
Questo post dimostrerà come vengono utilizzate e create le funzioni delle variabili locali in Bash. La creazione di funzioni bash ti consente di rendere il tuo codice più strutturale, e le variabili locali aiutano con la sicurezza ed evitano errori di codifica. Gettarsi!
Quali sono Funzioni di bash?
Allo stesso modo di altri linguaggi di codifica, Bash ti consente di creare funzioni dal tuo codice o script. È possibile impostare un ruolo per eseguire un'attività specifica, o una serie di compiti, e può essere chiamato facilmente e velocemente dal tuo codice principale semplicemente usando il nome dato alla funzione.
Puoi anche annidare le chiamate di funzione (chiamare una funzione dall'interno di un'altra funzione), utilizzare le variabili locali all'interno della funzione e persino passare le variabili avanti e indietro con le funzioni, o attraverso l'uso di variabili globali. esploriamo.
funzione a colpo singolo
Definiamo un test.sh con il nostro editor di testo, nel prossimo modo:
#!/bin/bash
welcome(){
eco "Benvenuto"
}
Benvenuto
Successivamente, rendiamo quel file eseguibile aggiungendo l'esecuzione (x) proprietà ed eseguire lo script:
chmod +x test.sh
./test.sh
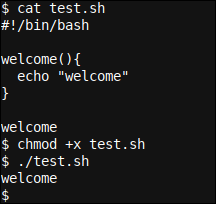
Possiamo vedere come lo script imposta prima a welcome() funzione utilizzando idiomi Bash function_name(), e {…} wrapper di funzioni. In conclusione, chiamiamo welcome alla funzione semplicemente usando il suo nome, welcome.
Quando lo script viene eseguito, ciò che accade in background è che la definizione della funzione è annotata, ma è omesso (In altre parole, non funziona), fino a poco più in basso la chiamata di funzione. welcome viene battuto, e a che punto l'interprete Bash esegue il file welcome funzione e ritorna alla linea subito dopo la chiamata di funzione, che in questo caso è la fine del nostro copione.
Passaggio di variabili alle funzioni Bash
Definiamo un test2.sh con il nostro editor di testo preferito (noi;), nel prossimo modo:
#!/bin/bash if [ -Insieme a "${1}" ]; then echo "Un'opzione richiesta!" Uscita 1 fi func1(){ eco "${1}" } funzione2(){ eco "${2} ${1}" } funzione1 "${1}" funzione2 "un" "B"
Rendiamo nuovamente eseguibile il nostro script usando chmod +x test2.sh ed esegui lo stesso.
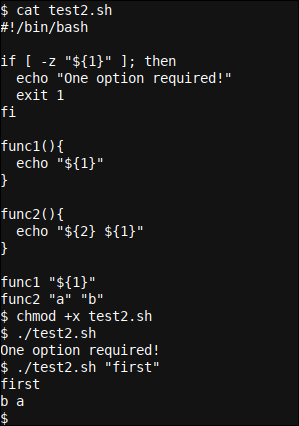
Il risultato risultante può sembrare interessante o addirittura confuso all'inizio.. Nonostante questo, è logico e facile da seguire. La prima opzione passata allo script sarà, globalmente, disponibile dal codice like ${1}, tranne le funzioni interne, dove ${1} diventa il primo parametro passato alla funzione, ${2} il secondo, eccetera.
In altre parole, il globale ${1} variabile (la prima opzione passata allo script dalla riga di comando) non abilitato dalle funzioni, dove il significato di ${1} La variabile cambia alla prima opzione passata alla funzione. Pensa alla gerarchia o pensa a come una funzione potrebbe presentare un piccolo script da sola e questo avrà presto un senso.
Come nota a margine, potrebbe anche essere usato $1 invece di ${1}, ma consiglio vivamente agli aspiranti programmatori bash di circondare sempre i nomi delle variabili con { e }.
Il motivo è che a volte, quando si utilizzano variabili in una stringa, come esempio, l'esecutore bash non può guarda dove finisce una variabile e parte del testo allegato può essere preso come parte del nome della variabile dove non lo è, che genera un output inaspettato. È anche più pulito e chiaro qual è l'intenzione, soprattutto quando si tratta di array e flag alternativi speciali.
Perciò, abbiamo iniziato il nostro programma con il ${1} variabile impostata su "first". Se guardi alla vocazione di func1, vedrai che passiamo quella variabile alla funzione, così il ${1} all'interno della funzione diventa ciò che era nel ${1} del programma, In altre parole "first", ed è per questo che la prima riga di output è in realtà first.
Allora chiamiamo func2 e abbiamo passato due thread "a" e "b" alla funzione. Questi in seguito diventano i ${1} e ${2} automaticamente all'interno del func2 funzione. Funzione interna, li stampiamo capovolti, e la nostra produzione si abbina molto bene con b a come seconda linea di partenza.
