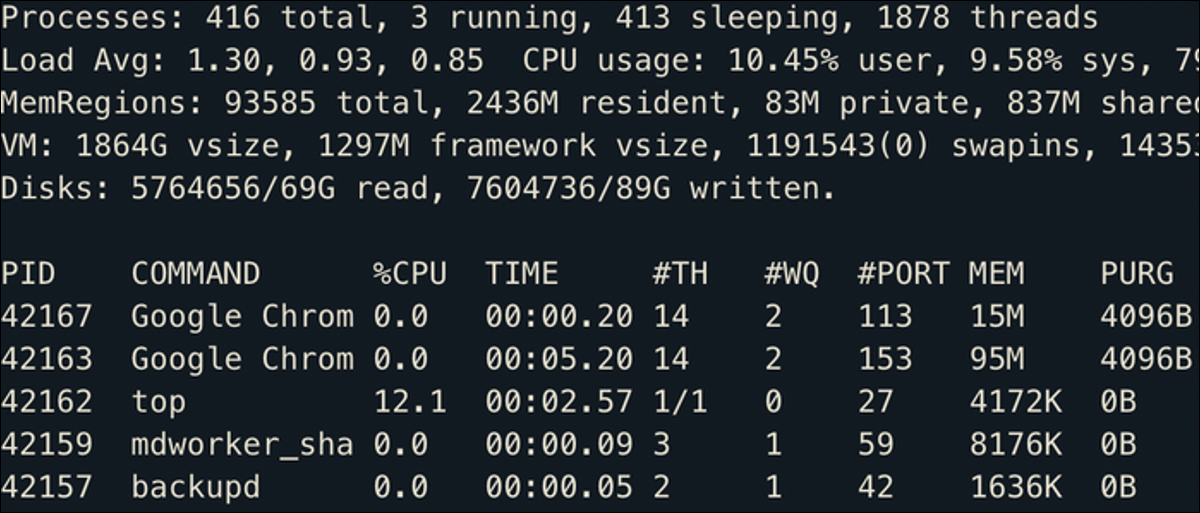
Whenever a procedure is created on a Linux system, it is assigned a new number that identifies it against other applications. This is the procedure ID, o PID, and is used throughout the system to manage running processes.
How processes work in Linux
The first procedure that Linux runs is called systemd, receiving PID 0. All other processes are generated as children of systemd. The first few generally will be low-level Linux things that you don't have to worry about., but further down the tree, the system will start launching user-level processes like MySQL and Nginx.
Each procedure also has a PPID, which stores the PID of the parent by which the procedure was created. There is also a process TTY, which stores the ID of the terminal you used to start the procedure, y UID, which stores the ID of the user who created it. Any procedure that is generally missing a TTY is called Devil, a definition used to denote system processes that run in the background and do not have a control terminal.
Whenever a procedure is closed, that PID is enabled for use by another procedure. Each procedure is also closed with an exit code, which is generally used to indicate whether or not an error occurred. The exit code 0 it's a clean exit, anything greater is a specific error.
On a more technical note, PIDs are an important part of Linux namespaces. Namespaces hide certain parts of the system from processes running in different namespaces, what powers containerization tools like Docker. With namespaces, the PID tree is cut at a certain branch, and only that branch is delivered to the containerized procedure. This branch restarts from the PID 1, so the container looks like it's running on a brand new Linux installation.
Visualization processes
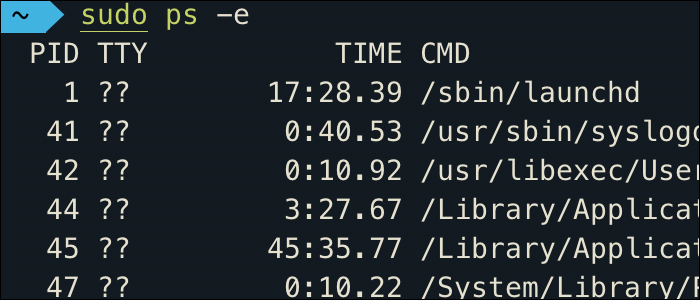
For a complete list of processes, can run the ps command:
sudo ps -e
Which will generate a very long list of all running processes, which is certainly a bit difficult to navigate.
You can filter the results by piping the output to grep, What ps does not have a built-in search function:
sudo ps -e | grep "processname"
Even though you should be warned that, strangely enough, this will also match the newly created grep process, What ps show command arguments, which include your matching string, which evidently matches itself. If you only need the PID of a given procedure name, the pgrep The command just returns the PID and nothing else.
A much more useful viewer is the top command, which acts as a Task Manager from your terminal. Shows all processes sorted by CPU usage, as well as some general system statistics:
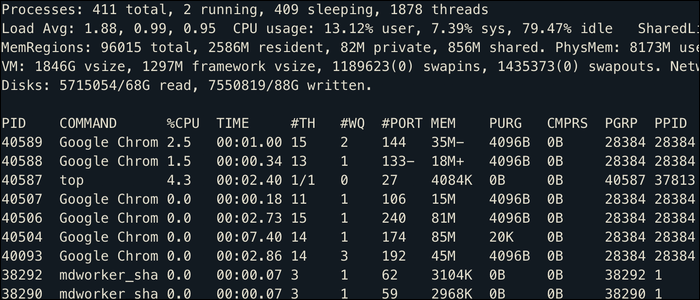
If you are running a Linux desktop, this also shows the applications that are running at the moment, even though most applications will be multi-threaded, hence Google Chrome populates this list running in multiple processes with different PIDs.
Stop processes
Being realistic, won't do much with the actual procedure other than shutting it down, since you will not have to manage the creation of the procedure. (Handled automatically when you run a command or script). The command to do that is called succinctly kill, which takes a given PID and closes that procedure:
sudo kill 40589
Additionally you can kill all processes with a given name using the killall command. As an example, to free up some RAM in your system, can execute:
sudo killall chrome
Evidently, this is not the best way to close desktop applications, but most processes will not generate much fuss if they are closed this way.
Despite this, if the procedure is a Linux service, you will want to use the service command to interact with it. As an example, reloading nginx:
service nginx reload
Or turn it off:
service nginx stop
PID files
A procedure ID only uniquely identifies a procedure while that procedure is running. If you have to restart Nginx, it is possible that a new procedure ID will be assigned to it.
This is where PID files come into play; they are a form of communication between processes, essentially a file that stores the current PID of a given procedure. Another procedure may read this file and inherently know, as an example, what is the PID of MySQL. When MySQL starts, write your own PID to this file for the whole system to see.
In general, PID files are stored in /var/run/, even though this is just common practice and not a requirement, similar to how log files are stored in /var/log/.
Most processes with PID files will also have one running at the same time, what is done with the help of lock files. Lock files are a way of determining a flag that only allows one procedure to start at the same time. When a procedure like Nginx is started, checks if the lock file exists and, If that is not the case, will start normally. But if it's already there, Nginx will throw an error and refuse to start.





