
Column formats, as Apache Parquet, offer great compression savings and are much easier to scan, process and analyze other formats like CSV. In this post, We show you how to convert your CSV data to Parquet using AWS Glue.
What is a columnar format?
CSV files, log files and any other character-delimited files efficiently store data in columns. Each row of data has a certain number of columns, all separated by the delimiter, like commas or spaces. But under the hood, these formats are still just string lines. There is no simple way to scan a single column of a CSV file.
This can be a hindrance with services like AWS Athena, which can run SQL queries on data stored in CSV and other delimited files. Even if you are only querying a single column, Athena has to scan the full file content. The only charge from Athena is the GB of data processed, so increasing the bill by processing unnecessary data is not the best idea.
The answer is a true columnar format. Column formats store data in columns, in the same way as a traditional relational database. The columns are stored together and the data is much more homogeneous, which makes them easier to compress. Son not exactly human readable, but they are understood by the application that processes them without problems. Actually, because there is less data to scan, they are much easier to process.
Because Athena only has to scan one column to make a selection per column, dramatically reduces costs, especially for larger data sets. If you have 10 columns in each file and only scans one, that means cost savings of 90% just by changing to Parquet.
Convert automatically with AWS Glue
AWS Glue is an Amazon tool that converts data sets between formats. Used primarily as part of a pipeline to process data stored in delimited and other formats, and injects them into databases for use in Athena. Although it can be configured to be automatic, you can also run it manually and, with some adjustments, can be used to convert CSV files to Parquet format.
Go to the AWS Glue console and select “Start”. In the sidebar, click on “Add tracker” and create a new tracker. The crawler is configured to search for data from S3 Bucketsand import the data into a database to use for conversion.
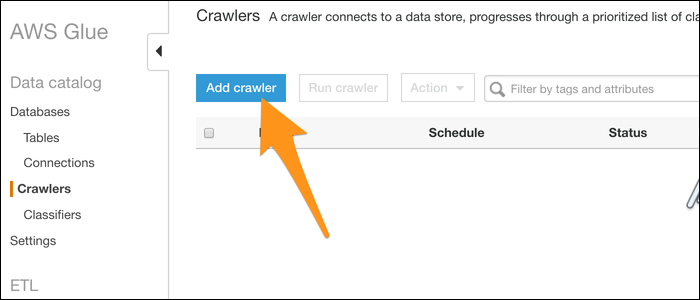
Name your crawler and choose to import data from a data warehouse. Select S3 (even though DynamoDB is another alternative) and enter the path to a folder containing your files. If you only have one file that you want to convert, put it in its own folder.
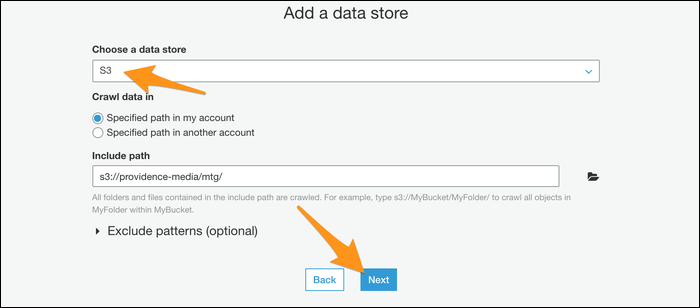
Next, you will be prompted to create an IAM role for your crawler to operate. Create the role and then choose it from the list. You may need to press the update button next to it for it to appear.
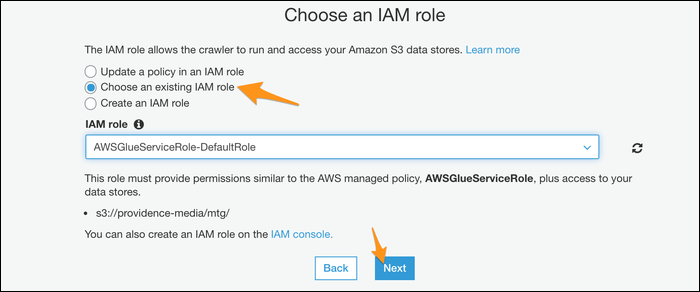
Choose a database for the crawler output; If you have used Athena before, you can use your custom database, but if not, the default should work fine.
