
Formats de colonne, comme Apache Parquet, offrent de grandes économies de compression et sont beaucoup plus faciles à numériser, traiter et analyser d'autres formats comme CSV. Dans ce billet, Nous vous montrons comment convertir vos données CSV en parquet à l'aide d'AWS Glue.
Qu'est-ce qu'un format en colonnes?
fichiers CSV, les fichiers journaux et tout autre fichier délimité par des caractères stockent efficacement les données dans des colonnes. Chaque ligne de données a un certain nombre de colonnes, tous séparés par le délimiteur, comme des virgules ou des espaces. Mais sous le capot, ces formats ne sont toujours que des lignes de chaîne. Il n'y a pas de moyen simple d'analyser une seule colonne d'un fichier CSV.
Cela peut être un obstacle avec des services comme AWS Athena, qui peut exécuter des requêtes SQL sur des données stockées dans CSV et d'autres fichiers délimités. Même si vous n'interrogez qu'une seule colonne, Athéna doit scanner le complet contenu du fichier. Le seul frais d'Athena est le Go de données traitées, donc augmenter la facture en traitant des données inutiles n'est pas la meilleure idée.
La réponse est un vrai format en colonnes. Les formats de colonne stockent les données dans des colonnes, au même titre qu'une base de données relationnelle traditionnelle. Les colonnes sont stockées ensemble et les données sont beaucoup plus homogènes, ce qui les rend plus faciles à compresser. Fils pas exactement lisible par l'homme, mais ils sont compris par l'application qui les traite sans problème. En réalité, car il y a moins de données à analyser, ils sont beaucoup plus faciles à traiter.
Parce qu'Athena n'a qu'à parcourir une colonne pour faire une sélection par colonne, réduit considérablement les coûts, en particulier pour les ensembles de données plus volumineux. Si tu as 10 colonnes dans chaque fichier et n'en numériser qu'une, cela signifie des économies de 90% juste en changeant pour Parquet.
Convertissez automatiquement avec AWS Glue
AWS Glue est un outil Amazon qui convertit les ensembles de données entre les formats. Utilisé principalement dans le cadre d'un pipeline pour traiter les données stockées dans des formats délimités et autres, et les injecte dans des bases de données pour une utilisation dans Athena. Bien qu'il puisse être configuré pour être automatique, vous pouvez également l'exécuter manuellement et, avec quelques ajustements, peut être utilisé pour convertir des fichiers CSV au format Parquet.
Accédez à la console AWS Glue et sélectionnez “Début”. Dans la barre latérale, cliquez sur “Ajouter un tracker” et créer un nouveau tracker. Le robot d'exploration est configuré pour rechercher des données à partir de Seaux S3et importer les données dans une base de données à utiliser pour la conversion.
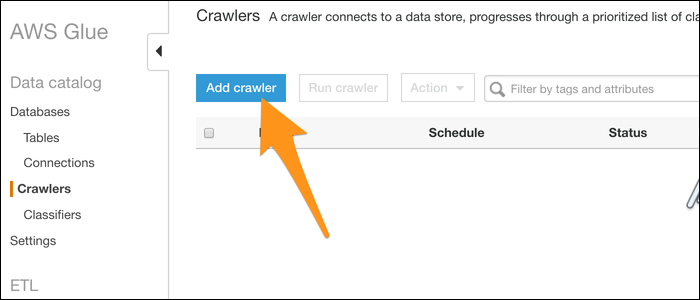
Nommez votre robot d'exploration et choisissez d'importer des données à partir d'un entrepôt de données. Sélectionnez S3 (même si DynamoDB est une autre alternative) et entrez le chemin d'accès à un dossier contenant vos fichiers. Si vous n'avez qu'un seul fichier que vous souhaitez convertir, le mettre dans son propre dossier.
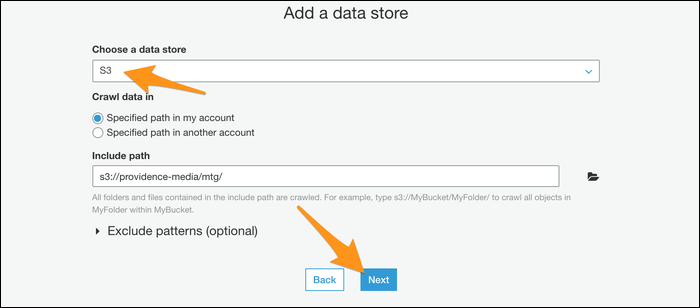
Ensuite, vous serez invité à créer un rôle IAM pour que votre robot fonctionne. Créez le rôle puis choisissez-le dans la liste. Vous devrez peut-être appuyer sur le bouton d'actualisation à côté pour qu'il apparaisse.
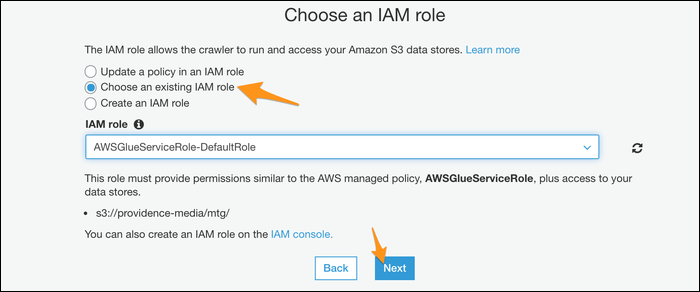
Choisissez une base de données pour la sortie du robot; Si vous avez déjà utilisé Athena, vous pouvez utiliser votre base de données personnalisée, mais sinon, la valeur par défaut devrait fonctionner correctement.
