
El Linux uniq comando scorre i file di testo per righe singole o duplicate. In questa guida, ne copriamo la versatilità e le caratteristiche, oltre a come ottenere il massimo da questa ingegnosa utility.
Trova le righe di testo corrispondenti in Linux
il uniq il comando è Presto, flessibile ed eccellente in quello che fa. tuttavia, come molti comandi di Linux, ha delle particolarità, quale è giusto, basta che li conosci. Se fai il grande passo senza un po' di conoscenza interna, potresti essere lasciato a grattarti la testa per i risultati. Indicheremo queste stranezze man mano che andiamo avanti.
il uniq Il comando è perfetto per chi è nel campo monouso, progettato per fare una cosa e farla bene. Per questo è particolarmente adatto anche per lavorare con le pipe e svolgere il suo ruolo nelle pipe di comando. Uno dei suoi collaboratori più assidui è sort perché uniq deve avere una voce ordinata su cui lavorare.
Accendiamolo!
IMPARENTATO: Come usare Pipes su Linux
Esecuzione di uniq senza opzioni
Abbiamo un file di testo che contiene i testi di De Robert Johnson canzone Penso che spolvererò la mia scopa. Vediamo cosa uniq la fa.
Scriveremo quanto segue per reindirizzare l'output a less:
uniq dust-my-broom.txt | meno

Otteniamo la canzone completa, comprese le linee duplicate, Su less:
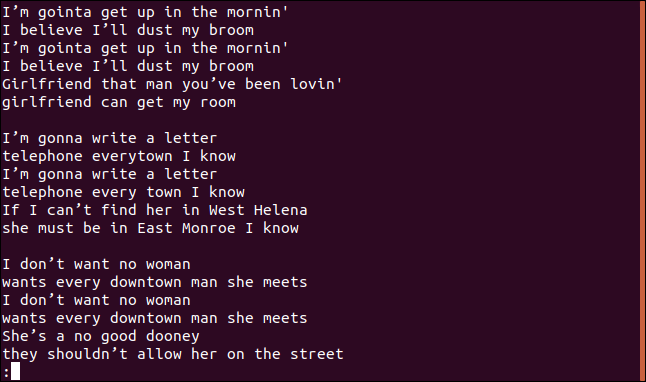
Sembra che non siano né le linee uniche né le linee duplicate.
Corretta, perchè questa è la prima particolarità. Se corri uniq nessuna opzione, si comporta come se avesse usato il -u opzione (linee uniche). Questo dice uniq per stampare solo le singole righe del file. Il motivo per cui vedi linee duplicate è perché, di uniq considerare una linea un duplicato, deve essere adiacente al suo duplicato, cos'è dove? sort entra.
Quando ordiniamo il file, raggruppa le linee duplicate e uniq li tratta come duplicati. noi useremo sort nel file, imbuto di output ordinato a uniqe quindi convogliare l'output finale a less.
Per farlo, scriviamo quanto segue:
sort dust-my-broom.txt | unico | meno

Viene visualizzato un elenco ordinato di righe in less.
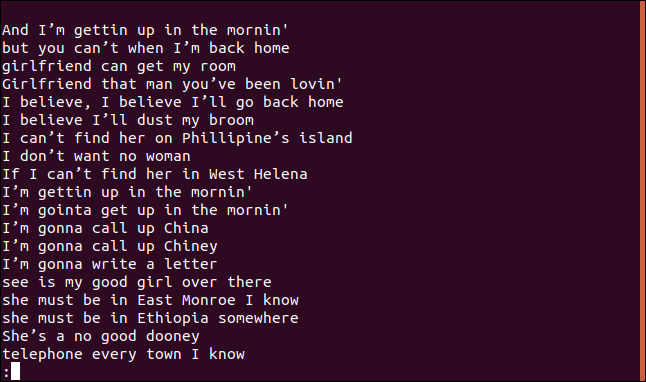
La linea, “Penso che lo rispolvererò dalla mia scopa”, appare sicuramente nella canzone più di una volta. Infatti, si ripete due volte nelle prime quattro righe della canzone.
Quindi, Perché appare in un elenco di linee uniche? Perché la prima volta che appare una riga nel file, è unico; solo le voci successive sono duplicati. Puoi pensarlo come un elenco della prima occorrenza di ogni riga univoca.
Usiamo sort di nuovo e reindirizzare l'output in un nuovo file. In questo modo, non dobbiamo usare sort in ogni comando.
Scriviamo il seguente comando:
sort dust-my-broom.txt > sorted.txt

