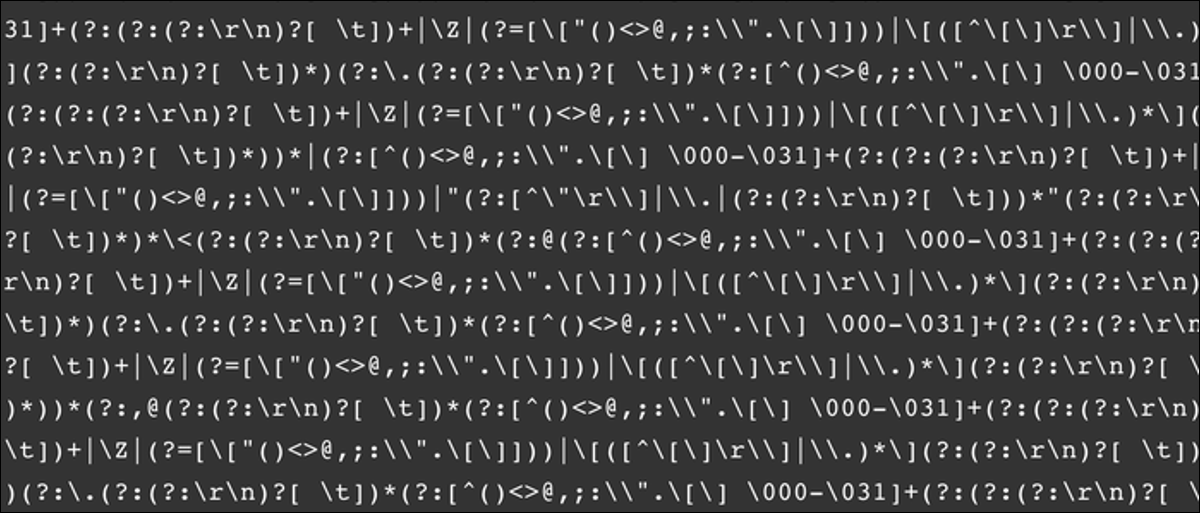
Regex, regular expression abbreviation, often used in programming languages to match patterns in strings, search for and replace, validación de entrada y reformatear texto. Aprender a utilizar correctamente Regex puede hacer que trabajar con texto sea mucho más fácil.
Sintaxis de expresiones regulares, explained
Regex tiene la fama de tener una sintaxis horrible, pero es mucho más fácil de escribir que de leer. As an example, aquí hay una expresión regular general para un validador de correo electrónico compatible con RFC 5322:
(?:[a-z0-9!#$%&'*+/=?^_`~-]+(?:.[a-z0-9!#$%&'*+/=?^_`~-]+)*|"(?:[x01- x08x0bx0cx0e-x1fx21x23-x5bx5d-x7f]|[x01-x09x0bx0cx0e-x7f])*") @(?:(?:[a-z0-9](?:[a-z0-9-]*[a-z0-9])?.)+[a-z0-9](?:[a-z0-9-]*[a-z0-9])?|[(? :(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?).){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0- 9][0-9]?|[a-z0-9-]*[a-z0-9]:(?:[x01-x08x0bx0cx0e-x1fx21-x5ax53-x7f]| [x01-x09x0bx0cx0e-x7f])+)])
If it looks like someone slammed their face against the keyboard, you're not alone. But under the hood, all this mess is actually scheduling a finite state machine. This machine runs for every character, moving forward and combining according to the rules you have set. Many online tools will render railway diagrams, showing how your Regex machine works. Here is the same regex in visual form:
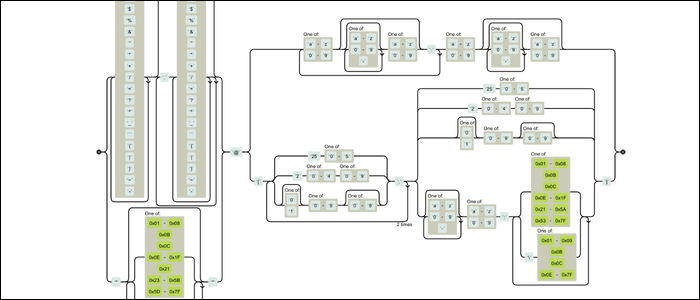
Still very confusing, but it is much more understandable. It is a machine with moving parts that have rules that define how everything fits. You can see how someone assembled this; it's not just a lot of text.
