
Optical Character Accreditation Software (OCR) high quality may have been expensive in the past, but now it's enabled, no fee, directly from the command line of your Linux terminal. This post will help you set up and get started with OCR.
What is OCR?
The acronym OCR stands for Optical character accreditation: a software program and a system through which a computer can read the text within the images. Imagine taking a picture of your favorite passage from one of the Lord of the Rings books.
Would you like to quote it elsewhere, but all he has is a photo. OCR software can help you by analyzing that photo / image and finding all the text within it.
After, the OCR software will analyze, for every letter discovered, the graphic points seen in the image and translate them / will transform into real text that a computer can use, as an example, in a word processor.
Although there are many OCR programs available, some paid and some free, not all are of the same quality. Some packages will provide poorer quality results, others will align closely with the text seen in the photo or image.
In general terms, standard books (or Internet web page impressions) will work very well and should produce results of reasonable quality in all cases, since the sources are straight and uniform and are at only one angle, as long as the original photo or scan is of a reasonable size. quality.
It is also good to pay attention that even advanced software packages can have problems with poor quality or blurred images., and most packages may have problems with different writing styles, etc. Other challenges can include text mixed with images or photos, or different directions (as an example, left (text both to the right, top to bottom or at an angle) within the same page.
This makes selecting, and potentially pay, an OCR package is a maybe long procedure, especially if you want to test and examine each package.
For those using Linux, there is a great alternative route. A high-quality, cost-free OCR software based on LSTM Neural Net with Unicode support (UTF-8) and that it can recognize more than 100 languages by default. It also supports many output formats such as HTML, PDF and plain text.
Without any more preambles; Welcome to Tesseract OCR!
installing Tesseract OCR
Install Tesseract OCR on your Debian-based Linux distribution / Apt (like Ubuntu and Mint), make:
sudo apt install tesseract-ocr libtesseract-dev tesseract-ocr-eng
Install Tesseract OCR at RHEL and Centos, do the following:
sudo yum install epel-releasesudo yum install tesseract-devel leptonica-devel
Install Tesseract OCR in Fedora, make:
sudo yum install tesseract-devel leptonica-devel
Install Tesseract OCR on OSX, Do the following:
brew install tesseract
Let's go to OCR!
We will use a simple image that contains the following text:

To convert this image, all you need to do is open the Terminal prompt, change the directory (using the cd your_directory_with_images command) to the directory that contains your images (as an example, if you have created an image directory in your home directory (~/images) you can simply use cd ~/images) and OCR of the files:
tesseract -l eng input_for_ocr.png output_from_ocr
cat output_from_ocr.txt
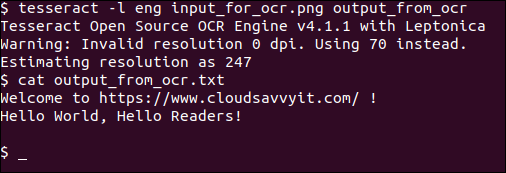
Very simple and straightforward. And as we can see, the output is perfect.
We specify the English language using the -l eng option. You can consult the tesseract manual (man tesseract) for any other available language code.
We also specify the input image (input_for_ocr.png) as well as the output file output_from_ocr without any file extension, which will use the default plain text .txt format.
We can also change the output format to PDF using a slightly longer command that simply specifies the output format at the end:
tesseract -l eng input_for_ocr.png output_from_ocr pdf

Adding the pdf suffix, the output format used was PDF. When we open the PDF file (output_from_ocr.pdf), we can see that the text can be chosen and copied / paste as was done with the word Readers! here:
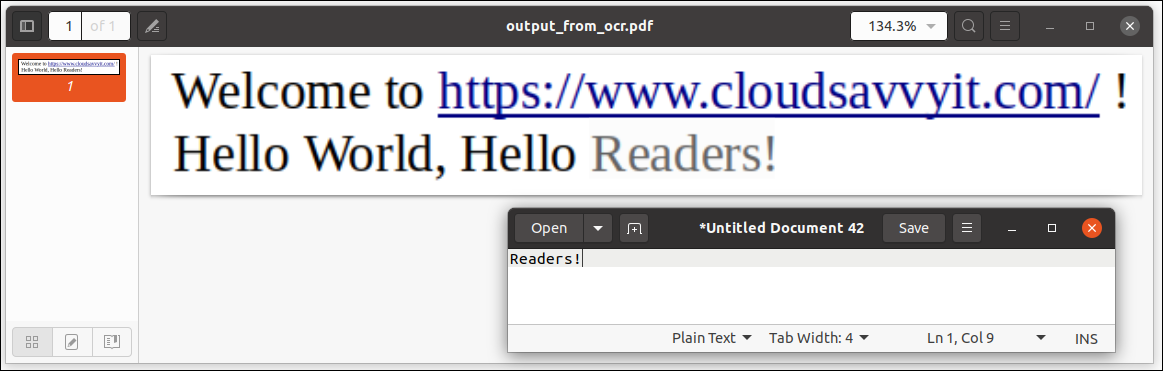
In other words, PDF file contains selectable and text-based data, no graphic information (and therefore not selectable). Excellent!
What if I want to OCR a PDF file?
Sometimes, you can receive a PDF file that, even though the PDF format supports real text within the pages, contains only images with text. This can be frustrating, since copy and paste will not be available. You can also OCR these pages, with a little solution.
You will first want to convert your PDF file to images, one image per page, and later OCR the individual pages in text. A little more work, but still save a lot of time instead of retyping the text manually.
To know the simple steps to convert a PDF file to images, or even to create a script and automate the conversion of multiple PDF files, you can read our post Convert PDF to images from Linux command line.
Ending
In this post, we explore Tesseract, the high-quality no-cost command-line OCR engine for Linux. We saw how we could easily convert images to text using a simple command.
We also analyze the conversion of images into text-based PDF files, and we mentioned a post where you can find information about how to pre-convert image-based PDF files into images so that they can later be converted to text using the OCR method shown here.
Enjoy!





