
Converting a PDF file to an image can be easily done on the Linux command line using a single command. Find out how to install the utility, how to use it and how to automate its configuration.
What is it poppler-utils ?
As mentioned in the introduction to this post, we need to install a small set of utilities called poppler-utils to help us convert PDF files to images.
The set of utilities poppler-utils allows us to convert images to PDF and PDF to images.
installing poppler-utils
Install poppler-utils on your Debian-based Linux distribution / Apt (like Ubuntu and Mint), make:
sudo apt install poppler-utils
Install poppler-utils on your RedHat-based Linux distribution / Yum (like RedHat and Fedora), do the following:
sudo yum install poppler-utils
Converting PDF to images
The command required is simple and straightforward:
pdftoppm -png test.pdf test
With the pdftoppm command we can convert PDF to images. We specify that we want a PNG file for the output format (using -png) and that our input file is test.pdf.
The output file that we specify as test. pdftoppm will automatically add a page number suffix (What -1) and an extension (based on the previous one -png approved option).
Therefore, the name of the output file will be test-1.png, as we can verify below:
ls test-1.png
eog test-1.png
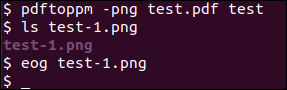
Any subsequent page would be test-2.png etc. The eog command (and eog it's installed) will open the file so you can review the result, even though you can use any other image management program you want.
Batch processing PDF files to images
We can create a single line command to batch process all PDF files with a given name to the images. So we could just add this line to a little script .sh and automate it even more, or we can just use it on the command line whenever we need to convert a large number of PDF files into images.
ls --color=never test*.pdf | but 's|.pdf||' | xargs -I{} pdftoppm {}.pdf -png {}
In this command, we first get a list of directories for all PDF files that have a name starting with proof and ends with .pdf, using the ls --color=never test*.pdf.
the --color=never is essential, since the color-coding symbols on the housing (if they are active, since they are by default) sometimes they can confuse xargs.
Next we use a simple sed substitute command to replace a literal period followed by pdf with nothing. In other words, we eliminate the .pdf file extension.
This gives us the advantage of adding it again later only when necessary, In other words, when specifying the input file for pdftoppm, but not when specifying the output file for the same pdftoppm command, much like our previous example above.
To end, we use xargs to send each pdf filename (minus the .pdf) for pdftoppm one by one. We use the -I option a xargs which enables us to specify any input received (In other words, abbreviated pdf file names) simply using {} in the command that follows.
As you can see, our pdftoppm The command now looks a lot like the first example, with each individual PDF file name as input (with the new suffix .pdf), and as output the name of the pdf file without .pdf.
Let's run it:

This worked fine: the three PDF files, all with one page each, they became three .png records (one image per page and for this case per PDF since each PDF had only one page), all with the correct name and suffix.
As an alternative to -png option, it can also be used -jpeg to generate JPEG files instead. Use pdftoppm --help O man pdftoppm to see a full list of alternatives.
Ending
In this post we saw how easy and simple it can be to convert PDF files into image files, And that directly from the Linux command line!! We are also looking for a simple way to automate this procedure. Enjoy!