First: use a regex debugger
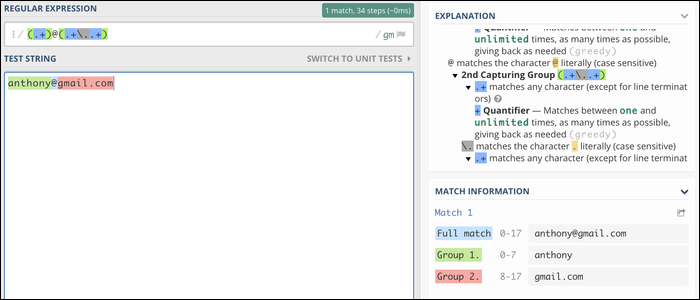
Before starting, unless your Regex is specifically short or you are specifically competent, you must use an online debugger when writing and testing it. Makes it much easier to understand the syntax. We suggest Regex101 and RegExr, offering built-in syntax reference and testing.
How does Regex work?
For now, let's focus on something much simpler. This is a diagram of Regulex for a very short email correspondence regular expression (and definitely not RFC compliant 5322):

The Regex engine starts on the left and travels down the lines, matching characters as you go. The group # 1 matches any character except a line break, and it will continue to match characters until the next block finds a match. For this case, stops when it turns a @ symbol, which means that the Group # 1 captures the name of the email address and everything that follows matches the domain.
The regular expression that sets the Group # 1 in our email example it is:
(.+)
Parentheses define a capture group, which tells the Regex engine to include the content of this group's match in a special variable. When you run a regular expression on a string, the default result is the complete match (for this case, all email). But it also returns each capture group, which makes this regex useful for extracting names from emails.
El punto es el símbolo de “Cualquier carácter excepto nueva línea”. This matches everything on one line, so if you passed this email Regex an address like:
%$#^&%*#%$#^@gmail.com
Would match %$#^&%*#%$#^ as the name, even though that's ridiculous.
The plus symbol (+) es una estructura de control que significa “coincidir con el carácter o grupo anterior una o más veces”. Make sure all the name matches, and not just the first character. This is what creates the loop found in the railroad diagram.
The rest of Regex is pretty simple to figure out:
(.+)@(.+..+)
The first group stops when it hits the @ symbol. Later the next group begins, which again matches quite a few characters until it meets a period character.
Because characters such as dots, parentheses and slashes are used as part of the syntax in Regrex, whenever you want to match those characters, must escape correctly with a backslash. In this example, to match the period, we wrote . y el analizador lo trata como un símbolo que significa “coincidir con un punto”.
Character matching
If you have uncontrolled characters in your Regex, the Regex engine will assume those characters will form a matching block. As an example, Regex:
he + it
Coincidirá con la palabra “hello” con cualquier número de e. It is necessary to escape from any other character for it to function properly.
Regex also has character classes, which act as an abbreviation for a set of characters. These may vary depending on the Regex implementation, but these few are standard:
.– matches anything except newline.w– coincide con cualquier carácter de “word”, including digits and underscores.d– match the numbers.b– matches whitespace characters (In other words, space, tabulation, new line).
These three have uppercase counterparts that reverse their function. As an example, D matches anything other than a number.
Regex also has a character set. As an example:
[abc]
Will match anyone a, b, O c. This acts as a block and the brackets are just control structures. Alternatively, you can specify a range of characters:
[a-c]
Or deny the set, that will match any character that is not in the set:
[^a-c]
Quantifiers
Quantifiers are an important part of Regex. They allow you to match chains where you don't know the exactly format, but you have a pretty good idea.
the + The operator in the email example is a quantifier, específicamente el cuantificador “uno o más”. If we do not know how long a certain chain is, but we know that it is made up of alphanumeric characters (and it is not empty), we can write:
w+
At the same time of +, There is also:
- the
*operator, que coincide con “cero o más”. Essentially the same as+, except you have the option of not finding a match. - the
?operator, que coincide con “cero o uno”. Has the effect of making a character optional; Either it's there or it's not, and it won't match more than once. - Numerical quantifiers. These can be a single number like
{3}, Are you bored to use “exactly 3 times” o un rango como{3-6}. You can skip the second number to make it unlimited. As an example,{3,}it means “3 o más veces”. curiously, can't skip the first number, por lo que si desea “3 veces o menos”, you will have to use a range.
