
Do you want to rename an entire set of files to a number sequence (1.pdf, 2.pdf, 3.pdf,…) en Linux? This can be done with some lightweight scripting and this post will show you how to do exactly that.
Numeric file names
In general, when we scan a PDF file with some hardware (mobile phone, dedicated PDF scanner), the file name will read something like 2020_11_28_13_43_00.pdf. Many other semi-automatic systems produce similar file names based on date and time.
Sometimes, the file may also contain the name of the application that is being used, or some other information like, as an example, the DPI (dots per inch) applicable or scanned paper size.
When collecting PDF files from different sources, file naming conventions can differ significantly and it may be good to standardize on a numeric filename (or numeric in part).
This also applies to other domains and filesets. As an example, your recipes or photo collection, data samples generated in automated monitoring systems, log files ready to archive, a set of SQL files for the database engineer and, usually, any data collected from different sources with different naming schemes.
Rename bulk files to numeric filenames
En Linux, it's easy to quickly rename a whole set of files with totally different filenames, to a number sequence. "Easy" means "easy to run" here: the problem of renaming files to numeric numbers is complex to encode itself: the inline script below took from 3 a 4 hours to investigate, create and test. Many other tested commands, they all had limitations that I wanted to avoid.
Please note that no guarantees are made or provided, and this code is provided “as it is”. Do your own research before running. Having said this, I tested it successfully against files with quite a few special characters, and also against more than 50k files without losing any files. I also checked a file called 'a'$'n''a.pdf' containing a new line.
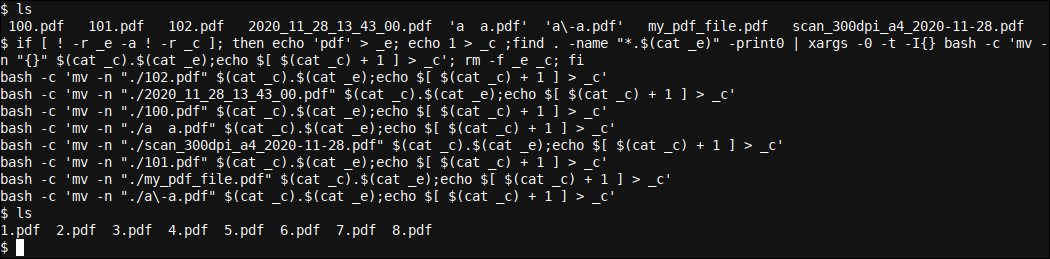
if [ ! -r _e -a ! -r _c ]; then echo 'pdf' > _e; echo 1 > _c ;find . -name "*.$(cat _e)" -print0 | xargs -0 -I{} bash -c 'mv -n "{}" $(cat _c).$(cat _e);echo $[ $(cat _c) + 1 ] > _c'; rm -f _e _c; be
Let's first see how this works and later let's analyze the command. We have created a directory with eight files, all with very different names, except that its extension matches and is .pdf. Next, we execute the previous command:

The result was that 8 files have been renamed to 1.pdf, 2.pdf, 3.pdf, etc., even though their names were quite displaced before.
The command assumes you don't have any 1.pdf for x.pdf still named files. If it does, you can move those files to a separate directory, set the echo 1 to a higher number to start renaming the remaining files at a given offset, and later merge the two directories together again.
Always be careful not to overwrite any files, and it is always a good idea to take a quick backup before updating anything.
Let's see the command in detail. You can help see what is happening by adding the -t option a xargs that allows us to see what happens behind the scenes:
To start, the command uses two small temporary files (called _me and _C) as temporary storage. At the beginning of the eyeliner, makes a security check using a if statement to ensure that both _me and _C files are not present. If there is a file with that name, the script will not continue.
On the topic of using small temporary files versus variables, I can say that, although the use of variables would have been ideal (save some E / S disk), there were two problems that I was running into.
The first is that if you EXPORT a variable at the beginning of the liner and subsequently use that same variable later, if another script uses the same variable (including this script that runs more than once simultaneously on the same machine), so that script, West, may be affected. It is better to avoid such interference when it comes to renaming many files!!
The second was that xargs in combination with bash -c seems to have a limitation in handling variables within the bash -c command line. Even extensive online research did not provide a viable solution for this.. Because, i ended up using a small file _C that keep progress.
_me It is the extension that we will look for and use, and _C is a counter that will automatically increase with each name change. the echo $[ $(cat _c) + 1 ] > _c the code takes care of this, showing the file with cat, adding a number and rewriting it.
The command also uses the best feasible method to handle special filename characters using null termination instead of standard newline termination, In other words, the � character. This is ensured by the -print0 option a find, and for him -0 option to xargs.
The search command will search for any file with the extension specified in the _me file (created by the echo 'pdf' > _e command. You can vary this extension to any other extension you want, but don't prefix it with a period. The point is already included in the last *.$(cat _e) -name specifier for find.
Once you find, have located all the files and sent them: � finished to xargs, xargs will rename files one by one using counter file (_C) and the same file extension (_me). To get the content of the two files, A simple cat the command is used, running from within a sublayer.
the mv move command uses -n to avoid overwriting any files already present. Finally we clean the two temporary files by deleting them.
Although the cost of using two state files and sublayer branching may be limited, this adds some overhead to the script, especially when dealing with a large number of files.
There are all kinds of other solutions for this same problem online, and many have tried and failed to create a fully working solution. Many solutions forgot all kinds of side cases, how to use ls Unspecified --color=never, which can lead to hex codes being parsed when using directory listing color coding.
Despite this, other solutions skipped handling files with spaces, new lines and special characters like ” correctly. For this, the combination find ... -print0 ... | xargs -0 ... is generally indicated and ideal (and both the circumstances and xargs manuals allude to this fact quite strongly).
Although I don't consider my implementation to be the perfect or final answer, seems to be a significant advance for many of the other solutions out there, when using find and � finished chains, securing maximum filename and parsing support, while having some other niceties, how to specify a initial displacementand be totally native of bash.
Enjoy!





