
El Linux curl The command can do much more than download files. Find out what curl he is able to, and when should you use it instead of wget.
curl vs. wget: What is the difference?
People often struggle to identify the relative strengths of the wget and curl commands. Commands have some functional overlap. Each can retrieve files from remote locations, but that's where the similarity ends.
wget it's a fantastic tool to download content and files. You can download files, web pages and directories. It contains smart routines to go through links on web pages and download content recursively in an entire web portal. It's second to none as a command line download manager.
curl satisfy a completely different need. Yes, can recover files, but you cannot recursively browse a web portal looking for content to retrieve. That curl what it really does is allow you to interact with remote systems by making requests to those systems and retrieving and displaying their responses. Those responses can be files and website content, but they can also contain data provided through a web service or API as a result of the “question” made by the curl application.
AND curl not limited to websites. curl supports more than 20 protocols, including HTTP, HTTPS, SCP, SFTP y FTP. And possibly, due to its superior handling of Linux pipes, curl can be more easily integrated with other commands and scripts.
The author of curl has a website that describe the differences you see Among curl and wget.
Curl installation
Of the computers used to research this post, Fedora 31 and Manjaro 18.1.0 They had curl already installed. curl it had to be installed on Ubuntu 18.04 LTS. In Ubuntu, run this command to install it:
sudo apt-get install curl

The curl version
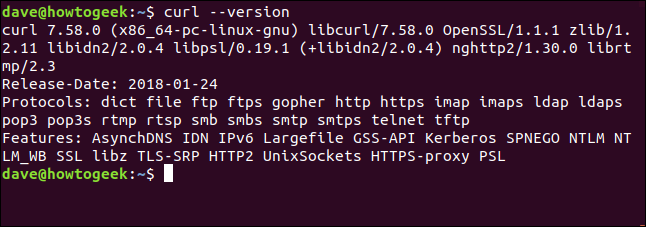
the --version option does curlreport your version. It also lists all the protocols it supports.
curl --version
Retrieve a web page
If we aim curl On a website, will get it back for us.
curl https://www.bbc.com

But its default action is to download it in terminal window as source code.
Beware: If you don't say curl want something stored as a file, it will forever dump it in the terminal window. If the file you are recovering is a binary file, the result can be unpredictable. The shell may try to interpret some of the byte values in the binary file as control characters or escape sequences.
Save data to file
Let's tell curl to redirect the output to a file:
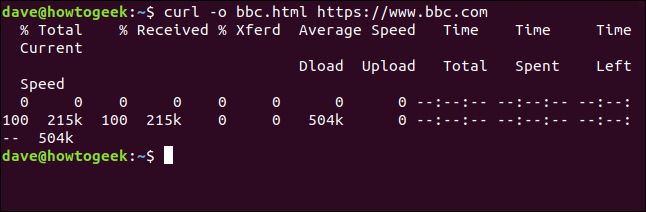
curl https://www.bbc.com > bbc.html

This time we do not see the recovered information, sent directly to the archive by us. Because there is no terminal window output to display, curl generates a set of progress information.
You did not do this in the example above because the progress information would have been scattered throughout the source code of the web page, so that curl deleted it automatically.
In this example, curl detects that the output is being redirected to a file and that it is safe to generate the progress information.
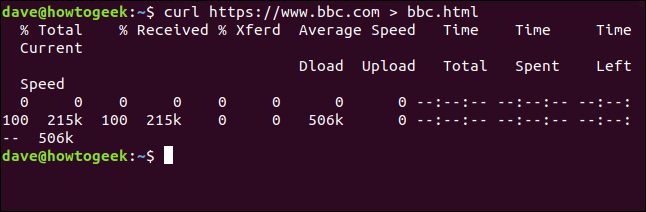
The information provided is:
- % Total: The total amount to be recovered.
- % He received: The percentage and actual values of the data retrieved so far.
- % Xferd: The percentage and the actual shipping, if data is loading.
- Medium speed download: Average download speed.
- Medium speed load: Average upload speed.
- Total time: The total estimated duration of the transfer.
- Time used: The time elapsed so far for this transfer.
- Time left: The estimated time remaining for the transfer to complete.
- Current speed: The current transfer speed for this transfer.
Because we redirect the output of curl to a file, now we have a file called “bbc.html”.
By double clicking on that file, your default browser will open to display the retrieved web page.
Please note that the address in the browser's address bar is a local file on this computer, not a remote web portal.
We do not have to redirect the output to create a file. We can create a file using the -o (Exit) option, and saying curl to create the file. Here we are using the -o and providing the name of the file we long to create “bbc.html”.
curl -o bbc.html https://www.bbc.com
Using a progress bar to monitor downloads
For text-based download information to be replaced by a simple progress bar, use el -# (progress bar) option.
curl -x -o bbc.html https://www.bbc.com

Restarting an interrupted download
It's easy to restart a download that has finished or interrupted. Let's start downloading a sizeable file. We will use the latest Ubuntu long-term support build 18.04. We are using the --output option to specify the name of the file in which we long to save it: “ubuntu180403.iso”.
curl --output ubuntu18043.iso http://releases.ubuntu.com/18.04.3/ubuntu-18.04.3-desktop-amd64.iso