Greedy and lazy quantifiers
Under the hood, the * and + the operators are miserly. Matches as much as possible and returns what is needed to start the next block. This can be a huge hurdle..
Here is an example: let's say you are trying to match HTML or anything else with closing braces. Your input text is:
<div>Hello World</div>
And you want to match everything inside the brackets. You can write something like:
<.*>
This is the correct idea, but it fails for a crucial reason: el motor Regex coincide “div>Hello World</div>“Para la secuencia .*, and then backs up until the next block matches, for this case, with a closing bracket (>). Es de esperar que retroceda solo para coincidir “div“, And then repeat again to match the closing div. But the backtracker runs from the end of the chain and will stop at the end bracket, which ends up matching everything inside the brackets.
The answer is to make our quantifier lazy, which means it will match as few characters as possible. Under the hood, this will actually only match one character, and then it will expand to fill the space until the next block match, which makes it much more efficient in large Regex operations.
Making a quantifier lazy is done by adding a question mark directly after the quantifier. This is a bit confusing because ? is already a quantifier (and it's actually greedy by default). For our HTML example, the regex is fixed with this simple addition:
<.*?>
The lazy operator can be added to any quantifier, included +?, {0,3}?, e inclusive ??. Even though the last one has no effect; because you are matching zero or one character anyway, no room to expand.
Grouping and Lookarounds
Groups in Regex have many purposes. On a basic level, match several tiles in a block. As an example, you can create a group and then use a quantifier on the whole group:
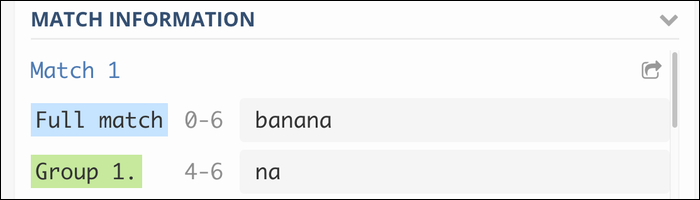
ba(on)+
Esto agrupa la “on” repetida para que coincida con la frase banana, and banananana, and so on. Without the group, the Regex engine would just match the final character over and over again.
This type of group with two single parentheses is called a capture group and will include it in the output:
If you want to avoid this and just group the tokens for execution purposes, you can use a group that does not capture:
ba(?:on)
The question mark (a reserved character) sets a non-standard group and the next character sets what type of group it is. Starting groups with a question mark is ideal, because otherwise, if i wanted to match semicolons in a group, I would need to escape them for no good reason. But you forever have to escape the question marks in Regex.
You can also name your groups, for convenience, when I work with the output:
(?'group')
You can reference these in your Regex, which makes them work equivalently to variables. You can reference unnamed groups with the token 1, but this only goes up to 7, after which you will need to start naming groups. The syntax for referring to named groups is:
k{group}
This refers to the results of the named group, which can be dynamic. Essentially, check if the group occurs multiple times but does not care about the position. As an example, this can be used to match all the text between three identical words:
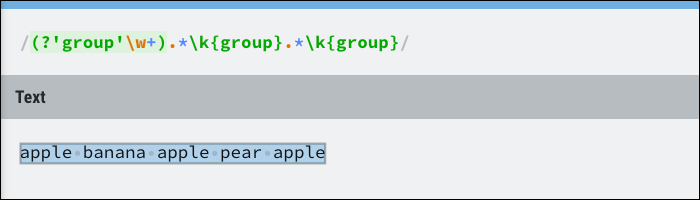
The group class is where you will find most of the Regex control structure, including lookahead. Lookaheads ensure that an expression must match but do not include it in the result. In a way, is equivalent to an if statement and will not match if it returns false.
