio, espressioni regolari.
Per ulteriori informazioni sulla scrittura di espressioni regolari, dai un'occhiata a Come modificare il testo usando regex con sed Stream Editor.
Da questi esempi, è chiaro che il tuo chilometraggio varierà nel tempo. Nonostante questo, generalmente, si consiglia la facilità d'uso del programmatore (scrivere codice ad alta leggibilità) ogni volta che inizi a sviluppare script bash.
Se devi creare un codice denso e conciso, può fornire molti commenti online. Una línea prefijada por un # se considera una línea de comentario / observación, y el símbolo # inclusive se puede utilizar hacia el final de una línea después de cualquier comando ejecutable, para publicar un comentario de sufijo que explique el comando, dichiarazione condizionale, eccetera. Come esempio:
# This code will sleep one second, twice sleep 1 # First sleep sleep 1 # Second sleep
¿Cotizaciones simples o cotizaciones dobles?
in bash, texto entre comillas simples (') son tomados como texto literal por el intérprete de Bash, mientras que el texto entre comillas dobles (") es interpretado (analizado) por el intérprete de Bash. Mientras que la diferencia en cómo funcionan las cosas puede no ser clara de inmediato a partir de esta definición, el siguiente ejemplo nos muestra lo que sucede cuando intercambiamos ' di " e viceversa:
eco ' $(eco "Hello world") ' echo " $(echo 'Hello world') "

Nel primo esempio, el texto $(echo "Hello world") se ve como texto literal, por lo que la salida es simplemente $(echo "Hello world") . Nonostante questo, para el segundo ejemplo, l'uscita è Hello world .
L'interprete Bash ha analizzato il testo tra virgolette per vedere se ha trovato dei linguaggi Bash speciali su cui agire. Un tale idioma è stato trovato in $( ... ) che avvia semplicemente un sottolivello ed esegue tutto ciò che è presente tra i ( ... ) modi di dire. Pensalo come una conchiglia dentro una conchiglia, un subshell, che esegue tutto ciò che gli accade come un comando assolutamente nuovo. L'output di uno o più comandi di questo tipo viene restituito alla shell di livello superiore e inserito nel punto esatto in cui è stata avviata la subshell.
Perché, il nostro sottostrato è corso echo 'Hello world' di cui l'uscita è Hello world. Una volta fatto questo, il sottolivello è terminato e il testo Hello world è stato inserito al posto del $( ... ) invocazione del sottolivello (pensala come tutte $( ... ) il codice viene sostituito da qualsiasi output generato dal sottolivello.
Il risultato, per il guscio superiore, è il seguente comando: echo " Hello world ", di cui l'uscita è Hello world come abbiamo visto.
Nota che cambiamo le virgolette all'interno del sottolivello in virgolette singole. Questo non è necessario! Ci si aspetterebbe di vedere un errore di analisi quando un comando assume la sintassi di echo " ... " ... " ... ", nel senso che le seconde virgolette finirebbero con la prima, seguito da altri test e, perché, causerebbe un errore. Nonostante questo, Questo non è il caso.
E questo non è perché Bash è flessibile con più stringhe di virgolette (accetti echo 'test'"More test"'test' felicemente, come esempio), ma perché lo strato inferiore è un guscio stesso e, perché, si possono usare le virgolette doppie, ancora, all'interno del sottostrato. Proviamo con un ulteriore esempio:
eco "$(eco "$(eco "più virgolette doppie")")"
![]()
Funzionerà bene e produrrà l'output more double quotes. I due sottolivelli annidati (correndo all'interno della shell principale da cui lo stai eseguendo) accettare, allo stesso tempo, virgolette doppie e non vengono generati errori, anche se più virgolette sono nidificate nel comando generale a riga singola. Questo mostra parte della potenza di programmazione di Bash.
In sintesi
Dopo aver esplorato la densità di codifica, ci rendiamo conto del valore della scrittura di codice altamente leggibile. tuttavia, se dobbiamo fare un codice denso e conciso, possiamo aggiungere molti commenti online usando # per una facile leggibilità. Osserviamo le virgolette singole e doppie e come la loro funzionalità differisce sostanzialmente.
Analizziamo brevemente anche i commenti in linea negli script, così come la funzionalità del sottolivello quando eseguito da una stringa racchiusa tra doppi apici. In conclusione, abbiamo visto come un sottolivello può utilizzare un altro insieme di virgolette senza influenzare in alcun modo le virgolette utilizzate a un livello superiore.
En Bash Automazione e basi di scripting (Parte 3), discutiamo del debug degli script e altro ancora. godere!