In conclusione, facciamo anche un controllo nella parte superiore del nostro script che assicura che un'opzione sia veramente passata al test2.sh script che controlla se "${1}" è vuoto o non usa il -z prova dentro if comando. Usciamo dallo script con un codice di uscita diverso da zero (exit 1) per indicare ai programmi chiamanti che qualcosa è andato storto.
Variabili locali e valori di ritorno
Per il nostro ultimo esempio, definiamo uno script test3.sh come segue:
#!/bin/bash
func3(){
RETROMARCIA locale="$(eco "${1}" | rev)"
eco "${INVERSIONE}"
}
INGRESSO="abc"
RETRO ="$(funzione3 "${INGRESSO}")"
eco "${INVERSIONE}"
Ancora una volta lo rendiamo eseguibile ed eseguiamo lo script. l'uscita è cba come ci si può aspettare scansionando il codice e annotando i nomi delle variabili, eccetera.

Nonostante questo, il codice è complesso e richiede un po' di tempo per abituarsi. esploriamo.
Primo, definiamo una funzione func3 in cui creiamo una variabile locale chiamata REVERSE. Gli assegniamo un valore chiamando un sottolivello ($()), e dall'interno di questo sottolivello facciamo eco a ciò che è stato passato alla funzione (${1}) e canalizzare questa uscita su rev comando.
il rev Il comando stampa l'input ricevuto dalla pipe (in un altro modo) sottosopra. È anche interessante notare qui che il ${1} La variabile rimane all'interno della subshell! È passato integralmente.
Prossimo, ancora da dentro func3 funzione, stampiamo l'output. Nonostante questo, questo output non verrà inviato allo schermo, invece sarà catturato dalla nostra chiamata di funzione e, perché, memorizzato all'interno del 'globale’ REVERSE variabile.
Stabiliamo il nostro ingresso in "abc", Chiama a func3 lavorare di nuovo dall'interno di un sottolivello, passando il INPUT variabile, e assegnare l'uscita a REVERSE variabile. Si noti che non c'è assolutamente alcuna connessione tra il 'globale’ REVERSE variabile e Locale REVERSE variabile dentro lo script.
Considerando che qualsiasi variabile globale, compreso qualsiasi INVERSIONE verrà passato alla funzione, non appena viene definita una variabile locale con lo stesso nome, verrà utilizzata la variabile locale. Possiamo anche provare a vedere questo altro piccolo script test4.sh:
#!/bin/bash
func3(){
RETROMARCIA locale="$(eco "${1}" | rev)"
eco "${INVERSIONE}"
}
INGRESSO="abc"
RETRO ="test"
funzione3 "${INGRESSO}"
eco "${INVERSIONE}"
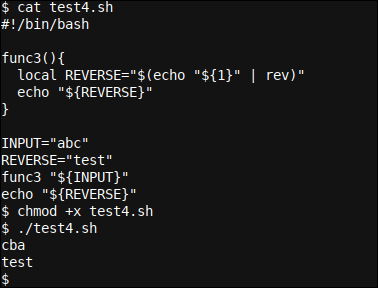
Quando corri, l'uscita è cba e test. il cba questa volta è generato dallo stesso echo "${REVERSE}" entro func3 funzione, ma questa volta viene emesso direttamente invece di essere catturato nel codice sottostante come il func3 "${INPUT}" La funzione non viene chiamata dall'interno di un sottolivello.
Questo script evidenzia due punti di apprendimento che abbiamo trattato in precedenza: primo, Quello, anche quando abbiamo stabilito il REVERSE variabile a "test" all'interno dello script prima di chiamare il func3 funzione – che lui Locale variabile REVERSE Prendi il controllo e usalo invece 'globale’ uno.
Al secondo posto, del nostro 'globale’ REVERSE la variabile mantiene il suo valore anche se c'era un Locale variabile con lo stesso nome usata all'interno della funzione chiamata func3.
Fine
Come potete vedere, le funzioni bash, passare le variabili, così come l'uso di variabili locali e semiglobali rendono il linguaggio di scripting Bash versatile, facile da codificare e ti dà l'opportunità di stabilire un codice ben strutturato.
Inoltre è degno di nota qui che, migliorando la leggibilità del codice e la facilità d'uso, l'utilizzo di variabili locali fornisce ulteriore sicurezza, poiché le variabili non saranno accessibili al di fuori del contesto di una funzione, eccetera. Goditi le variabili e le funzioni locali durante la codifica in Bash!!
Se sei interessato a saperne di più su Bash, vedere Come analizzare correttamente i nomi dei file in Bash e Utilizzo di xargs in combinazione con bash -c per creare comandi complessi.