The syntax for a positive lookahead is (?=). Here is an example:
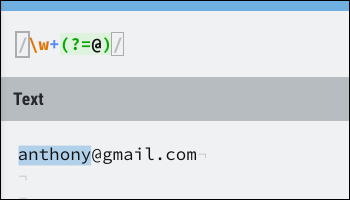
This matches the name part of an email address very neatly, stopping execution on division @. Lookahead searches don't consume any characters, so if you want to continue running after a lookahead is successful, you can still match the character used in lookahead.
At the same time of the positive lookaheads, There is also:
(?!)– Lookaheads negativos, that ensure an expression. no match.(?<=)– Lookbehinds positivos, which are not supported everywhere due to some technical limitations. These are placed before the expression you want to match and must have a fixed width (In other words, no quantifiers except{number}. In this example, You could use(?<=@)w+.w+to match the domain part of the email.(?<!)– Negative looks back, that are equal to the positive back glances, but denied.
Differences between Regex engines
Not all regular expressions are the same. Most Regex engines do not follow any specific standard, and some change things a bit to suit their language. Some features that work in one language may not work in another.
As an example, the versions of sed compiled for macOS and FreeBSD does not support the use t to represent a tab character. You must manually copy a tab character and paste it into the terminal to use a tab on the command line sed.
Most of this tutorial is PCRE compliant, the default Regex engine used for PHP. But the JavaScript Regex engine is different: does not support capture groups named with quotes (want brackets) and can't do recursion, among other things. Even PCRE is not fully compatible with different versions, and has many differences de Perl regex.
There are too many minor differences to list here, so you can use this reference table to compare the differences between various Regex engines. At the same time, Regex debuggers like Regex101 enables you to change Regex motors, therefore make sure you debug using the correct engine.
How to run Regex
We have been discussing the matching part of regex, which makes up most of what a regular expression does. But when you really want to run your Regex, you will need to convert it to a full regex.
This generally takes the format:
/match/g
Everything inside the slashes is our match. the g it's a mode modifier. For this case, tells the engine not to stop running after the first match is found. To find and replace Regex, you will often have to format it as:
/find/replace/g
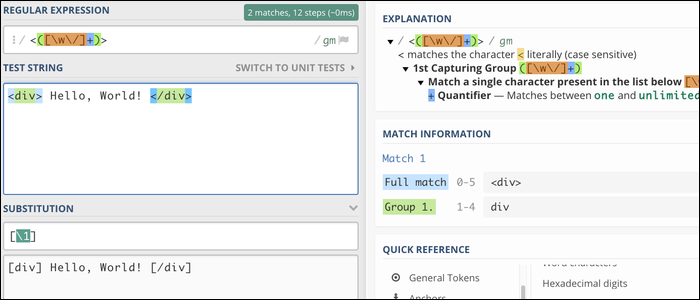
This replaces the entire file. You can use capture group references when replacing, which makes Regex very good at formatting text. As an example, this regex will match any HTML tag and replace standard square brackets with square brackets:
/<(.+?)>/[1]/g
When this works, the motor will match <div> and </div>, which enables you to replace this text (and only this text). As you can see, internal HTML is not affected:
This makes Regex very useful for finding and replacing text. The command line utility to do this is sed, which uses the basic format of:
sed '/find/replace/g' file > file
This is run in a file and sent to STDOUT. You will need to connect it to yourself (as shown here) to replace the file on disk.
Regex is also compatible with many text editors and can truly speed up your workflow by performing batch operations.. Push, Atom, and VS CodAll have Regex find and replace functionality built in.
In any case, Regex can also be used through programming and, in general, it is built into many languages. The exact implementation will depend on the language, so you should consult the documentation for your language.
As an example, and JavaScript, regex can be created literally or dynamically using global RegExp object:
var re = new RegExp('abc')
This can be used directly by calling .exec() newly created regex object method, or using the .replace(), .match(), and .matchAll() methods on strings.