Download begins and progresses to completion.
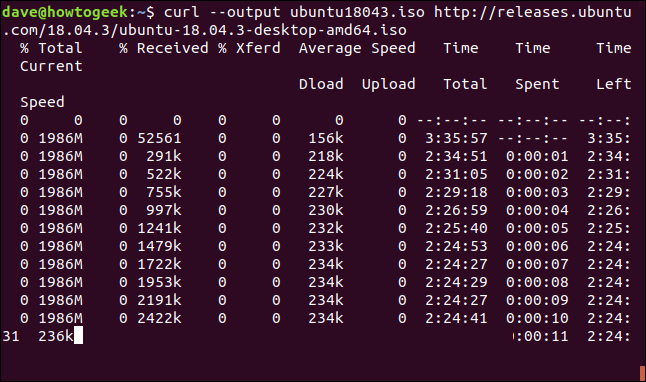
If we forcibly interrupt the discharge with Ctrl+C , we return to the command prompt and the download is abandoned.
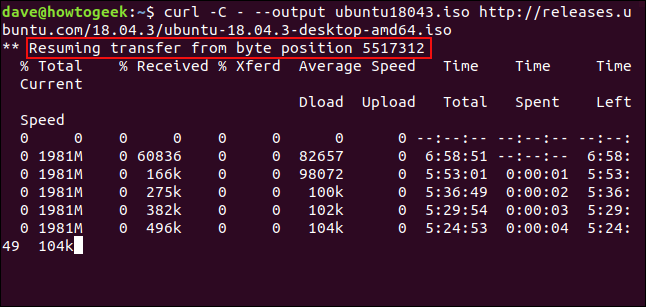
To restart the download, use el -C (continue on) option. This causes curl to restart the download at a specified point or make up for inside the destination file. If you use a dash - like displacement, curl will look at the already downloaded part of the file and determine the correct offset to use for itself.
curl -C - --output ubuntu18043.iso http://releases.ubuntu.com/18.04.3/ubuntu-18.04.3-desktop-amd64.iso

Download restarts. curl reports the offset at which it is rebooting.
Retrieving HTTP headers
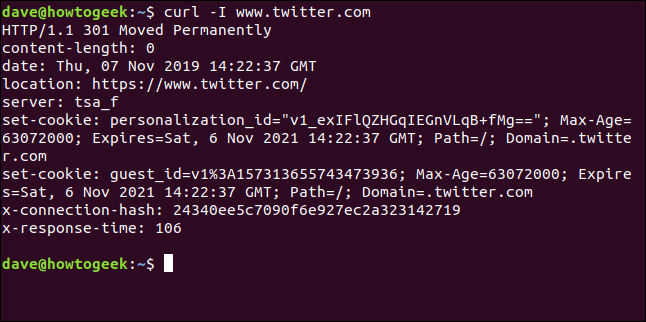
With the -I (head), can only retrieve HTTP headers. This is the same as sending the Comando HTTP HEAD to a web server.
curl -I www.twitter.com

This command only retrieves information; does not download web pages or files.
Download multiple URLs
Using xargs we can download several URLs right away. Maybe we want to download a series of web pages that make up a single post or tutorial.
copy these urls into an editor and save them to a file called “urls-to-download.txt”. We can use xargs for treat the content of each line of the text file as a parameter that will feed to curl, Successively.
https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#0 https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#1 https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#2 https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#3 https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#4 https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#5
This is the command that we must use to have xargs pass these URLs to curl one at the same time:
xargs -n 1 curl -O < urls-to-download.txt
Note that this command uses the -O (remote file) output command, that uses a “O” capital letter. This option causes curl to save the recovered file with the same name as the file on the remote server.
the -n 1 option says xargs to treat each line of the text file as a single parameter.
When you run the command, you will see multiple downloads start and end, one after another.
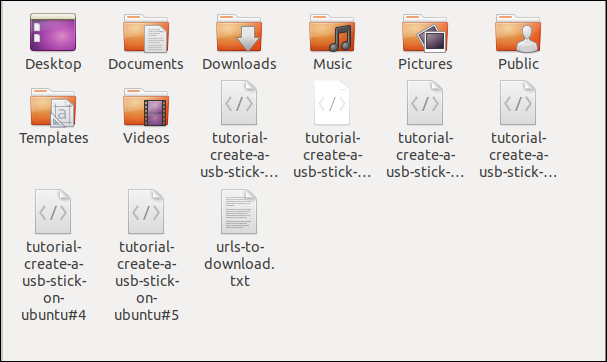
Checking in file explorer shows that multiple files have been downloaded. Each one bears the name it had on the remote server.
RELATED: How to use the xargs command in Linux
Downloading files from an FTP server
Using curl with a File Transfer Protocol (FTP) It is easy, even if you have to authenticate with a username and password. To pass a username and password with curl use the -u (Username) and write the username, two points ":" and the password. Do not put a space before or after the colon.
This is a free FTP server hosted by Rebex. The test FTP site has a preset username of “demonstration” and the password is “password”. Do not use this type of weak username and password on a production FTP server or “real”.
curl -u demo:password ftp://test.rebex.net

curl it realizes that we are pointing it to an FTP server and returns a list of the files that are present on the server.