Ora, abbiamo un file pre-classificato con cui lavorare.
Conteggio dei duplicati
Puoi usare il -c (contare) per stampare il numero di volte che ogni riga appare in un file.
Digita il seguente comando:
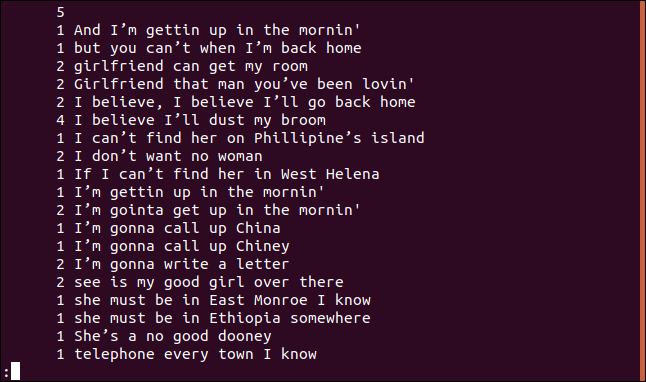
uniq -c sorted.txt | meno

Ogni riga inizia con il numero di volte in cui quella riga appare nel file. tuttavia, noterai che la prima riga è vuota. Questo ti dice che ci sono cinque righe vuote nel file.
Se vuoi che l'output sia ordinato in ordine numerico, può alimentare l'uscita da uniq entro sort. Nel nostro esempio, useremo il -r (invertire) e -n (ordinamento numerico) e incanalare i risultati in less.
Scriviamo quanto segue:
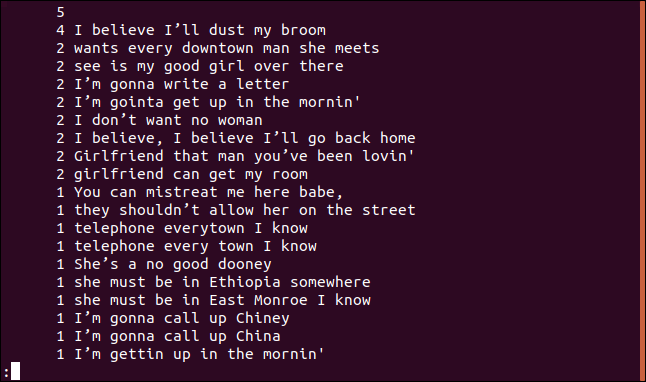
uniq -c sorted.txt | sort -rn | meno

L'elenco è organizzato in ordine decrescente in base alla frequenza di apparizione di ciascuna riga.
Elencare solo righe duplicate
Se vuoi vedere solo le righe ripetute in un file, puoi usare il -d opzione (ripetuto). Non importa quante volte una riga viene duplicata in un file, appare solo una volta.
Per usare questa opzione, scriviamo quanto segue:
uniq -d sorted.txt

Le linee duplicate sono elencate per noi. Noterai la riga vuota in alto, il che significa che il file contiene righe vuote duplicate; non è uno spazio lasciato da uniq per compensare esteticamente l'elenco.
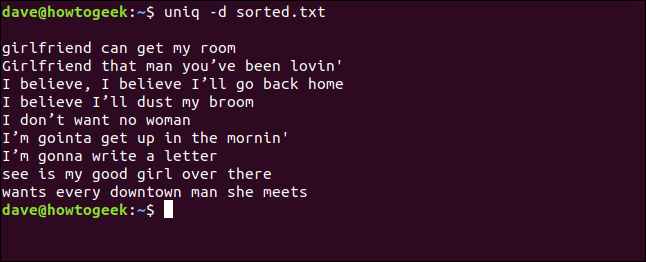
Possiamo anche combinare i -d (ripetuto) e -c (raccontare) opzioni e convogliare l'output attraverso sort. Questo ci dà un elenco ordinato di righe che appaiono almeno due volte.
Digita quanto segue per utilizzare questa opzione:
uniq -d -c sorted.txt | sort -rn
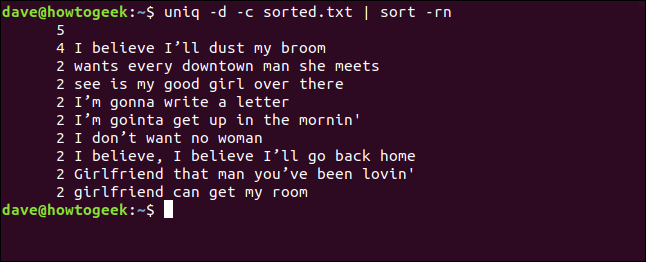
Elenco di tutte le linee duplicate
Se vuoi vedere un elenco di ogni riga duplicata, così come una voce per ogni volta che appare una riga nel file, puoi usare il -D (tutte le linee duplicate) opzione.
Per usare questa opzione, scrivi quanto segue:
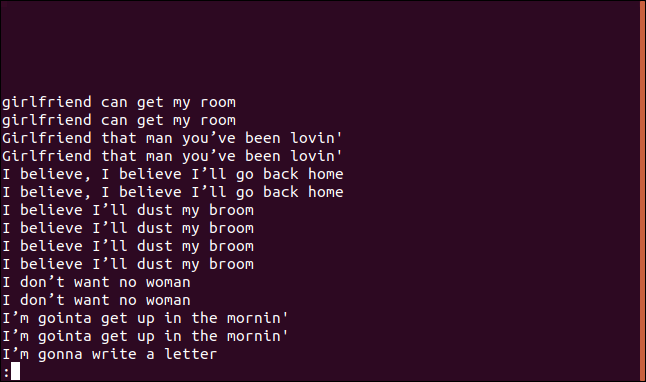
uniq -D sorted.txt | meno