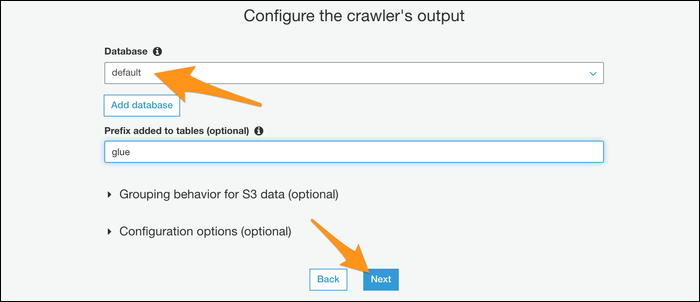
Si vous souhaitez automatiser la procédure, vous pouvez donner à votre tracker un programme pour qu'il s'exécute régulièrement. Si ce n'est pas comme ça, choisissez le mode manuel et exécutez-le vous-même depuis la console.
Une fois créé, allez-y et exécutez le robot pour importer les données dans la base de données que vous avez choisie. Si tout fonctionnait, vous devriez voir votre fichier importé avec le schéma approprié. Les types de données pour chaque colonne sont automatiquement attribués en fonction de l'entrée source.
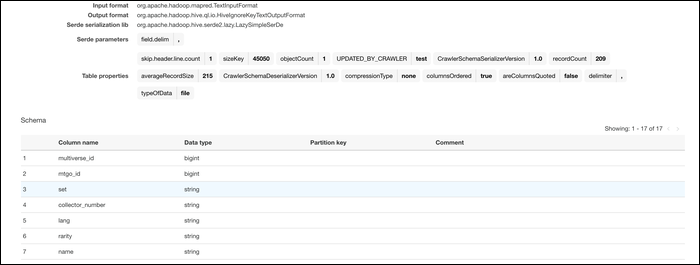
Une fois vos données dans le système AWS, peut les convertir. De la console de colle, passer à l'onglet “Usine” et créer un nouvel emploi. Donne lui un nom, ajoutez votre rôle IAM et sélectionnez “Un script d’initiative généré par AWS Glue” comme ce que la tâche est en cours d’exécution.
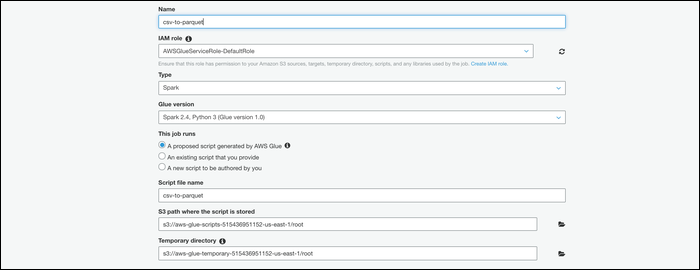
Sélectionnez votre table sur l'écran suivant, choisir plus tard “Changer de schéma” pour spécifier que ce travail exécute une conversion.

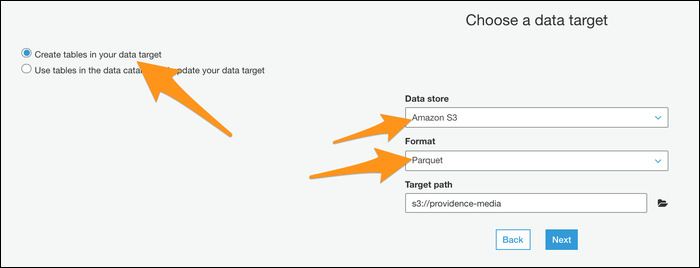
Ensuite, vous devez choisir “Créer des tables dans votre destination de données”, spécifiez Parquet comme format et entrez un nouveau chemin de destination. Assurez-vous qu'il s'agit d'un emplacement vide sans aucun autre fichier.
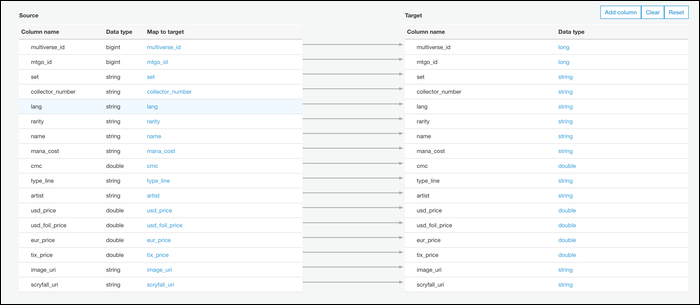
Ensuite, vous pouvez modifier votre schéma de fichier. Il s'agit par défaut d'un mappage un-à-un des colonnes CSV aux colonnes Parquet, c'est probablement ce que tu veux, mais vous pouvez le modifier si vous avez besoin.
Créez le travail et vous serez redirigé vers une page qui vous permet de modifier le script Python que vous exécutez. Le script par défaut devrait fonctionner correctement, par conséquent, appuyez sur “sauvegarder” et revenez à l’onglet Travaux.
Dans nos tests, le script échouait toujours à moins que le rôle IAM n'ait l'autorisation spécifique d'écrire à l'emplacement auquel nous avons spécifié la sortie. Vous devrez peut-être modifier manuellement les autorisations à partir du Console de gestion IAM si vous rencontrez le même problème.
Cas contraire, cliquez sur “Courir” et votre script devrait démarrer. La procédure peut prendre une minute ou deux, mais vous devriez voir l'état dans le panneau d'information. Quand j'aurai terminé, vous verrez un nouveau fichier créé dans S3.
Cette tâche peut être configurée pour s'exécuter en dehors des déclencheurs définis par le robot d'exploration important les données, ainsi toute la procédure peut être automatisée du début à la fin. Si vous importez les journaux du serveur vers S3 de cette façon, cela peut être une méthode simple pour les convertir dans un format plus utilisable.