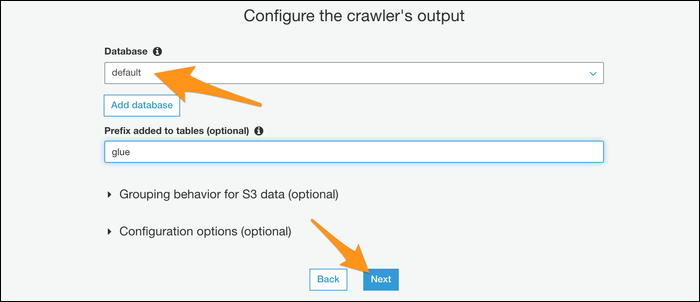
If you want to automate the procedure, you can give your tracker a schedule to run on a regular basis. If that is not the case, choose manual mode and run it yourself from the console.
Once created, go ahead and run the crawler to import the data to the database you chose. If everything worked, you should see your imported file with proper schema. The data types for each column are automatically assigned based on the source input.
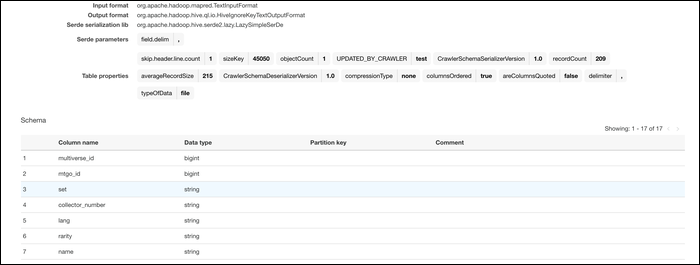
Once your data is in the AWS system, can convert them. From Glue Console, switch to tab “Works” and create a new job. Give it a name, add your IAM role and select “An initiative script generated by AWS Glue” as what the job is running.
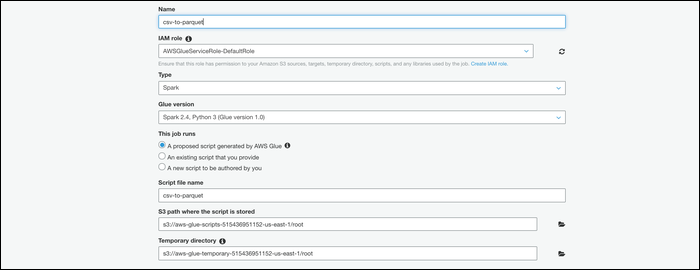
Select your table on the next screen, then choose “Change scheme” to specify that this job runs a conversion.

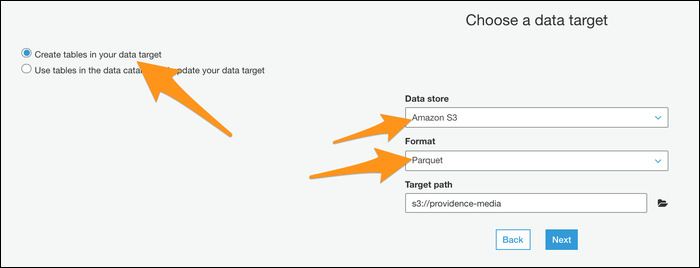
Next, you must choose “Create tables in your data destination”, specify Parquet as the format and enter a new destination path. Make sure this is an empty location without any other files.
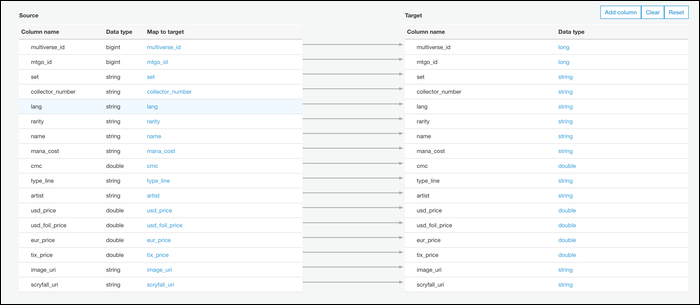
Next, you can edit your file schema. This defaults to a one-to-one mapping of CSV columns to Parquet columns, which is probably what you want, but you can modify it if you need.
Create the job and you will be taken to a page that will allow you to edit the Python script you run. The default script should work fine, therefore press “Keep” and return to the jobs tab.
In our tests, the script always failed unless the IAM role had specific permission to write to the location we specified the output to. You may have to manually edit the permissions from the IAM management console if you encounter the same problem.
Opposite case, click on “Run” and your script should start. The procedure may take a minute or two, but you should see the status in the info panel. When it's over, you will see a new file created in S3.
This job can be configured to run outside of triggers set by the crawler importing the data, so the entire procedure can be automated from start to finish. If you are importing server logs to S3 this way, this can be a simple method to convert them to a more usable format.