L'elenco contiene una voce per ogni riga duplicata.
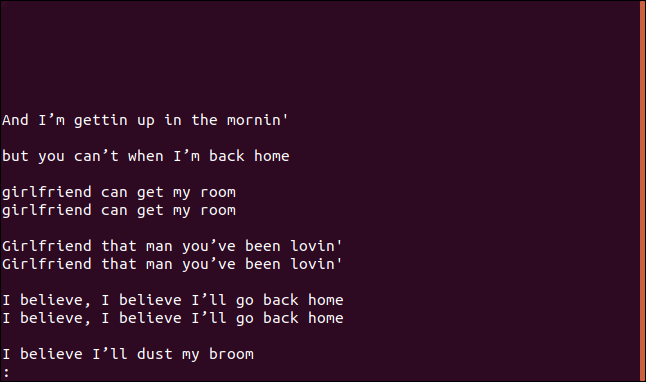
Se usi il --group opzione, stampa ogni riga duplicata con una riga vuota prima (prepend) o dopo ogni gruppo (append), o entrambi prima e dopo (both) ciascun gruppo.
stiamo usando append come nostro modificatore, quindi scriviamo quanto segue:
uniq --group=append sorted.txt | meno

I gruppi sono separati da righe vuote per una facile lettura.
Controllo di un certo numero di caratteri
Predefinito, uniq controlla l'intera lunghezza di ogni riga. tuttavia, se vuoi restringere i controlli ad un certo numero di caratteri, puoi usare il -w (controlla i caratteri) opzione.
In questo esempio, ripeteremo l'ultimo comando, ma limiteremo i confronti ai primi tre caratteri. Per farlo, scriviamo il seguente comando:
uniq -w 3 --group=append sorted.txt | meno

I risultati e i raggruppamenti che riceviamo sono molto diversi.
Tutte le righe che iniziano con “I b” sono raggruppati perché quelle parti delle linee sono identiche, quindi sono considerati duplicati.
Nello stesso modo, tutte le righe che iniziano con “Sono” vengono trattati come duplicati, anche se il resto del testo è diverso.
Ignora un certo numero di caratteri
Ci sono alcuni casi in cui può essere utile omettere un certo numero di caratteri all'inizio di ogni riga, come quando le righe in un file sono numerate. Oppure dì quello che ti serve uniq per saltare un timestamp e iniziare a controllare le righe per il carattere sei invece del primo carattere.
Di seguito è riportata una versione del nostro file ordinata con righe numerate.