the only file on this server is a file “readme.txt”, from 403 bytes long. Let's get it back. Use the same command as just now, with file name attached:
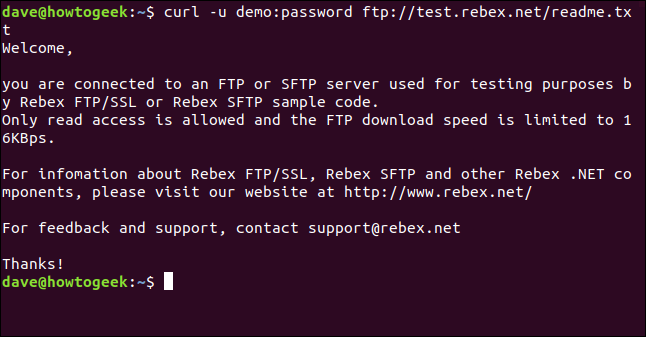
curl -u demo:password ftp://test.rebex.net/readme.txt

The file is retrieved and curl displays its content in the terminal window.
In almost all cases, it will be more convenient to save the recovered file to disk, instead of displaying it in the terminal window. Once again we can use the -O (remote file) exit command to save the file to disk, with the same filename you have on the remote server.
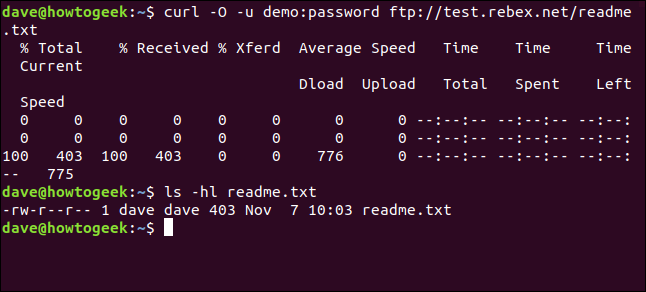
curl -O -u demo:password ftp://test.rebex.net/readme.txt

The file is retrieved and saved to disk. We can use ls to check the file details. Has the same name as the file on the FTP server and has the same length, 403 bytes.
ls -hl readme.txt
RELATED: How to use the FTP command in Linux
Sending parameters to remote servers
Some remote servers will accept parameters in requests sent to them. Parameters can be used to format the returned data, as an example, or they can be used to choose the exact data that the user wants to recover. It is often feasible to interact with the web. application programming interfaces (API) using curl.
As a simple example, the ipify The web portal has an API that can be consulted to establish your external IP address.
curl https://api.ipify.org
Adding the format parameter to command, with the value of “json” we may reorder our external IP address, but this time the returned data will be encoded in the JSON format.
curl https://api.ipify.org?format=json

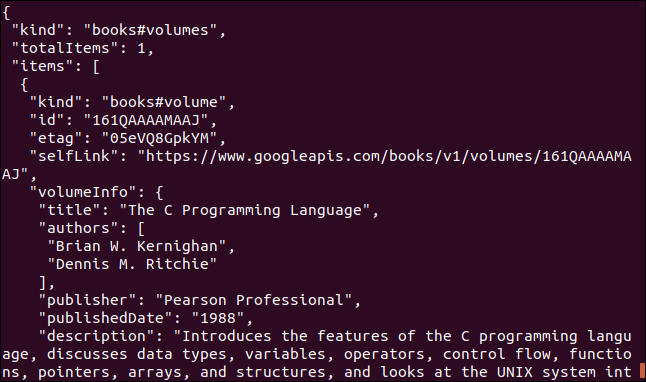
Here is another example that uses a Google API. Returns a JSON object that describes a book. The parameter you need to supply is the International Standard Book Number (ISBN) number of a book. You can find them on the back cover of most books, generally under a barcode. The parameter we will use here is “0131103628”.
curl https://www.googleapis.com/books/v1/volumes?q=isbn:0131103628

The data returned is complete:
Sometimes curl, a veces wget
If you wanted to download content from a web portal and have the web portal tree structure recursively search for that content, would use wget.
If you wanted to interact with a remote server or API, and possibly download some files or web pages, would use curl. Especially if the protocol was one of the many not supported by wget.
setTimeout(function(){
!function(f,b,e,v,n,t,s)
{if(f.fbq)return;n=f.fbq=function(){n.callMethod?
n.callMethod.apply(n,arguments):n.queue.push(arguments)};
if(!f._fbq)f._fbq = n;n.push=n;n.loaded=!0;n.version=’2.0′;
n.queue=[];t=b.createElement(e);t.async=!0;
t.src=v;s=b.getElementsByTagName(e)[0];
s.parentNode.insertBefore(t,s) } (window, document,’script’,
‘https://connect.facebook.net/en_US/fbevents.js’);
fbq(‘init’, ‘335401813750447’);
fbq(‘track’, ‘PageView’);
},3000);