Se vogliamo uniq per iniziare i tuoi controlli di confronto sul carattere tre, possiamo usare il -s (salta i caratteri) scrivendo quanto segue:
uniq -s 3 -d -c numerato.txt

Le righe vengono rilevate come duplicate e conteggiate correttamente. Nota che i numeri di riga mostrati sono quelli della prima occorrenza di ogni duplicato.
Puoi anche omettere i campi (una stringa di caratteri e degli spazi bianchi) al posto dei caratteri. Useremo il -f (campi) possibilità di contare uniq quali campi ignorare.
Scriviamo quanto segue per contare uniq ignorare il primo campo:
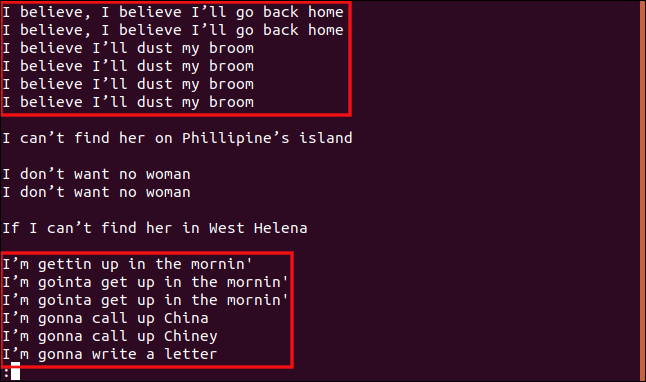
uniq -f 1 -d -c numerato.txt
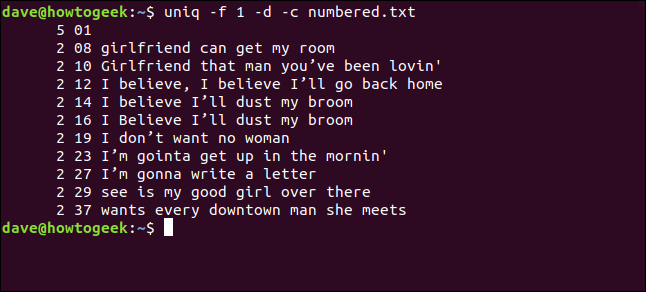
Otteniamo gli stessi risultati che abbiamo ottenuto quando abbiamo detto uniq omettere tre caratteri all'inizio di ogni riga.
Ignorando il caso
Predefinito, uniq fa distinzione tra maiuscole e minuscole. Se la stessa lettera appare in maiuscolo e minuscolo, uniq considera che le linee sono diverse.
Ad esempio, vedere l'output del seguente comando:
uniq -d -c sorted.txt | sort -rn

Le linee “Penso che lo rispolvererò dalla mia scopa” e “Penso che lo rispolvererò dalla mia scopa” non vengono trattati come duplicati a causa della differenza di caso nella finestra di dialogo “B” Su “credere”.
Se includiamo il -i (ignora maiuscole e minuscole), tuttavia, queste righe saranno trattate come duplicati. Scriviamo quanto segue:
uniq -d -c -i sorted.txt | sort -rn
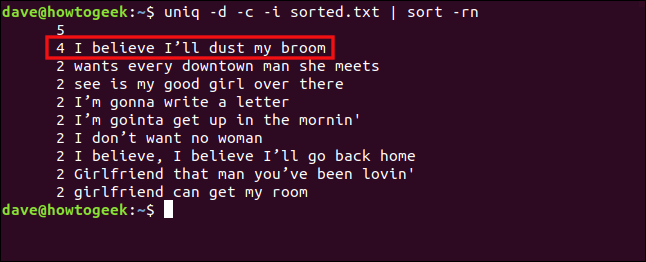
Le linee ora sono trattate come duplicate e raggruppate.
Linux ti offre una moltitudine di utilità speciali. Come molti di loro, uniq non è uno strumento che userai tutti i giorni.
Ecco perché una parte importante del diventare un esperto di Linux è ricordare quale strumento risolverà il tuo problema attuale e dove puoi trovarlo di nuovo.. tuttavia, se pratichi, sarai sulla buona strada.
oh bene, puoi sempre cercare How-To Geek; probabilmente abbiamo un articolo a riguardo.
impostaTimeout(funzione(){
!funzione(F,B,e,v,n,T,S)
{Se(f.fbq)Restituzione;n=f.fbq=funzione(){n.callMethod?
n.callMethod.apply(n,argomenti):n.queue.push(argomenti)};
Se(!f._fbq)f._fbq = n;n.push=n;n.loaded=!0;n.version='2.0′;
n.coda=[];t=b.createElement(e);t.async=!0;
t.src=v;s=b.getElementsByTagName(e)[0];
s.parentNode.insertBefore(T,S) } (window, documento,'copione',
'https://connect.facebook.net/en_US/fbevents.js');
fbq('dentro', '335401813750447');
fbq('traccia', 'Visualizzazione della pagina');
},3000);





